3. Teoria e gestione del Monitoraggio¶
Contenuti
Teoria e gestione del Monitoraggio
-
Eventi "Push" per monitoraggio passivo
-
3.1. Concetti di base del monitoraggio¶
3.1.1. Gerarchia del monitoraggio¶
Sanet organizza il monitoraggio in maniera gerarchica.
Il seguente schema mostra la relazione gerarchica delle diverse entita':
Tenant (Tenant)
Agenti (Agenti di monitoraggio)
Nodi ed elemenenti interni (interfacce, dischi, servizi, ecc.) ( Elementi Monitorabili (dagli agenti) )
Datagroup, datasource, condition e Timegraph. ( Raccolta dati e controlli )
![digraph sanetentities {
ximagepath="/opt/sanet3/static/webui/images/resources/";
node [fontsize="8"];
"tenant (site)" [ shape="box" ];
"agent (local)" [ shape="box" ];
"agent (remote)" [ shape="box" ];
"node1" [image="./source/_static/resources/node.png", shape=none, imagescale="true", fixedsize="true", width="1pt"];
"node2" [image="./source/_static/resources/node.png", shape=none, imagescale="true", fixedsize="true", width="1pt"];
"node3" [image="./source/_static/resources/node.png", shape=none, imagescale="true", fixedsize="true", width="1pt"];
interface [image="./source/_static/resources/iface.png" , shape=none, imagescale="true", fixedsize="true", width="1pt"];
storage [image="./source/_static/resources/storage.png", shape=none, imagescale="true", fixedsize="true", width="1pt"];
service [image="./source/_static/resources/service.png", shape=none, imagescale="true", fixedsize="true", width="1pt"];
device [image="./source/_static/resources/device.png" , shape=none, imagescale="true", fixedsize="true", width="1pt"];
subgraph datagroups {
datagroup2;
datagroup1;
}
"tenant (site)" -> "agent (local)";
"tenant (site)" -> "agent (remote)";
"agent (local)" -> "node1";
"agent (local)" -> "node2";
"agent (local)" -> "node3";
"node1" -> interface;
"node1" -> storage;
"node1" -> service;
"node1" -> device;
"node1" -> datagroup1;
datagroup1 -> datasource1;
datagroup1 -> condition1;
datagroup1 -> timegraph1;
interface -> "datagroup2";
datagroup2 -> datasource2;
datagroup2 -> condition2;
datagroup2 -> timegraph2;
}](../_images/graphviz-94c280ba6703c5a111848534ffc85c8b3debb4be.png)
3.1.2. Tenant¶
E' previsto che la stessa installazione di Sanet possa gestire una o piu' configurazioni di monitoraggio completamente distinte e indipendenti.
Un'intera configurazione di monitoraggio (nodi, interfacce, controlli, dati da raccogliere, ecc...) e' raggruppata logicamente in un Tenant.
Un tenant e' caratterizzato dalle seguenti informazioni di base:
Attributo
Descrizione
Nome
Nome identificativo del tenant. Deve essere univoco. Il nomer deve essere in LOWERCASE e puo' contenere soltanto lettere o numeri (dopo almeno un carattere alfabetico) .
Nome lungo
Nome "verboso" puramente descrittivo
Flag primario
Flag vero/falso.
All'interno della stessa installazione i tenant sono completamente indipendenti e non condividono nessuna informazione/configurazione tra di loro (fatta eccezione per alcuni template speciali di configurazione).
Important
Se si organizza il monitoraggio in tenant multipli e si ha necessita' di monitorare lo stesso host in due tenant, e' obbligatorio duplicare le configurazioni su tutti e due i tenant.
3.1.2.1. Tenant primario (flag)¶
Tra tutti i tenant definiti deve esistere sempre un tenant in particolare, detto primario.
Il tenant primario viene scelto automaticamente durante le operazioni di configurazione ed utilizzato per mostrare i dati di monitoraggio via web quando non diversamente indicato dall'utente.
Note
Sanet effettua tutti i controlli necessari affinche' esista sempre un tenant primario.
3.1.2.2. Tenant creato di default¶
In fase di installazione, Sanet crea automaticamente un tenant iniziale configurato come primario.
Se non specificato diversamente durante la fase di installazione il tenant verra' chiamato "site".
3.1.2.3. Rimozione di un tenant¶
Tramite i tool di amministrazione e' possibile rimuovere un tenant dal sistema.
Warning
La rimozione di un tenant non effettua realmente la cancellazione dei dati (ne' dal database ne' su disco). Per rimuovere definitivamente tutti i dati bisogna procedere "manualmente" (La procedura di rimozione dello "schema" non e' descritta in questa documentazione).
3.1.2.4. Configurazione¶
CLI: Vedere la sezione: Configurazione Tenant.
WEB: Vedere la sezione: Tenant.
3.1.3. Agenti di monitoraggio¶
Come spiegato nel paragrafo Architettura, gli agenti (chiamati anche poller) sono le entita' software (processi) che effettuano il monitoraggio della rete e comunicano i dati raccolti al server centrale di Sanet.
Per ogni tenant e' possibile configurare piu' di un agente di monitoraggio e distribuire il carico di lavoro tra i diversi agenti.
Gli agenti effettuano il monitoraggio delle entita' assegnate loro in maniera completamente autonoma dagli altri agenti e non condividono informazioni tra di loro.
La granularita' massima con cui e' possibile suddividere il monitoraggio tra agenti e' il nodo (Paragrafo Nodi)
Per monitorare un nodo attraverso un agente bisogna associare quel nodo all'agente.
E' possibile configurare il monitoraggio per far gestire ad un agente solo alcuni nodi (ad esempio solo gli switch di rete), ed ad un altro agente altri nodi (solo i database server).
Important
Non si puo' configurare esplicitamente e facilmente Sanet per monitorare parte di nodo con un agente e parte con un'altro (i controlli sulla RAM di un host con un agente e i controlli sui dischi con un altro agente).
3.1.3.1. Tipologie di agenti¶
- Esistono due tipi di agenti:
locali
remoti
3.1.3.1.1. Agenti locali¶
Gli agenti locali sono a tutti gli effetti processi che vengono eseguiti sul sistema (server) dove e' stato installato Sanet.
Warning
Il numero di agenti locali che e' possibile eseguire contemporaneamente sullo stesso sistema dipende dalle caratteristiche hardware/software della stessa.
3.1.3.1.2. Agenti remoti¶
Gli agenti remoti sono processi in esecuzione su macchine diverse (remote) da quella dove e' installato Sanet.
Danger
E' sconsigliato avere solo agenti remoti poiche' sono processi in esecuzione remotamente e potrebbero risentire indirettamente di problemi
La gestione degli agenti remoti prevede alcuni accorgimenti. Per tutti i dettagli si rimanda alla sezione dedicata: remote-agents.
3.1.3.2. Agente primario¶
Tra tutti gli agenti definiti in un tenant esiste sempre un agente primario.
Note
Tutti i nodi monitorati all'interno di un tenant, se non specificato esplicitamente, vengono assegnati automaticamente all'agente primario nel momento in cui vengono creati.
Warning
E' sconsigliato definire come primario un agente remoto. E' opportuno avere sempre almeno un agente locale definito come primario in maniera che eventuali problemi di rete non blocchino completamente il monitoraggio della rete.
3.1.3.3. Parametri di configurazione di un agente¶
La configurazione di un agente prevede diversi parametri. La modifica di alcuni di questi parametri richiede il riavvio dell'agente (locale o remoto)
Parametro
Descrizione
Richiede riavvio dell'agente
Flag primario
Si/No. Indica se l'agente e' l'agente primario del sistema.
Flag attivo
Si/No. Indica se l'agente e' attivo o se e' stato disabilitato dall'amministratore
si
Flag remoto
Si/No. Indica al sistema se l'agente e' considerato un agente locale/remoto.
si
Intervallo di update
Intervallo di update per in secondi prima di ricaricare la configurazione per effettuare il monitoraggio
si
Numero Threads
Numero di thread interni usati dall'agente per parallelizzare il monitoraggio
si
Warning
Gli agenti non attivi non effettuano alcun tipo di operazione. Il monitoraggio delle risorse associate a quell'agente e' completamente disabilitato.
3.1.3.3.1. Numero di thread¶
Tutti gli agenti effettuano il monitoraggio dei nodi assegnati loro cercando di parallelizzare i controlli da fare attraverso un thread pool di esecuzione.
CODA DI ATTESA THREAD POOL
+---> thread 1
|____________| |
controlli -----> _____________ ----+---> thread 2
| | |
+---> thread N
E' possibile indicare esplicitamente il numero di thread da utilizzare per ogni agente.
Per maggiori dettagli su come viene gestita la coda di attesa vedi il paragrafo Datagroup da eseguire e coda di esecuzione degli Agenti.
Note
Non si puo' controllare in che modo gli agenti internamente parallelizzano il lavoro, ma e' possibile obbligare un agente a rischedulare l'esecuzione di singoli controlli tramite appositi comandi (Comando: check_in).
Danger
Non c'e' alcun limite al numero di thread che e' possibile configurare per ogni agente, tuttavia la velocita'/prestazioni dell'agente non cresce linearmente col numero di thread. E' bene impostare un numero di thread non superiore a 40 per iniziare ed aumentare gradualemente il numero finche' le performance non sembrano subire un degrado.
3.1.3.4. Amministrazione agenti¶
Per amministrare ed interagire con gli agenti in esecuzione e' necessario usare appositi comandi. Si rimanda alla sezione Strumenti di amministrazione: agentinfo.
3.1.3.5. Configurazione agenti¶
CLI: si rimanda alla sezione: Configurazione Agenti.
WEB: si rimanda alla sezione: Agenti.
Poiche' gli agenti remoti prevedono una gestione/configurazione particolare, si rimanda alla sezione specifica: remote-agents.
3.1.4. Priorita' logica dei controlli e livelli di priorita'¶
Ad ogni elemento del monitoraggio e' associabile un livello di importanza chiamato priorita'.
La priorita' e' un valore numerico compreso tra 1 e 100 (compresi).
La priorita' non serve ai fini del monitoraggio, ma viene utilizzata per scopo informativi e per facilitare la consultazione dei dati (via web o cli).
Note
Quando un elemento di monitoraggio non ha una priorita' assegnata, si parla di priorita' nulla o N/A
Warning
Il sistema utilizza valore 0 per codificare l'assenza di priorita' (N/A), ma non e' lecito ritenere questo valore rimarra' tale in futuro. Non e' consigliato implementare script o integrare Sanet con altri software assumendo che la priorita' sia codificata con il valore 0.
3.1.4.1. Livelli di priorita'¶
All'interno di un tenant, la scala di priorita' da 1 a 100 puo' essere suddivisa logicamente in livelli (range) di priorita.
Ogni livello e' caratterizzato da:
Una etichetta (un nome).
Una descrizione.
I livelli non sono sovrapponibili/intersecabili tra loro.
Esempio:
Etichetta
Range
Descrizione
IGNORE
1-10
Allarme con priorita' bassa
NORMAL
11-30
Allarme
CRITICAL
31-90
Allarme da segnalare subito
FATAL
91-100
Problema critico per il sistema
Note
Questi "livelli" sono puramente informativi/descrittivi e non influenzano la gestione del monitoraggio. Possono eventualmente essere usati per facilitare la composizione di messaggi/allarmi.
3.1.4.2. Livelli di default¶
Se l'utente non configura dei livelli di priorita', Sanet crea di default i seguenti livelli:
Etichetta
Range
Descrizione
LOW
1 - 30
Priorita' bassa
MEDIUM
31 - 60
Priorita' media
CRITICAL
61 - 100
Priorita' critica
3.1.4.3. Configurazione¶
CLI: si rimanda alla sezione: Livelli priorita.
WEB: si rimanda alla sezione: Livelli di priorita e priorita' minima/critica.
3.1.5. Gestione reperibilita (on call)¶
Per alcuni tenant potrebbe essere necessario gestire il monitoraggio in "reperibilita" ("on call" o anche "H24").
Per sapere se deve essere gestita la reperibilita' per un tenant bisogna configurare il parametro "on-call".
Sono possibili 3 impostazioni:
Valore
Descrizione
no
Non e' prevista gestione in reperibilita'
yes
Gestione reperibilita' attiva
disabled
Gestione reperibilita' attiva ma temporanamente disabilitata.
Quando i flag on-call e' impostato a disabled, l'interfaccia WEB segnala questa situazione.
Note
Le modifiche alla configurazione del parametro on-call vengono salvate nell'audit.
Attention
Quando il flag vale "disabled", eventuali configurazioni presenti e valide per la reperibilita' vengono ignotate. ( Vedi: Flag sulle regole)
Warning
Quando il flag vale "no", eventuali configurazioni/funzionalita' presenti e valide per la reperibilita' verranno ignorate con segnalazioni di errore. ( Vedi: Flag sulle regole)
3.1.6. Elementi Monitorabili (dagli agenti)¶
Esistono 5 tipologie di elementi che possono essere monitorati:
3.1.6.1. Nomi degli elementi¶
Tutti gli elementi di monitoraggio sono caratterizzati da un nome:
Il nome dei nodi e' univoco all'interno dello stesso tenant.
Il nome di interfacce/storage/service/device e' univoco all'interno dello stesso nodo. Due interfacce/dischi/device/ecc. non possono avere lo stesso nome all'interno dello stesso nodo. (es: eth0, root-disk, ecc.)
Warning
il nome di un elemento puo' contenere SOLO un set di caratteri ben definito e deve rispettare il formato espresso dalla seguente espressione regolare:
^[a-zA-Z0-9]+([-.][a-zA-Z0-9]+)*$
3.1.6.2. Quali entita' definire e monitorare¶
E' bene tenere presente che, tecnicamente, e' possibile definire un nodo e monitorare tutte le sue componenti interne (dischi/interfacce/ecc.) senza definirle esplicitamente nel monitoraggio.
Note
In pratica si definisce solo il nodo e si definisce almeno un controllo puntuale per ogni sotto elemento del nodo (Esempio: un controllo sul'interfaccia eth0, un controllo sul disco, ecc.)
Questo approccio e' fortemente sconsigliato.
Note
Questo e' anche il sistema utilizzato da altri sistemi di monitoraggio (Esempio: Nagios).
Il consiglio per chi usa Sanet e' cercare di inserire nel sistema una configurazione granulare, esplicitando quando possibile, e compatibilmente con le proprie esigenze, tutte le entita' monitorate per i seguenti motivi:
Tutte le entita' (nodi/interfacce/ecc.) sono caratterizzate da attributi specifici (e parametrizzabili) pensati per razionalizzare il piu' possibile la configurazione.
La definizione dei dati da raccogliere e dei controlli da eseguire su ogni entita' monitorata risulta piu' comprensibili e modulare.
E' piu' facile consultare i dati raccolti.
3.1.6.3. Nodi¶
I nodi sono l'elemento principale di monitoraggio in Sanet.
Qualunque elemento sulla rete in grado di comunicare/rispondere tramite uno o piu' protocolli di rete (piu' o meno standard) e' classificabile logicamente come un nodo. Alcuni esempi di elementi di rete che e' possibile consideare come nodi in Sanet:
PC e server di rete (reali o virtuali)
switch, router, firewall
NAS
UPS
Tablet/Cellulari
Raspberry Pi
ecc.
Note
Anche un processo in esecuzione su un server (apache) risponde a protocolli di rete, ma in questo caso si tratta di un entita' software in esecuzione (su quello che si puo' considerare come nodo) e per tanto dovrebbe essere monitorato attraverso un'apposita entita' in Sanet (un service).
Note
I nodi sono le uniche entita' del monitoraggio che possono contenere altre entita' (dischi, interfacce, ecc.), ma non altri nodi.
Important
non e' possibile configuarare esplicitamente alcune situazioni particolari. Ad esempio non si riesce ad esplicitare la relazione che esiste tra un server di virtualizzazione (nodo) e le macchine virtuali (nodi) che contiene.
Per i dettagli sui parametri di configurazione/monitoraggio si rimanda a: Monitoraggio dei nodi.
3.1.6.4. Interfacce¶
L'entita' interfaccia rappresenta un'interfaccia (fisica o virtuale) presente su un nodo di rete.
Le interfacce vengono definite all'interno dei nodi (sono sotto-entita' di un nodo) e sono identificate da un nome che deve essere univoco all'interno del nodo (es: eth0).
Per i dettagli sui parametri di configurazione/monitoraggio si rimanda a: Monitoraggio dei interfacce.
3.1.6.4.1. Interfacce e ifindex¶
L' ifindex di una interfaccia e' un valore (utilizzato principalmente nel protocollo SNMP) che serve per identificare dinamicamente un'interfaccia all'interno di un apparato di rete.
Sanet supporta un meccanismo per scoprire automaticamente questo valore e semplificare la scrittura di controlli basati sull'ifindex. Si rimanda alla sezione: Attributi Distinguisher, xform e valore ifIndex;
Important
Normalmente l'ifindex e' un valore numerico, ma (purtroppo) esistono casi reali in cui non e' cosi e per tanto Sanet gestisce l'ifindex come stringa.
3.1.6.5. Storage¶
Questa entita' rappresenta genericamente uno storage all'interno di un nodo di rete:
memoria RAM
memoria ROM
hardisk,
memorie USB
partizione montata via rete
ecc.
Gli storage vengono definiti all'interno dei nodi (sono sotto-entita' di un nodo) e sono identificati da un nome che deve essere univoco all'interno del nodo (es: root, C, netshared).
Per i dettagli sui parametri di configurazione/monitoraggio si rimanda a: Monitoraggio degli storage.
3.1.6.5.1. Storage e stindex¶
L' stindex di uno storage e' un valore (utilizzato nel protocollo SNMP) che serve per identificare dinamicamente uno storage all'interno di un apparato di rete.
Sanet supporta un meccanismo per scoprire automaticamente questo valore e semplificare la scrittura di controlli basati sull'stindex. Si rimanda alla sezione: Attributi Distinguisher, xform e valore stIndex;
Important
Normalmente l'stindex e' un valore numerico, ma (purtroppo) esistono casi reali in cui non e' cosi e per tanto Sanet gestisce l'stindex come stringa.
3.1.6.6. Servizi¶
Questa entita' serve per rappresentare nel monitoraggio qualunque entita' software, univocamente identificabile, presente (non necessariamente in esecuzione costante) su un nodo di rete.
script BATCH per la produzione di dati.
demoni di rete (inetd, apache, postfix, syslogd, ecc.).
DB Manager.
Broker di rete.
Processi utente in esecuzione sulla macchina.
Genericamente qualunque entita' software composta da uno o piu' programmi/script.
I servizi vengono definiti all'interno dei nodi (sono sotto-entita' di un nodo) e sono identificati da un nome che deve essere univoco all'interno del nodo (es: apache, mysql, oracle, squid, ecc.).
Note
Il termine "servizio" e' molto generico. Potrebbe trarre in inganno e far pensare che tramite una entita' servizio si debba monitorare SOLO dei servizi complessi come "la posta" o lo "streaming video".
In realta' un servizio di posta completo coinvolge molte entita' monitorabili (server POP, server IMAP, server SMTP, sistemi di storage, processi di logging, ecc...).
Spetta all'amministratore di Sanet decidere come sfruttare le risorse di tipo servizio di Sanet, quale sia il loro effettivo significato e quali sono effettivamente le entita' reali sulla rete associate al quel servizio.
Per i dettagli sui parametri di configurazione/monitoraggio si rimanda a: Monitoraggio dei servizi.
3.1.6.6.1. Servizi e swrunindex¶
L' SwRunIndex e' un valore (utilizzato nel protocollo SNMP) che serve per identificare dinamicamente un processo in esecuzione su un server di rete che risponde a richieste SNMP.
Sanet supporta un meccanismo per scoprire automaticamente questo valore e semplificare la scrittura di controlli basati sull'SwRunIndex. Si rimanda alla sezione: Attributi Distinguisher, xform e valore swRunIndex;
Important
Normalmente l'SwRunIndex e' un valore numerico, ma (purtroppo) esistono casi reali in cui non e' cosi e per tanto Sanet gestisce l'SwRunIndex come stringa.
3.1.6.7. Dispositivi generici (device)¶
Qualunque dispositivo hardware presente all'interno di un server o apparato di rete, univocamente identificabile e monitorabile (attraverso protocolli di comunicazione o attraverso programmi esterni) e' potenzialmente classificabile come device.
Alcuni esempio:
Sensori (di qualunque tipo)
Hardware interno (CPU, ventole, moduli, ecc..)
Hardware esterno (es: Webcam attaccato tramite presa USB)
In Sanet gli elementi di tipo dispositivo (device) vengono definiti all'interno dei nodi (sono sotto-entita' di un nodo) e sono identificati da un nome che deve essere univoco all'interno del nodo (es: fan0, usb-card-reader, printer1, ecc.).
Per i dettagli sui parametri di configurazione/monitoraggio si rimanda a: Monitoraggio di device generici.
3.1.6.7.1. Device e devindex¶
Alcuni apparati di rete espongono (via SNMP o altri protocolli) informazioni su dispositivi interni e spesso li identificano attraverso un valore univoco (tipicamente numerico).
Questo valore viene chiamato in Sanet devindex.
Sanet supporta meccanismo analoga a quello per il calcolo di ifindex, stindiex, ecc. per scoprire automaticamente il valore di devindex. Si rimanda alla sezione: Attributi Distinguisher, xform e valore swRunIndex;
3.1.6.8. Link tra interfacce¶
Un link rappresenta e' un collegamento tra due interfacce. Tra due interfacce e' possibile definire piu' link.
Esistono 3 tipi di link:
Tipo
Descrizione
Fisico
Rappresenta un collegamento tra due interfacce tramite cavi/fibre.
Rete
Rappresenta un collegamento non fisico.
Virtuale
Codifica un collegamento puramente virtuale definito per permettere controlli particolari in fase monitoraggio delle interfacce coinvolte.
Note
La differenza tra un link di "rete" e un link virtuale e' che col primo si vuole identificare collegamenti tra interfacce che esistono ad un certo livello dello stack ISO/OSI, mentre il link virtuale e' un'astrazione che potrebbe anche essere puramente logica e utile solo per esigenze di monitoraggio.
Attention
In Sanet puo' essere definito un solo link fisico tra due interfacce, mentre possono essere definiti un numero arbitrario di link di rete o virtuali.
Attention
Il monitoraggio delle interfacce si basa esclusivamente (per il momento) sui link fisici. Link di rete e Virtuali sono ignorati al momento e non e' possibile utilizzarli in nessun modo per implementare controlli specifici.
3.1.6.8.1. Nome di un link¶
Un link e' caratterizzato da un nome "univoco". Se non specificato, il sistema assegna automaticamente ai link un nome univoco componendolo a partire dai nodi/interfacce che coinvolge.
Per i dettagli sui parametri di configurazione/monitoraggio si rimanda a: Link tra nodi/interfacce.
3.1.7. Raccolta dati e controlli¶
3.1.7.1. Retention¶
Sanet assume che i dati di monitoraggio abbiano una retention teorica massima espressa in giorni.
La retention e' configurabile da file di configurazione (settings.py)
DATA_RETENTION_MAX_DAYS = 365
Lo spazio disco rischiesto per salvare i dati delle serie storiche (I Datasource) e log di monitoraggio e' direttamente proporzionale a questo parametro.
Attention
E' necessario riavviare Sanet (il server centrale) se si modifica questo valore, o le modifiche alla retention non avranno effetto.
Warning
la retention di serie storiche (I Datasource) gia' salvate non viene alterata con successive modifiche di DATA_RETENTION_MAX_DAYS. Solo le serie storiche "create" dopo la modifica di DATA_RETENTION_MAX_DAYS avranno la retention attesa. Per le serie create precedentemente alla modifica bisogna intervenire manualmente sui dati salvati su disco con procedure non descritte in questa documentazione.
La rimozione dei dati piu' vecchi della retention imposta e' manuale e deve essere eseguita con comandi appositi. Si veda remove_old_logs.
3.1.7.2. Datagroup¶
3.1.7.2.1. Cos'e' un datagroup¶
Per ogni entita' monitorabile e' necessario raccogliere dati logicamente collegati tra di loro e definire controlli su di essi. Ad esempio:
CPU: Load average e percentuale di occupazione
DISCO: spazio utilizzato/spazio totale
TRAFFICO: traffico IN unicast/multicast/broadcast, traffico OUT unicast/multicast/broadcast.
Servizio Email: numero email inviate/ricevute, percentuale di spam, ecc.
Sensore di temperature: temperatura registrata in gradi.
Un gruppo di informazioni/controlli da monitorare insieme in un dato momento e' rappresentato da un Datagroup.
Un datagroup codifica:
Quali dati raccogliere dalla rete e come raccoglierli.
Quali controlli effettuare sui dati raccolti.
Con quale frequenza effettuare queste operazioni.
3.1.7.2.2. Come definire un datagroup¶
Per definire le varie parti di un datagroup, Sanet utilizza un sistema di configurazione basato su template chiamato datagroup template (che specifica il datagroup in ogni sua parte).
Ad ogni elemento del monitoraggio (nodo, interfaccia,ecc.) e' possibile associare zero o piu' datagroup template e questa associazione crea i datagroup.
Per i dettagli sul meccanismo di templating usato da Sanet si rimanda alla sezione dedicata: Template di Configurazione.
3.1.7.2.3. Gestione dei datagroup a parte degli agenti: Esecuzione¶
Il datagroup e' l'entita' atomica che gli agenti processano per effettuare le operazioni di rete.
Gli agenti periodicamente:
caricano dal server centrale tutte le informazioni sulle entita' da monitorare.
caricano dal server centrale tutti i datagroup associati alle entita' da monitorare.
A intevalli regolari, utilizzano le informazioni contenute di ogni singolo datagroup per effettuare i controlli di rete e inviare i dati raccolti al server centrale.
Quando un agente decide di usare un datagroup per effettuare le operazioni di monitoraggio si dice che l'agente ESEGUE UN DATAGROUP.
3.1.7.2.4. Attributi di un datagroup e sotto-elementi di configurazione¶
Un datagroup possiede diversi attributi (opzioni di configurazione). Questa tabella riassume gli attributi specifici del datagroup:
Attributo
Modificabile
Opzionale
Default
Descrizione
path
no
no
Stringa mnemonica generata automaticamente dal sistema
titolo
si
si
Titolo che compare nelle descrizioni e nell'interfaccia web.
minperiod
si
si
60
Pausa (in secondi) tra due esecuzioni dello stesso datagroup.
timeout
si
si
3
Timeout di default (in secondi) utilizzato per effettuare le operazioni di rete.
shorttries
si
si
5
Valore di default che indica il numero di tenatativi per effettuare una certa operazione di rete nel datagroup (un GET SNMP, un ping, ecc.)
classification
si
si
Stringa mnemnoica per cataloga il tipo di datagroup
dependson
si
si
Stringa che codifica la catena di dipendenza del datagroup
passive match
si
si
Stringa per identificare un datagroup in un un controllo passivo Vedi Datagroup Passivi
passive_period
si
si
Periodo di esecuzione passiva forzata. Vedi Datagroup Passivi
Un datagroup e' composto da i seguenti sotto-elementi:
Tipo
Descrivono i dati che si vogliono raccogliere dalla rete, come devono essere raccolti e come devono essere salvati nel sistema.
Parametri
Variabili opzionali utilizzabili per rendere parametrizzabile la valutazioni di Datasource e Condition.
Datasource
Descrivono i dati che si vogliono raccogliere dalla rete, come devono essere raccolti e come devono essere salvati nel sistema.
Condition
Condizioni da verificare. Ogni condition e' caratterizzata da diversi attributi che descrivono il controllo da eseguire.
Timegraph
Definizione per visualizzare grafici temporali dei dati raccolti (e storicizzati) dai DataSource.
3.1.7.2.4.1. Esempi di dati (datasource) e condizioni (condition)¶
- La raggiungibilita' calcolata attraverso protocollo ICMP puo' essere monitorata definendo un datagroup con:
4 datasource: rttmin, rrtmax, rttavg, pktloss (in percentuale)
1 condition: pktloss < 100%
- Il datagroup con tutte le informazioni STP di un'interfaccia potrebbe contenere:
1 datasource: numero transizioni di stato corrente
1 condition: varizione sul numero di transizioni rilevate rispetto al
1 condition: verifica adiacenza STP con l'interfaccia collegata
3.1.7.2.4.2. Titolo¶
Il titolo e' una stringa descrittiva che viene visualizzata dall'interfaccia web.
E' possibile utilizzare numerose variabili/wildcard per espandere automaticamente nel testo del titolo alcune informazioni sull'entita' monitorata collegata al datagroup.
Tutte le variabili utilizzabili hanno come prefisso il carattere '$'.
L'elenco effettivo di variabili valide dipende dal tipo di risorsa (nodo, interfaccia, ecc.) a cui sara' associato il datagroup.
Variabili usabili nel titolo di un datagroup/condition/datasource associato ad un nodo:
$node
nome del nodo
$snmpversion
snmp version del nodo
$community
snmp community del nodo
Tutti i parametri opzionali con $*parametro*
Es. $threshold
Variabili usabili nel titolo di un datagroup/condition/datasource associato ad una interfaccia:
Variabile
Descrizione
$node
nome del nodo
$snmpversion
snmp version del nodo
$community
snmp community del nodo
$iface
nome dell'interfaccia
$instance
distinguisher dell'interfaccia
$linked_iface
(interfaccia collegata con un link fisico)
$linked_node
(nodo dell'interfaccia collegata con un link fisico)
Tutti i parametri opzionali con $*parametro*
Es. $threshold
Variabili usabili nel titolo di un datagroup/condition/datasource associato ad uno Storage:
Variabile
Descrizione
Variabile
Descrizione
$node
nome del nodo
$snmpversion
snmp version del nodo
$community
snmp community del nodo
$storage
nome dello storage
$instance
distinguisher dello storage
Tutti i parametri opzionali con $*parametro*
Es. $threshold
Variabili usabili nel titolo di un datagroup/condition/datasource associato ad un Service:
Variabile
Descrizione
$node
nome del nodo
$snmpversion
snmp version del nodo
$community
snmp community del nodo
$service
nome del servizio
$distinguisher
distinguisher del servizio
Tutti i parametri opzionali con $*parametro*
Es. $threshold
Variabili usabili nel titolo di un datagroup/condition/datasource associato ad un Device:
Variabile
Descrizione
$node
nome del nodo
$snmpversion
snmp version del nodo
$community
snmp community del nodo
$device
nome del device
$distinguisher
distinguisher del device
Tutti i parametri opzionali con $*parametro*
Es. $threshold
3.1.7.2.4.3. Path¶
Un datagroup (e anche i suoi datagroup/datasource) e' identificato univocamente all'interno del tenant da una stringa chiamata path.
Il path* condifica implicitamente informazioni su:
l'elemento (nodo) ed eventualmente il sotto-elemento (interfaccia,storage,service,device) a cui e' associato.
element-template di configurazione (si veda: Template di Configurazione);
nome del datagroup
nome datasource o nome della condition (per i path di datasource e condition).
La sintassi del path e' la seguente:
Path Datagroup
<nome nodo> [ : <nome sub elemento> ] ; [ < element-template > ; ] <nome datagroup>
Path Datasource
<nome nodo> [ : <nome sub elemento> ] ; [ < element-template > ; ] <nome datagroup> : <nome datasource>
Path Condition
<nome nodo> [ : <nome sub elemento> ] ; [ < element-template > ; ] <nome datagroup> : <nome condition>
Esempi:
localhost;;icmp-reachability PATH datagroup localhost:eth0;;iface-data:iferrs PATH datasource
Warning
il path e' una stringa che dovrebbe restare opaca per l'utente e per software esterni. E' preferibile evitare di basarsi su porzioni parziali del path per implementare elaborazioni ad hoc.
3.1.7.2.4.4. Periodicita' dei controlli (minperiod) e scheduling¶
Ogni datagroup viene eseguito ad intervalli regolari.
L'intervallo di tempo MINIMO tra un'esecuzione e l'altra e' chiamato minperiod e viene espresso in secondi.
Il valore di default per il minperiod e' 60 secondi.
Attention
Il range di valori ammessi e' compreso tra 0 to 32767 secondi, pari circa a 9 ore.
E' possibile configurare Sanet per gestire uno scheduling piu' sofisticato, e non solo basato sul minperiod. Si veda la sezione Scheduling avanzato: gestione di Scheduling Group.
Se il minperiod e' valorizzato a 0, il datagroup viene definito passivo e non viene mai schedulato/eseguito dagli agenti di monitoraggio (locali o remoti).
Per una spiegazione dettagliata si rimanda alla sezione Datagroup Passivi.
Piu' il minperiod e' basso, piu' e' alta la frequenza con cui viene eseguito un datagroup.
Il carico di elaborazione per il sistema e' direttamente proporzionale alla numero totale di datagroup ed alla loro frequenza di esecuzione.
Attention
Il sistema non impedisce di mettere minperiod piu' bassi di 60 secondi, tuttavia e' altamente sconsigliato scendere sotto i 15 secondi.
E' possibile configurare Sanet per gestire uno scheduling piu' sofisticato, e non solo basato sul minperiod. Si veda la sezione XXXXXXXXXXXXXXXXXXXX.
3.1.7.2.4.5. Timeout delle operazioni (timeout)¶
Nel 90% dei casi un datagroup deve raccogliere dati dalla rete. Per evitare di attendere indefinitivamente il completamento di una operazione (es: un ping) ogni datagroup puo' specificare un valore di timeout in secondi.
Il valore specificato viene considerato come il timeout di default del datagroup. Ogni singola operazione eseguita dal datagroup puo' decidere se utilizzare questo valore, ignorarlo o utilizzare questo dato per calcolare un timeout diverso.
Il default e' 5 secondi.
Attention
non tutte le funzioni/operazioni eseguibili da sanet tengono conto di questo valore.
3.1.7.2.4.6. Numero di tenativi per operazione (shorttries)¶
Per ogni datagroup si puo' specificare quante volte "tentare" una singola operazione di raccolta dati (es: un ping, un GET SNMP, una connect). Questo valore e' chiamato shorttries.
Il valore di default e' 3.
Attention
non tutte le funzioni/operazioni eseguibili da sanet tengono conto di questo valore.
3.1.7.2.4.7. Classificazione di datagroup/datasource/condition (classification)¶
Due o piu' datagroup diversi potrebbero raccogliere dati logicamente simili.
Due o piu' datasource potrebbero raccogliere lo stesso dato, ma con meccanismi diversi.
Due o piu' condition potrebbero effettuare lo stesso controllo logico, ma con parametri diversi.
Ad esempio, due datagroup progettati per effettuare il controllo della memoria possono avere nomi diversi, ma effettuare logicamente lo stesso tipo di operazioni.
Per poter confrontare in maniera automatica i valori che vengono raccolti dai datasource, i controlli effettuati dalle condition e gli eventuali allarmi che seguono e' necessario introdurre il concetto di classificazione.
La classificazione serve per idenditificare il contenuto semantico dei dati del monitoraggio.
La classificazione e' una stringa mnemonica abitraria che si puo' specificare per ogni datagroup/datasource/condition.
Anche se non formalmente obbligatorio, una classificazione e' definita da una stringa di caratteri composta da "token" separati da ".".
Ogni "token" e' una stringa che codifica il nome di un nodo all'interno di uno namespace gerarchico.
Esempi di stringhe di classificazione:
servizi.principali.posta servizi.secondari.marcatempo rete.apparati.switch rete.apparati.switch. rete.apparati.router.hp rete.apparati.router.cisco rete.apparati.wireless.accesspoint
Concettualmente, la classificazione e' logicamente gerarchica ed e' rappresentabile con un albero. Il meccanismo di codifica e' virtualmente analogo a quello delle OID (o dei package java, dei namespace C#, ecc.).
Si rimanda alle appendici Classificazioni per avere un elenco delle classificazioni possibili gia' utilizzabili internamente per i controlli base di Sanet3.
Attention
datagroup, condition e datasource sono tutti classificati indipendentemente. Non esiste nessun meccanismo automatico di assegnamento di classificazioni.
3.1.7.2.5. Dipendenze tra datagroup (dependson)¶
Il sistema permette di definire relazioni di dipendenza tra datagroup. Questo permette di eseguire un particolare datagroup solo se la valutazione della condition di un altro datagroup e' avvenuta con successo.
- Esempio: il datagroup per la raccolta dei dati relativi al servizio web "Apache" in esecuzione sul nodo "server1", deve essere eseguito solo se la condizione
che verifica la raggiungibilita ICMP (contenuta in un datagroup che raccoglie dati sulla raggiungibilita' ICMP) del nodo ha verificato che il nodo sia effettivamente raggiungibile via rete.
La gestione delle dipendenze e' gestita in automatico dal sistema, ma e' possibile intervenire manualmente.
Si rimanda alla sezione Condition primary e dependson per maggiori dettagli.
3.1.7.2.6. I Datasource¶
Un datasource rappresenta il singolo dato di interesse per il monitoraggio raccolto/calcolato analizzando lo stato di un componente della rete.
Il valore calcolato da un datasource puo' essere:
numerico (intero o virgola mobile)
stringa di caratteri ascii o byte
valore complesso
Il valore calcolato da un datasource puo' essere storicizzato da Sanet.
Important
il valore calcolato per un datasource viene storicizzato SOLO se numerico (intero o in virgola mobile).
Il valore di un datasource puo' essere:
raccolto singolarmente (un singolo valore raccolto via SNMP)
essere il risultato di un'aggregazione di piu' valori raccolti (es: a + b + c) e/o di altri datasource (dello stesso datagroup) calcolati/raccolti (immediatamente) prima di lui.
Proprieta' di un datasource:
Dato
Opzionale
Default
Descrizione
expr
si
Espressione da valutare che indica come raccogliere/calcoalre il valore. Vedi Espressione e valore di un datasource.
min val
si
Valore minimo consentito. Questa propieta' non altera il dato raccolto, ma serve per fornire indicazioni sulla validita' o meno del dato raccolto.
max val
si
Valore massimo consentito. Questa propieta' non altera il dato raccolto, ma serve per fornire indicazioni sulla validita' o meno del dato raccolto.
absolute value
si
si
Flag SI/NO. Vedi Tipi di datasource: GAUGE o RATE (COUNTER).
save value
si
si
Indica se il valore calcolato deve essere salvato dal sistema o se scartato al termine dell'elaborzione del datagroup.
order
si
Ordine di valutazione del datasource rispetto agli altri. Default 0. Vedi Ordine di valutazione di datasource e condition.
cascade
si
no
(flag si/no) Indica se, in caso di errore nella valutazione, i datasource successivi devono essere valutati o meno. (default no)
classification
si
Stringa di classificazione
storage-spec
si
Attributo per specificare parametri di configurazioni specifici del backend di storicizzazione dei dati. Vedi DataSource Storage Backends.
passive_force_value
si
Espressione calcolata quando il datasource viene forzato passivamente. Si rimanda a Datagroup Passivi.
Note
se order non viene specificato tutti i datasource hanno lo stesso ordine e per tanto non e' predicibile quale venga processato dal sistema per primo.
Note
i valori di un datasource non compresi nel range ( min_val <= x <= max_val ) possono alterare lo stato di un datasource. Si veda Stato di un datasource.
3.1.7.2.6.1. Tipi di datasource: GAUGE o RATE (COUNTER)¶
Il parametro absolute value serve per indicare in che modo salvare e storicizzare il valore di un datasource.
I due valori possibili sono:
SI: il valore raccolto viene storicizzato come valore puntuale. Si parla in questo caso di valore GAUGE.
NO: il valore raccolto viene storicizzato sotto forma di rate al secondo. Il sistema effettua automaticamente il calcolo del delta tra il valore corrente del datasource e il valore precedentemente calcolato. Si parla in questo caso di valore COUNTER.
Esempi di dati da raccogliere e quale tipo di datasource usare:
Dato
Natura del dato
absolute value
numero utenti loggati
valore puntuale
si
spazio disco occupato e spazio disco totale
valore puntuale
si
Rtt min, max, avg, % packet loss
valore puntuale
si
CPU %, Load Average
valore puntuale
si
Traffico interfaccia (bit/s)
rate
no
STP Topology change/s
rate
no
Note
i termini GAUGE e COUNTER sono mutuati dal RRDTools. Per convenzione Sanet utilizza la stessa terminologia.
Important
il parametro absolute value altera significativamente le strutture dati utilizzate per storicizzare i dati su disco. Una volta che il sistema ha iniziato a raccogliere i dati di un datasource, ogni modifica al parametro absolute value e' possibile, ma non produce alcun effetto nel sistema. Sono possibili alcune operazioni sui dati salvati di un datasource per "resettare" un datasource dopo modifiche al valore absolute value, ma fortemente sconsigliata.
3.1.7.2.6.2. Espressione e valore di un datasource¶
Il valore raccolto da un datasource viene calcolato valutando l'espressione (expr) associata al datasource.
L'espressione deve essere definita utilizzando un particolare linguaggio funzionale. In questo linguaggio si possono funzioni e variabili ricalcolate da Sanet ad ogni esecuzione dell'espressione.
Si rimanda alla sezioni Expression Language e SANET built-in expression symbols per maggiori dettagli sulla sintassi del linguaggio utilizzato dall'espressione.
Per altri dettagli sulla valutazione della expr si rimanda alla sezione Regole di valutazione di Datasource e Condition.
3.1.7.2.6.3. Precisione dei dati storicizzati¶
I dati storicizzati per ogni datasource vengono processati prima di essere memorizzati/storicizzati da Sanet.
Note
attualemente i dati vengono storicizzati tramite RRDTools, quindi file RRD.
Questo implica due cose:
Esiste un lieve margine di approssimazione tra i dati raccolti e quelli effettivamente storicizzati da Sanet.
Lo scostamento tra i dati raccolti e quelli effettivamente mostrati da Sanet e' piu' evidente per datasource GAUGE, mentre lo e' meno per i datasource rate/COUNTER.
3.1.7.2.6.4. Modalita' di calcolo del rate attuale¶
Per rate attuale si intende l'ultimo rate calcolato da Sanet per un datasource COUNTER.
Sanet mantiene due valori di rate attuale:
rate istantaneo : Calcolato dagli agenti di monitoraggio in fase di raccolta dei dati. Questo valore e' piu' grezzo.
rate storicizzato: Calcolato da sanet in fase di storicizzazione del dato nel database. Questo valore tende ad essere piu' mediato e quindi puo' nascondere anomalie (picchi nel rate) in alcuni casi.
Warning
Questi due valori sono SEMPRE DIVERSI e non e' predicibile lo scostamento che potrebbero avere.
Warning
nei grafici mostrati da interfaccia Web viene sempre mostrato il rate storicizzato. Il rate istantaneo viene mostrato solo in alcune sezioni dell'interfaccia, per completezza.
3.1.7.2.6.5. Stato di un datasource¶
Dopo che un datasource viene eseguito, il sistema calcola uno stato che rappresenta l'esisto della valutazione. Questi sono gli stati possibili:
STATO
Descrizione
OK
Il valore e' stato calcolato correttamente.
STRANGE VAL
Il valore attuale (puntuale o rate al secondo) del datasource non rispetta il range (min_val, max_val) indicato in configurazione.
CASCADE
Il valor non e' stato calcolato poiche' un datasource calcolato prima di questo ha dato errore bloccando l'esecuzione dei successivi. Vedi Ordine di valutazione di datasource e condition.
DEPENDSON
Tutto il datagroup associato non e' stato calcolato perche' dipende da una condition non verificata. Vedi Ordine di valutazione di datasource e condition.
UNCHECKABLE
Il valore del datasource non e' stato calcolato correttamente per un errore rilevato durante la raccolta dei dati
3.1.7.2.6.6. Datasource con valori fuori range (STRANGE VAL) e storicizzazione¶
Quando un datasource e' in stato STRANGE VAL significa che:
Il valore letto dalla rete non e' numerico. In questo caso il dato non viene storicizzato.
Il valore letto e' fuori dal range min val / max val. In questo caso il dato viene storicizzato, ma in fase di estrazione, il dato viene scartato e considerato nullo.
3.1.7.2.7. Le Condition¶
Rappresenta il controllo puntuale di una condizione (invariante), effettuato sui dati raccolti dalla rete.
I dati raccolti possono essere valori calcolati dai datasource o raccolti direttamente dalla rete.
Una condition e' caratterizzata dai seguenti attributi:
Parametri informativi
Dato
Opzionale
Default
Descrizione
classification
si
Classificazione
priorita'
si
n/a
Livello di proprita' di questa condizione.
Parametri di Valutazione
Dato
Opzionale
Default
Descrizione
expr
si
Espressione da valutare per la verifica della condizione
max tries
si
3
numero di check da ripetere prima di considearre la condizione come non verificata
primary
si
no
Flag per identificare una condition come primaria. Si veda Condition primary e dependson.
dependson
si
La valutazione di questa condizione e' subordinata alla condition specificata.
order
si
0
Specifica l'ordine di esecuzione delle condition all'interno del datagroup. Subordinato al flag "primary".
cascade
si
no
Se la condition non e' verificata, tutte le condition valutate successivamente non vengono eseguite.
uncheckable-fallback
si
"UP" o "DN". Indica se considerare verificata o non verificata una condition quand uncheckable.
statuschange-action
si
Script eseguito ogni volta che avviene un cambio di stato della condition. Vedi Esecuzione di script automatica con variazioni di stato.
passive_force_status
si
Espressione calcolata quando il datasource viene forzato passivamente. Si rimanda a Datagroup Passivi.
Parametri per gli allarmi:
Dato
Opzionale
Default
Descrizione
upemail
si
Recipient per gli allarmi di stato UP. Vedi Generazione allarmi e transizioni di stato da UP e DOWN.
si
Recipient per gli allarmi DOWN (e UP se upemail non e' valorizzato). Vedi Generazione allarmi e transizioni di stato da UP e DOWN.
msg_downsubj
si
Soggetto per allarmi DOWN. Vedi Generazione allarmi e transizioni di stato da UP e DOWN.
msg_downbody
si
Corpo messaggio allarmi DOWN. Vedi Generazione allarmi e transizioni di stato da UP e DOWN.
msg_upsubj
si
Soggetto per allarmi UP. Vedi Generazione allarmi e transizioni di stato da UP e DOWN.
msg_upbody
si
Corpo messaggio allarmi UP. Vedi Generazione allarmi e transizioni di stato da UP e DOWN.
3.1.7.2.7.1. Espressione e valore di una condition¶
La expr di una condition e' una espressione per calcolare un valore vero o falso.
Quando il valore di una espressione non puo' essere calcolato (per un timeout di rete, un errore di sintassi, ecc.) si dice che l'esisto della valutazione di una condition e' uncheckable.
Si rimanda alla sezioni Expression Language e SANET built-in expression symbols per maggiori dettagli sul linguaggio valido per l'espressione.
Per altri dettagli sulla valutazione della expr si rimanda alla sezione Regole di valutazione di Datasource e Condition.
3.1.7.2.7.2. Ordine di esecuzione delle condition e cascade¶
All'interno dello stesso datagroup le condition sono valutate sequenzialmente seguento il seguente criterio:
Prima tutte le condition primarie (dovrebbe essercene solo una) (vedi Condition primary e dependson)
Tutte le condition non primarie in base all'ordine specificato dal parametro order.
A parita' di ordine vengono valutate le condition in ordine alfabetico.
Per il dettaglio di esecuzione di datasource e condition nell'intero datagroup si rimanda a Ordine di valutazione di datasource e condition.
Il parametro cascade serve per non valutare le condition successive (i ordine di esecuzione) se la condition corrente fallisce (o uncheckable).
3.1.7.2.7.3. Condition primary e dependson¶
Quando una condition e' flaggata come primary il sistema crea una catena di dipendenza (dependson) automaticamente.
Dalla condition primary dipenderanno:
tutte le altre condition dello stesso datagroup
tutti gli altri datagroup associati direttamente all'elemento di monitoraggio.
E' possibile configurare Sanet per avere delle condition primary sia a livello di nodo che sotto-element, anche contemporaneamente.
Warning
Il sistema non verifica quante condition "primary" sono state configurate per uno stesso elemento (o sotto-elemento). E' fondamentale avere un sola condition primary per nodo (elemento di monitoraggio) ed eventualmente una per ogni sotto-elemento. Nel caso vengano configurate per errore piu' condition "primary" per lo stesso elemento, gli effetti sul monitoraggio sono imprevedibili.
Questo schema spiega le dipendenze tra condition "normali" e "primary":
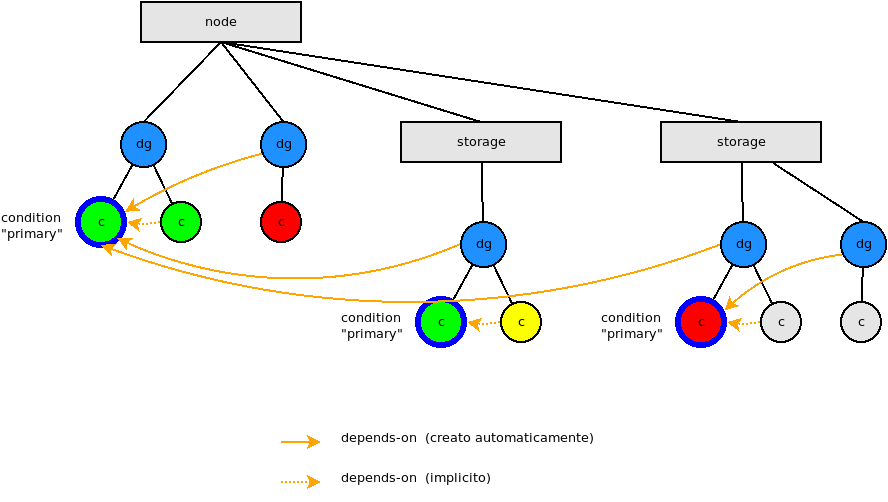
Quando si configura il parametro "depenson" e' possibile specificare uno dei seguenti filtri base:
Valore
Descrizione
(nullo) Non specificato. Viene calcolato il dependson con il meccanismo descritto prima.
none
Non viene creata nessuna dipendenza. (Il datagroup viene sempre eseguito indipendentemente dallo stato degli altri datagroup dell'elemento)
@node_primary
Viene creata una dipendenza con il "primary" del nodo monitorato. Serve per poter "saltare" il "primary" di un sotto elemento.
@linked_node_primary
Viene creata una dipendenza con il "primary" del nodo dell'interfaccia collegata all'interfaccia dove viene applicato il datagroup
Warning
Se nessuna condition soddisfa il parametro dependson (perche' ad esempio la condition non esiste ancora in configurazione), la configurazione viene salvata ma nessuna dipendenza viene effettivamente configurata. Con comandi di "refresh" e' possibile sistemare eventuali inconsistenze.
Esempi:
dependson none Dependson disabilitato dependson @node_primary Seleziona la condition primary del nodo corrente dependson @linked_node_primary Seleziona la condition primary del nodo dell'interfaccia linkata all'interfaccia corrente.
E' possibile specificare un filtro componendo una sequenza di parametri separati da virgola (,):
Valore
Descrizione
@classification:<str>
Viene selezionata la condition dell'elemento monitorato (o quello specificato da @node) che soddisfa la classification indicata
@node[:<name>]
Viene selezionata la condition del nodo indicato corrente (o di quello specificato dal nome)
@primary
Viene selezionata la condition primary dell'elemento corrente (o del nodo specificato da @node)
Esempi:
dependson @classificationi:network.status,@primary Condition del nodo corrente (default), primary e con classification "network.status" dependson @node:router01,@classificationi:network.reachability Condition del nodo router01, con classification "network.reachability"
Altri esempi con :
node n1 datagroup icmp-reachbility <-----+ exit <----+ | | | interface eth0 | | | | datagroup iface-status -----+ | exit | | exit | | exit | Il datagroup "n2:eth1;;xxx" dipende da "n1;;icmp-reachability" | e non da "n2:eth1;;iface-status" (primary dell'interfaccia n2:eth1) node n2 | | datagroup icmp-reachbility | exit <----+ | | | interface eth1 | | | | datagroup iface-status -----+ | exit | | datagroup xxx | dependson @linked_node_primary -----+ exit exit exit link n1 eth0 n2 eth1
Esempio 1:
node n1 datagroup icmp-reachbility <---+ <---+ exit | | | | datagroup snmp-status ----+ | | condition status <---+ | classification status.snmp | | exit | | | | exit | | | | datagroup cpu-hr | | dependson @classificationi:status.snmp ----+ | exit | | interface eth0 | | datagroup iface-status <---+ <---+ | exit | | | | | | datagroup iface-traffic ----+ | | | | exit | | | | datagroup special1 | | dependson @primary ----------+ | exit | | datagroup special1 | dependson @node_primary ------------------+ exit exit exit
3.1.7.2.7.4. Condition primary, ordine di esecuzione e cascade¶
L'attributo order permette di specificare in quale ordine vengono valutate le condition di uno stesso datagroup.
La condition primary viene sempre e comunque eseguita prima di tutte le altre, indipendentemente, dal valore dell'attributo order.
Quando una condition ha l'attributo cascade impostato a True, se non e' verificata (valore False) oppure non e' valutabile (uncheckable) tutte le condition valuate successivamente (con order uguale o maggiore), non vengono eseguite e vanno in stato Depenson (vedi Stato di una condition).
3.1.7.2.7.5. Dipendenze tra nodi gesti da agenti (poller) diversi¶
Ogni agente di monitoraggio comunica con il server centrale (Sanet) e carica tutti i dati/configurazioni necessarie per monitorare SOLO nodi a esso associati.
E' comunque possibile creare catene di dipendenze (usando il "dependson") anche tra datagroup presenti in nodi gestiti da agenti (poller) diversi (locali o remoti).
Quando un agente deve eseguire un datagroup che dipende da una condition "gestita" da un'altro agente, l'agente contatta il server centrale (Sanet) che verifica lo stato della catena di dipendenze e rimanda all'agente le informazioni necessarie per proseguire con l'elaborazione. di cui non ha informazioni.
Nello schema seguente sono riportati i passi per l'elaborazione del datagroup "datagroup1" gestito dall'agente MAIN-AGENT che dipende dal datagroup datagroup2 (gestito dall'agente REMOTE-AGENT)
Lo stato del datagroup datagroup2 viene inviato al server centrale.
Lo stato del datagroup datagroup2 viene salvato sul DB
L'agente MAIN-AGENT deve elaborare il datagroup datagroup1 e si accorge che dipende dal datagroup datagroup2, quindi contatta il server centrale.
Il server centrale carica dal DB lo stato attuale del datagroup2 e calcola le dipendenze.
Il server centrale invia all'agente l'esito della verifica e l'agente va avanti con l'esecuzione del datagroup1.
+----------------+ | SERVER SANET | | | | | | +--------+ | (4) +------+ | | sanetd | |<--------| DATA | | +--------+ |-------->| BASE | | | (2) +------+ +----------------+ ^ | ^ | | | | | | +----------------------+ | | | +----------------------+ | MAIN-AGENT | | | | (1) | REMOTE-AGENT | | | | | | | | | | (3) | | | | | | +----------------+ |---------------+ | +---------------| +----------------+ | | | nodo1 | | | | | nodo2 | | | | | |<-----------------+ | | | | | | +------------+ | | (5) | | +------------+ | | | | | datagroup1 | | | | | | datagroup2 | | | | | +------------+ | | | | +------------+ | | | | . | | | | ^ | | | +-------.--------+ | | +--------.-------+ | | . | | . | | . | | . | +----------.-----------+ +-----------.----------+ . dependson . ...................................................................
Se lo stato di un datagroup non locale non viene recuperato correttamente (passi 3,4,5), a causa di problemi di comunicazione/rete tra l'agente e il server centrale, l'esito della verifica delle dipenze viene considerato non verificato e le condition passano in stato DEPENDSON-UP o DEPENDON-DOWN a seconda dello stato in cui si trovano al momento dell'elaborazione.
Warning
Per ragioni di performance, gli agenti non chiedono continuamente lo stato delle dipendenze di condition/datagroup gestiti da altri agenti, ma mantengono una cache. I dati di un datagroup non locale vengono mantenuti nella cache interna dell'agente per un tempo equivalente al suo min-period. Questo significa che in situazioni particolari, la verifica dello stato delle dipendenze potrebbe generare dei falsi positivi/negativi.
Warning
Poiche' gli agenti devono comunicare con il sever centrale via rete, creare dipendenze tra datagroup gestiti da agenti diversi rallenta l'esecuzione complessiva del monitoraggio e possono verificarsi anomalie nel monitoraggio se la comunicazione con il server centrale presenta dei problemi.
Note
E' sconsigliato creare dipendenze tra datagroup gestiti da agenti diversi. Se configurazioni di questo tipo sono necessarie e' seriamente consigliato limitare al massimo i casi di dipenzenza multi-agente.
3.1.7.2.7.6. Stato di una condition¶
Dopo che una condition viene controllata, il suo stato viene deciso in base al valore restituito dalla sua expr:
valore true : condition verificata
valore false : condition non verificata
errore: condition uncheckable
Questi sono tutti gli stati possibili:
CODICE
Titolo
Descrizione
DN
Down
Controllo non verificato (tries = max-tries)
FA
Failing
Controllo non verificato (tries < max-tries)
UP
Up
Controllo verificato
IN
Suspended
Stato sospeso
DU
Depenson UP
Controllo dipendente da altro controllo sospeso/uncheckable/down (stato precedente UP)
DD
Depenson DOWN
Controllo dipendente da altro controllo sospeso/uncheckable/down (stato precedente DN)
UU
Uncheckable UP
Controllo non verificabile per errori di rete/timeout/ecc. (stato precedete UP)
UD
Uncheckable DOWN
Controllo non verificabile per errori di rete/timeout/ecc. (stato precedete DN)
Schema delle transizioni di stato possibili:
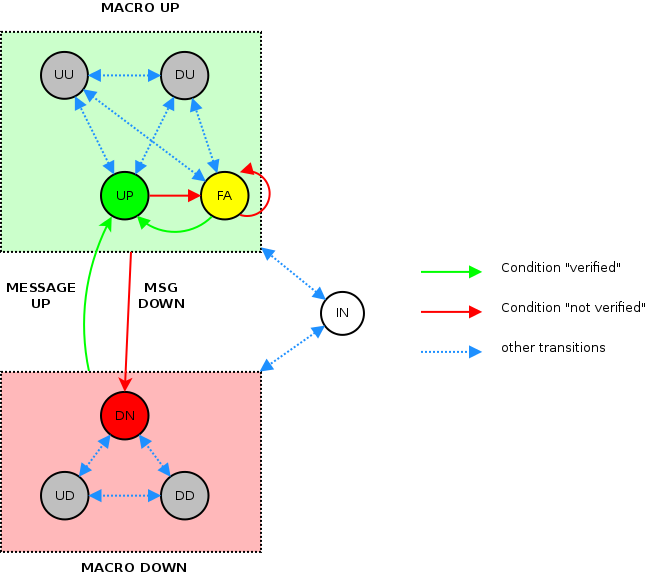
Note
Le transizioni, all'interno del MACRO STATO UP, da e verso lo stato FA (Failing) sono leggermente semplificate.
Note
Lo stato suspended (IN) puo' essere raggiunto da un qualsiasi degli altri stati. Gli stati uncheckable (UU, DU, UD, DD)
Per semplificare la gestione delle transizioni che generano allarmi, gli stati di una condition sono raggruppati in MACRO STATI chiamati MACRO UP e MACRO DOWN (lo stato SOSPESO e' uno stato a parte).
Sanet genera allarmi quando lo stato di una condition passa da un qualunque stato appartenente al macro stato UP a qualunque stato appartenente al macro stato DOWN o viceversa.
CODICE
Nome
MACRO STATO
UP
Up
UP
UU
Uncheckable UP
UP
DU
DependsON UP
UP
FA
Failing
UP
DN
Down
DOWN
DD
DependsON DOWN
DOWN
UD
Uncheckable DOWN
DOWN
IN
Sospeso
SOSPESO
Per semplificazione, quando lo stato di una condition e' uno qualunque di questi, la condition e' considerata virtualmente UNCHECKABLE (UN):
Uncheckable UP (UU)
Dependson UP (DU)
Uncheckable DOWN (UD)
Dependson DOWN (DD)
Important
Questa semplificazione e' puramente concettuale, in virtu' del fatto che se una condition si trova in un uno di questi stati, significa la sua valutazione non e' stata verificata con certezza (timeout, errori di rete, errori nella expr, ecc.), al contrario di quando si trova in stato UP, DOWN, FA o SOSPESO.
3.1.7.2.7.7. Ultima variazione significativa¶
Alcune variazioni di stato intermedie di una condition potrebbero essere cosi' frequenti da essere poco significative.
Sanet tiene traccia di quella che viene definita l'ultima variazione significativa.
Una variaizone di stato e' significativa quando lo stato di una condition passa da uno stato MACRO UP , MACRO DOWN o Sospeso.
In particolare Sanet ricorda:
L'orario dell'ultima variazione significava
Lo stato precedente al momento dell'ultima variazione significativa.
Important
la data di ultimo cambiamento di stato o la data dell'ultima variazione sono visualizzate in diversi punti dell'interfaccia grafica, alcuni regolabili da configurazione utente.
3.1.7.2.7.8. Uncheckable fallback¶
Quando la valutazione di una condition non e' possibile (per errori di rete, timetout, ecc.), l'esito della valutazione e' considerato uncheckable (non verificabile).
Quanto l'esito e' uncheckable, lo stato assegnato di una condition puo' passare a Uncheckable UP (UU) o Uncheckable DOWN (UD), a seconda dello stato precedente (vedi schema nel paragrafo Stato di una condition).
Il parametro uncheckable-fallback serve ad indicare se la condition deve essere considerata verificata o non verificata se la valutazione della condition e' uncheckable.
Warning
Non confondere esito della valutazione (verificato/non verificato) con stato della condition.
I valori ammessi sono:
UP - Considera la condition come verificata.
DN - Considera la conditonn come non verficata.
Esempio
Ipotizziamo di avere una condition in stato UP.
Sanet valuta la condition e calcola come esito della valutazione il valore uncheckable.
Se il parametro uncheckable fallback non e' impostato:
Lo stato della condition passa da UP a Uncheckable UP (UU).
Se il parametro uncheckable fallback e' impostato a UP:
La condition viene considerata come verificata.
Lo stato della condition resta in UP.
Se il parametro uncheckable fallback e' impostato a DN:
La condition viene considerata come non verificata.
Lo stato della condition passa da UP a FA o DN (a seconda del parametro max-tries).
3.1.7.2.7.9. Gestione del flapping¶
Il flapping e' la situazione in cui lo stato di una condition si alterna continuamente tra (macro) stati UP a DOWN (vedi Stato di una condition) per un certo periodo di tempo.
Sanet implementa un meccanismo di flap detection per permettere di gestire adeguatamente gli allarmi generati da condition in stato di flapping.
Lo stato di flapping di una condition dipende da un valore numerico chiamato penalty.
Quando la penalty supera una certa soglia, chiamata flap-penalty-high, la condition e' considerata in stato di flapping.
Quando la penalty diminuisce e si abbassa sotto una soglia chiamata flap-penalty-low, la condition smette di essere in stato flapping.
Il valore della penalty:
aumenta del valore specificato dal parametro flap-penalty ogni volta che avviene una variaione di stato significativa per il flapping (vedi Stato FAILING e Flapping).
Important
Quando il parametro flap-penalty vale 0, la flap detection non e' attiva.
diminuisce ad ogni "check" (quindi ad ogni minperiod, circa) se non ci sono variazioni di stato significative per il flapping (vedi Stato FAILING e Flapping). Il modo con cui la penalty viene diminuita nel tempo dipende dall'algoritmo di flapping utilizzato. Vedi Algoritmi di flapping.
Il valore della penalty e' sempre maggiore o uguale a 0, e non puo' mai superare un valore massimo indicato dal parametro flap-penalty-limit. Se flap-penalty-limit non e' specificato/configurato, di default corrisponde a 5 volte il valore di flap-penalty-high.
Ricapitolando, vale la regola:
0 flap-penalty-low flap-penalty-high flap-penalty-limit
|--------------------------|--------------------------|--------------------------|
<--------------------------- range della "penalty" -------------==----------->
La penalty di una condition cambia quando il suo stato subisce una variazione significativa per riconoscere una situazione di flapping, ovvero quando si passa da uno MACRO STATO UP ad un MACRO STATO DOWN.
Riconoscere uno stato di flapping puo' essere complicato se la condition e' configurata per prevedere lo stato di FAILING poiche' lo stato FAILING rientra tra gli stati UP. Questo influenza la rapidita' con cui gli algoritmi di flapping possono riconoscere una situazione di flapping.
Di default, Sanet considera il FAILING al pari di uno stato DOWN.
Sanet permette comunque di decidere come considerare la transizione da UP a FAILING, attraverso il parametro flapping-fa-as-dn.
flap-fa-as-dn = false
MACRO STATO UP | | MACRO STATO DOWN
| |
UP <---> FA---|---------|----------> DN
DU | | DD
UU | | UD
flap-fa-as-dn = true (DEFAULT)
MACRO STATO UP | | MACRO STATO DOWN
| |
UP -----------|---------|-->FA ----> DN
DU | | DD
UU | | UD
_
Important
E' consigliato disabilitare il FAILING (impostando max-tries a 0) se si vuole utilizzare gli algoritmidi flapping detection.
Esistono due algoritmi di flapping detection, che differiscono nel modo con cui viene decrementata la "penalty"
a decrescita lineare
a decrescita esponenziale
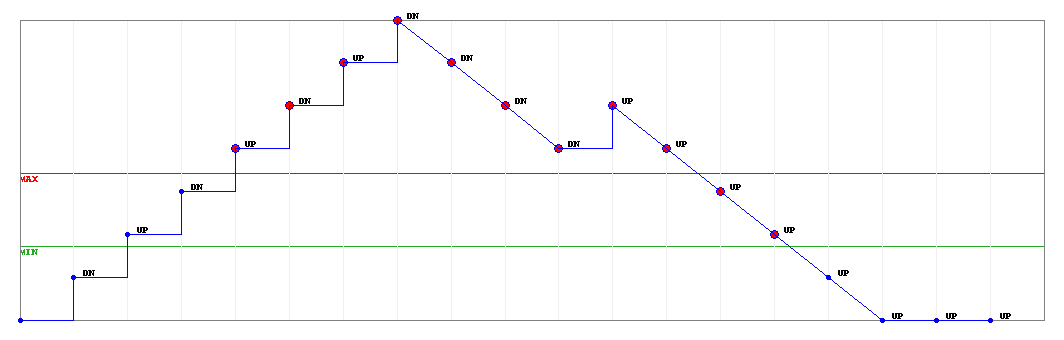
Con questo algoritmo la penalty viene:
incrementata di un valore costate flap-penalty se al momento del check avviene una variazione di stato.
decrementata se non c'e' una variazione di stato al momento del check. Il decremento corrisponde ad un valore proporzionale alla flap-penalty e al numero di min-period trascorsi dal check precedente. (Questo significa che, in situazioni normali, tra un check ed un altro la penalty cala di una flap-penalty).
Esempio:
Note
Intuitivamente questo algoritmo conta il numero di check verificati o meno. Se si decide di usare questo algoritmo, conviene parametrizzare i parametri flap-penalty, flap-penalty-high e flap-penalty-low con valori interi tra 1 e 10.
Si rimanda all'appendice Flapping: casi pratici per alcuni esempi su come valorizzare i parametri flap-penalty, flap-penalty-high e flap-penalty-low.
Questo algoritmo e' alternativo a quello lineare e viene applicato solo se il parametro flap-half-life e' diverso da 0.
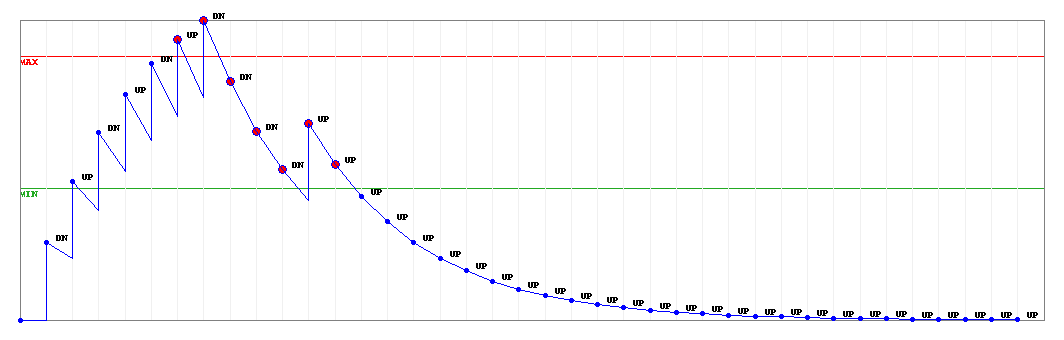
Con questo algoritmo la penalty viene:
incrementata di un valore costate flap-penalty se al momento del check avviene una variazione di stato.
decrementata se non c'e' una variazione di stato al momento del check. La penalty si dimezza ogni volta che sono trascorsi flap-half-life secondi. (Questo significa che la decrescita e' esponenziale e non lineare).
Esempio:
Important
Parametrizzare correttamente i parametri flap-penalty , flap-penalty-high, flap-penalty-low e flap-half-life non e' banale e richiede dimestichezza con logiritmi ed esponenziali.
Si rimanda all'appendice Flapping: casi pratici per una panoramica su come gestire il tuning di questi parametri.
I parametri di flapping delle condition si configurano a livello di datagroup-template (o in library o nel tenant).
E' possibile fare l'override dei parametri di flapping da file di configurazione globale (settings) modificando il parametro
FLAP_PENALTY_DEFAULTS = [ ... ]
Attraverso questo parametro si puo' specifiare un elenco di regole di override della forma:
{ # Parametri di match # # Per fare match su qualunque condition mettere # # "match": "*" # # Altrimenti specificare un dizionario con le due chiavi: # # "match": { # "kind" : "node" | "interface" | "storage" | "service" | "device" # "primary": False, # }, # # Esempi: # # "match": "*", # # "match": { # "kind" : "node", "interface", "storage", "service", "device" # "primary": False, # }, # "match": "*", # # parametri del flapping per le condition che fanno match # "params": { 'penalty' : 1, # >= 0 'unpenalty' : 1, # >= 0 'penalty_limit': 10, # >= 0 'penalty_high' : 5, # >= 0 'penalty_low' : 1, # >= 0 'half_life' : None, # Puo' essere None o un in intero > 0 'fa_as_dn' : 1, # 1 (si), 0 (no) } },
Tutte le regole vengono controllate dalla prima all'ultima. La prima che fa match viene applicata e le altre vengono ignorate.
Esempio: Solo per le condition primary dei nodi viene applicata la seguente regola.
FLAP_PENALTY_DEFAULTS = [ { "match": { "kind": "node" "primary": 1, } "params": { 'penalty' : 1, 'unpenalty' : 1, 'penalty_limit': 10, 'penalty_high' : 5, 'penalty_low' : 1, 'half_life' : None, 'fa_as_dn' : 1, } }, ]
3.1.7.2.7.10. Messaggi di allarme¶
Quando Sanet deve generare un allarme in seguito ad DOWN (o UP) di una condition, utilizza i dati di configurazione della condition per produrre un messaggio composto da:
destinatario (indirizzo email/alias valido)
soggetto
corpo del messaggio
I valori di questi parametri vengono specificati attraverso specificati dai campi di testo:
upemail e email
msg_upsubj e msg_upbody
msg_downsubj e msg_downbody
Il testo dei campi msg_upsubj, msg_upbody, msg_downsubj, msg_downbody possono contenere wildcard speciali per aggiungere automaticamente al testo informazioni di sistema.
Per tutti i dettagli su come configurare il testo degli allarmi si rimanda a: Gestione Messaggi/Allarmi.
Lo stato di flapping di una condition non influenza il modo con cui Sanet produce ed invia allarmi.
E' possibile inserire nei messaggi di up e down alcune informazioni sullo stato di flapping. Si rimanda alla sezione Wildcard per l'elenco delle wildcard utilizzabili.
E' possibile configurare entables per filtrare gli allarmi di condition in stato di flapping (vedi Campi/shortcut per gestire il flapping o aggiungere nel testo di messaggi informazioni aggiuntive tramite wildcard (vedi Tabella riassuntiva degli shortcut disponiboli ).
Warning
E' molto richiso inibire l'invio di allarmi sulla base dello stato di flapping. E' consigliabile prevedere una fase di tuning per evitare di perdere segnalazion
3.1.7.2.8. Trend¶
Nell'ottica di agevolare l'interpretazione degli allarmi, sono presenti informazioni aggiuntive (inseribili nel testo dell'email tramite wildcard) che forniscono indicazioni sul trend del datasource in allarme, utili a capire la criticita' dell'allarme stesso.
Il trend permette di calcolare l'andamento di un datasource e di effettuare una stima di quando raggiungera' una certa soglia.
Note
Per essere calcolato, il trend si basa sulla serie storica del datasource memorizzata fino a quel momento.
In aggiunta alla data di raggiungimento della soglia viene anche effettuata una stima sul tipo di andamento:
lineare (crescita o descrescita costanti, con poche variaizoni);
con picchi (crescita o decrescita con grosse variazioni).
Un trend e' caratterizzato dai seguenti attributi configurabili:
Dato
Opzionale
Default
Descrizione
name
no
Nome del trend
ds
si
Nome del datasource (dello stesso datagroup) di cui calcolare il trend
max-value
si
Espressione che rappresenta il valore di soglia quando il trend e' crescente
min-value
si
Espressione che rappresenta il valore di soglia quando il trend e' calante
steps_back
si
60
Numero di dati del datasource <ds> da prendere in considerazione per calcolare il trend, recuperati a ritroso partendo dal piu' recente. Valore minimo: 5.
steps_tolerance
si
70
Percentuale di dati minimi rispetto a <steps_back> per poter calcolare il trend
Important
E' obbligatorio valorizzare almeno uno dei due valori di soglia (max-value o min-value) ma possono essere valorizzati anche entrambi.
Note
La configurazione di steps_back incide sul calcolo del trend nel seguente modo:
aumentandone il valore verranno presi in considerazione un maggior numero dati storici, quindi il "passato" incidera' di piu' nella stima;
diminuendone valore si prenderanno in considerazione meno dati storici, quindi il "presente" incidera' maggiormente nella stima.
Per un esempio di configurazione si rimanda al paragrafo: Trends
3.1.7.2.9. Esecuzione di script automatica con variazioni di stato¶
Il parametro statuschange-action e' una stringa che permette di specificare uno programma/script esterno da eseguire ogni volta che una condition cambia di stato.
Warning
il programma/script esterno viene eseguito con i permessi del processo del server di Sanet (root)
Warning
il processo eseguito e' completamente asincrono rispetto agli altri sistemi di Sanet. Se e' richiesto implementare logiche con azioni temporalmente sincronizzate, tutto deve essere implementato all'interno del comando eseguito.
- Il comando esterno viene eseguito in modalita' demonizzata:
Standand output (stdout) e standard error (stderr) del processo vengono rediretti in "/dev/null".
Una volta in esecuzione la current working directory del processo e' impostata a "/".
Sanet aggiunge numerose variabili d'ambiente per consentire al processo di gestire corretamente l'azione legata alla variazione di stato. Vedi Variabili di ambiente
Nel log di Sanet viene tracciato SOLO l'orario di inizio esecuzione.
3.1.7.2.9.1. Formato¶
La stringa contenuta in statuschange-action deve contenere:
il path del programma/script esterno da eseguire
una sequenza di eventuali parametri di esecuzione.
Formato:
<path> <param1> <param2> <param3>
Per gestire valori che contengono caratteri si spaziatura (white space, tabs, ecc.) bisogna utilizzare il quoting ( con apici singoli o doppi ) corretto.
Warning
La stringa deve rispettare la sintassi di un comando shell, ma:
non possono essere specificati nella stringa varibili d'ambiente perche' non verranno espanse al momento di esecuzione del processo.
non possono essere usati comandi per l'esecuzione di subshell ( $(...) o ... )
Il path del programma/script da eseguire puo' essere:
- Assoluto:
Esempio:
/usr/share/scripts/action.sh
- Relativo:
Lo script verra' cercato all'interno della directory specificata dal parametro di configurazione SANETD_EXEC_DIR specificato in settings.
Esempio:
action2.sh -> {{SANETD_EXEC_DIR}}/action2.shEsempio:
prova/action1.sh -> {{SANETD_EXEC_DIR}}/prova/action1.sh
Important
di default SANETD_EXEC_DIR punta alla directory {{VAR_DIR}}/_action_scripts (vedi default_settings). Questa directory non viene creata automaticamente.
Esempi di stringe sintatticamente valide:
action1.shaction1.sh -t 10 -p "param with spaceses" # Parametro con spazi gestito con quoting/usr/local/action1.sh -t 10 -p "param with spaceses"
Esempi di stringhe sbagliate
echo $(cat file.txt) > /tmp/prova.txt # NO! Sintatticamente corretta, ma esecuzione di subshell o redirezioni non funzionano!/usr/bin/ls $PWD # NO! Sintatticamente corretta, ma $PWD non verra' espansa!PIPPO=10 /usr/bin/ls $PIPPO # NO! Sintatticamente corretta, ma questo genere di comandi non e' supportato!
3.1.7.2.9.2. Action UUID¶
Ad ogni esecuzione di script esterni Sanet associat un UUID univoco generato al momento dell'esecuzione.
Questo permette di identificare univocamente ogni singola esecuzione.
3.1.7.2.9.3. Passare dati di "input" al processo esterno¶
E' possibile passare dati al processo da eseguire in due modi:
Parametri a riga di comando
Variabili d'ambiente
3.1.7.2.9.4. Parametri dei datagroup (parameter) usanti nella riga di comando¶
Sono specificati insieme al path del programma nella stringa statuschange-action.
action1.sh -t 10 -p "param with spaceses" ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Il primo parametro dei parametri a riga di comando ($0 per le shell) contiene il path completo del programma/script eseguito.
E' possibile usare i parametri del datagroup (parameter) passandoli a riga di comando usando la sintassi:
$<name>
Esempio: Se il datagroup e' stato definito cosi:
datagroup-template dgtestaction ... parameter param1 str hello parameter param2 num 3.14 ... condition c ... statuschange-action "/tmp/action.sh $param1 $param2 foo bar" ... exit exit
Lo script verra' eseguito con:
/tmp/action.sh hello 3.14 foo bar
Warning
L'espansione dei parametri del datagroup e' LETTERALE e non viene gestita dalla shell. Non e' possibile comporre pezzi di parametri
datagroup-template dgtestaction
...
parameter param1 str hello
...
condition c
...
statuschange-action "/tmp/action.sh $param1_foo"
...
exit
exit
NON VIENE eseguito come:
/tmp/action.sh hello_foo
MA COME:
/tmp/action.sh $param1_foo
3.1.7.2.9.5. Variabili di ambiente¶
Sono variabili create da Sanet nel contesto di esecuzione del processo ed hanno il prefisso SANET_.
Queste sono le variabili d'ambiente disponibili:
Variabile d'ambiente
Descrizione
SANET_ACTION_UUID
UUID univoco di esecuzione
SANET_TENANT_NAME
Nome del tenant
SANET_TENANT_UUID
UUID del tenant
SANET_NODE_UUID
UUID del nodo associato alla condition
SANET_NODE_NAME
Nome del nodo associato alla condition
SANET_ELEMENT_UUID
UUID dell'elemento di monitoraggio associato alla condition
SANET_ELEMENT_NAME
Nome dell'elemento di monitoraggio associato alla condition
SANET_CONDITION_UUID
UUID della condition
SANET_CONDITION_PATH
Path della condition
SANET_CONDITION_LASTCHANGE
Timestamp con la variazione di stato della condition
SANET_CONDITION_NEW_STATE
Stato corrente della condition
SANET_CONDITION_OLD_STATE
Stato precedente della condition
I parametri del datagroup sono disponibili come variabili d'ambiente con la sintassi
SANET_DATAGROUP_PARAMETER_<name>
Esempio: Se il datagroup definisce un parametro param1, la variabile d'ambiente corrispondente sara':
SANET_DATAGROUP_PARAMETER_param1
3.1.7.2.9.6. Modalita' di esecuzione dello script¶
Il programma/script esterno viene eseguito da server principale come processo parallelo ed assolutamente indipendente.
Warning
Il server centrale non controlla/attende la terminazione del processo eseguito prima di elaborare altri dati.
Warning
Lo stesso script potrebbe essere eseguito piu' volte in parallelo. Problemi di concorrenza devono essere gestiti dallo script.
Warning
Il processo esterno e' indipendente e la sua esecuzione non si interrompe anche se il server di Sanet viene fermato/ravviato.
3.1.7.2.9.7. Output del processo esterno¶
Il processo esterno viene eseguito come demone e per tanto il suo stdout e stderr non sono collegati a nessuno stream (file).
Se il processo esterno deve produrre dati in output deve utilizzare le funzioni di shell o altre api per salvare questi dati:
logger (syslog)
cat, echo, tee, ecc.
3.1.7.2.10. Regole di valutazione di Datasource e Condition¶
3.1.7.2.10.1. Valutazione di una expr¶
La valutazione di una expr di una condition o di un datasource avviene sempre seguendo le stesse regole.
A seconda che si stia valutando la expr di una condition o di un datasource possono cambiare i simboli (variabili $foo) utilizzabili che Sanet prepara al momento dell'esecuzione. Si rimanda alla sezione SANET built-in expression symbols.
La valutazione di expr puo' restiture due tipi di risultati:
un valore null o None (risultato UNCHECKABLE)
un qualunque valore numero intero, numeroi virgola mobile, stringa di byte o booleano (vero/falso)
Quando si parla di expr di una condition, la valutazione dell'espressione si considera verificata se il valore prodotto e':
diverso da null
numerico <> 0
stringa di byte diversa da stringa vuota ('')
true (booleano)
3.1.7.2.10.2. Valori correnti e valori precedenti¶
A volte e' necessario effettuare dei controlli confrontando dati / valori (calcolati e/o letti via rete) al momento dell'esecuzione con gli stessi dati/valori calcolati al check precedente.
Sanet distingue due tipi di valori al momento dell'esecuzione:
correnti : sono i dati calcolati al momento del check (OID SNMP, valori prodotti da chiamate a funzione, ecc.)
precedenti (o old): sono i dati calcolati/raccolti dalla expr durante check precedente.
Quando Sanet valuta una espressione, i valori correnti che sono stati calcolati con successo (ovvero senza errori che causano lo stato uncheckable), vengono salvati in attesa del check successivo. Al check successivo verranno considerati valori precedenti.
Note
Quando una expr contiene il riferimento a valori precedenti e viene eseguita per la prima volta, l'espressione viene eseguita ma l'esito della valutazione produce un valore nullo, ovvero UNCHECKABLE.
Esempio:
sanet-manage exec_expr phink0 '1.3.6.1.2.1.1.1.0#' VALUE: None INFOS:
Warning
se una expr referenzia (in qualche modo) solo valori precedenti senza referenziare/produrre anche valori correnti, l'esisto della valutazione sara' perennemente UNCHECKABLE.
Esistono tre modi per poter utilizzare valori correnti/precedenti nelle expr di Sanet:
Quando la expr di un datagroup viene valutata con successo Sanet memorizza:
l'istante temporale dell'ultimo check valido.
il valore associato all'ultimo check valido.
Puo' essere utile valutare quanto tempo e' passato dall'ultima volta che una espressione e' stata calcola senza errori e usare questa informazione come parametro aggiuntivo per effettuare un controllo.
All'interno di una expr il simbolo $delta memorizza il tempo trascorso dall'ultimo check avvenuto con successo. Il valore e' memorizzato in secondi in virgola mobile (es. 1.3 secondi, 0.003 secondi, ecc.)
Questo e' uno schema di come viene calcolato il parametro $delta al momento del check in base all'esito del check precedente.
1 2 3 4 5 6 TEMPO ----|---------|----------|----------|----------|-----------|------------> secondi CHECK OK UNCHECK UNCHECK UNCHECK OK ... expr $delta |----1----| |----------2---------| |-----------------3-------------| |---------------------4--------------------| |-----1-----|
I datasource di tipo COUNTER utilizzano il valore del parametro $delta e il valore precedente per calcolare il rate istantaneo.
Important
il rate istantaneo calcolato dopo una valutazione UNCHECKABLE puo' essere molto impreciso in virtu' della logica di aggiornamento del $delta e del valore precedente descritta nel paragrafo precedente.
Esempio: sequenza di valutazioni di un datasource COUNTER:
1 2 3 4 5 6 TEMPO ----|-------|--------|--------|--------|---------|-----> secondi check expr (valore corrente) 1 5 8 UNCHECK 10 11 $delta n/a 1 1 1 2 1 valore precedente n/a 1 5 8 8 10 rate istantaneo n/a 4/s 3/s 3/s(*) 1/s 1/s (*) rate non aggiornato (new-old)/$delta
Sanet implementa un meccanismo build-in per gestire i valori correnti/precedenti letti dalla rete attraverso SNMP.
Per sfruttare questo meccanismo bisogna utilizzare una sintassi particolare nelle expr.
<OID expr> @ Valore corrente (letto via rete) <OID expr> # Valore precedente
Esempio:
1.3.6.1.2.1.1.1.0@ 1.3.6.1.2.1.1.1.0#
Per i dettagli sulle regole di composizione delle espressioni SNMP si rimanda alla sezione: SNMP Sub-expressions.
Esistono funzioni che permettono di calcolare un valore al momento di un check e utilizzare quel valore al check successivo.
Ad esempio:
...
Si rimanda all'elenco completo SANET standard expression functions.
Il valore calcolato di un datasource o il valore precedente di un datasource puo' essere utilizzato nelle expr usando la seguente sintassi:
{ <nome> @ } Valore del datasource calcolato dal sistema al momento di check del datagroup. { <nome> # } Valore del datasource check precedente del datagroup.
Danger
Assicuratevi di non referenziare entrambi i valori nella stessa expr del datasource stesso. Esempio:
{ds1@} + {ds2@}
Important
Bisogna fare attenzione all'ordine di esecuzione dei datasource e condition altrimenti si rischia di referenziare valori non ancora calcolati.
E' possibile sapere e utilizzare il tempo di check di una condition o di un datasource utilizzando la seguente sintassi:
{ <nome>.checktotaltime @ } Tempo di elaborazione { <nome>.checktotaltime # } Tempo di elaborazione al check precedente
Important
Bisogna fare attenzione all'ordine di esecuzione dei datasource e condition altrimenti si rischia di referenziare valori non ancora calcolati.
Danger
Se un datagroup contiene un datasource e una condition con lo stesso nome ci possono essere dei problemi di incoerenza con i valori effettivamente utilizzati.
3.1.7.2.10.3. Valori dei datasource usati nelle expr¶
All'interno di un datagroup, una condition puo' (ma non obbligatoriamente) verificare una condizione basandosi su:
Un valore raccolto raccolto/calcolato dalle rete (es: valore traffico in input su una interfaccia raccolto via protocollo SNMP)
il valore corrente di uno o piu' datasource del medesimo datagroup.
Schema:
DATAGROUP
|
+----------+----------+--------+-------+----------+-----------+
| | | | | |
ds1 ds2 ds3 c1 c2 c3
| | ^ | ^ || | |
| | `--------+ `-------------+| | |
| | | | |
GET script.sh GET GET GET
SNMP SNMP SNMP SNMP
3.1.7.2.10.4. Ordine di valutazione di datasource e condition¶
Quando viene valutato un datagroup (non e' sospeso), l'ordine di valutazione e' stabilito nel seguente modo:
Step 0: verifica se la condition da cui dipende questo datagroup e' verificata o meno (vedi Condition primary e dependson).
Step 1: Calcola tutti i datasource ordinati in base al loro attributo "order"
Se un datasource non e' verificato ed e' l'attributo cascade e' true, viene interrotta la valutazione di tutti i datasource successivi.
Step 2: Verifica tutte le condition
Viene valutta la condition primaria.
Se la condition primaria non e' verificata, tutte le condition successive non vengono valutate e passano in stato dependson (Up o Down in base al loro stato attuale).
Vengon valutate le condition non primarie.
L'ordine di esecuzione dipende dal parametro order.
Se la condition non e' verificata e il parametro cascade e' true, tutte le condition successive non vengono valutate e passano in stato dependson (Up o Down in base al loro stato attuale).
Important
Se all'interno del datagroup sono presenti piu' condition primarie, non e' predicibile quale verra' valutata per prima e quali saranno le altre condition (anche primarie) a passare in stato dependson.
3.1.7.2.11. Parametri opzionali¶
I parametri opzionali permettono di definire variabili utilizzabili nel calcolo delle espressioni (attribugo expr) di datasource e condition.
Ogni parametro e' definito tre attributi:
nome: stringa che identifica il parametro. All'interno di un datagroup il nome e' univoco.
tipo: indica il tipo di parametro. Esistono i seguenti tipi di parametri:
numero: numero (in virgola mobile)
stringa: sequenza di caratteri
boolean: valore booleano vero o falso
3.1.7.2.11.1. I parametri nelle espressioni¶
Ogni parametro viene richiamato all'interno delle espressioni di datasource e condition utilizzando la seguente sintassi:
$<nome>
Esempio: Se in un datagroup e' definito il parametro url, in una espressione (di datasource o condition) viene utilizzato cosi:
urlContentMatches( $url )
Se una espressione richiama un parametro non definito nel datagroup, la valutazione dell'espressione viene interrotta e il valore dell'espressione e' uncheckable.
3.1.7.2.12. Timegraph¶
I timegraph permettono di creare grafici temporali utilizzando serie di dati (ma non necessariamente) calcolate sui valori dei datasource di un datagroup.
Un timegraph viene rappresentato utilizzando un piano con due assi ortogonali: l'asse delle ascisse (orizzontale) rappresenta il tempo, mentre l'asse delle ordinate (verticale) rappresenta i valori delle serie definite.
E' possibile define un numero illimitato di timegraph in un datagroup.
Ogni timegraph e' caratterizzato dai seguenti attributi:
Attributo
Default
Descrizione
name
Nome del timegraph (deve essere univoco all'internod el datagroup)
title
Titolo descrittivo del timegraph
primary
no
Flag che indica se il timegraph e' un timegraph primario (vedi sotto)
stacked
si
Indica se il timegraph puo'
ylegend
Stringa usata per indicare l'unita' di misura dell'asse delle ordinate.
classification
(facoltativo) Permette di indicare una classificazione per il timegraph
3.1.7.2.12.1. Timegraph primario¶
Quando un timegraph ha il flag primary attivo (valore si o true) il timegraph e' detto timegraph primario.
Quando viene visualizzata la pagina web di un elemento (nodo, interfaccia, disco, servizio, device) il sistema individua il timegraph primario e lo visualizza all'internod ella pagina.
Note
Il sistema non controlla se piu' di un timegraph appartenenti allo stesso elemento e' impostato come primario. Se piu' di un timegraph e' definito come primario, il sistema scegliera' uno qualunque di questi e lo visualizzera nella pagina web.
3.1.7.2.12.2. Serie¶
Per poter visualizzare dei dati in un timegraph e' necessario definire le sue serie dati.
Una serie indica quali dati (valori temporali) rappresentare e come devono essere rappresentate (colore, descrizione, ecc.)
I valori di una serie possono essere calcolati utilizzando i valori temporali di un datasource (anche di altri elementi/datagroup) o i valori di altre serie dello stesso timegraph.
Gli attributi di una serie sono:
Timegraph
Default
Descrizione
name
Nome della serie (deve essere univoco)
legend
Descrizione usata per la leggenda (se vuoto nella leggenda comparira' il "name")
color
(facoltativo) Stringa con la codifica del colore
style
Stile grafico per rappresentare la serie
render order
(facoltativo) Numero progressivo l'ordine di visualizzazione della serie nel grafico
variable value
Identificativo del datasource da cui ricavare i dati (nome nel datagroup o path)
computed value expr
Espressione per calcolare i valori della serie usando le altre serie dati
Codifica dei Colori
Per indicare il colore di una serie bisogna usare la seguente sintassi:
#<codifica esadecimale RGB>
Esempi:
#ff0000 Rosso #00ff00 Verde #0000ff Blue #ffff00 Giallo #ffffff Bianco #000000 Nero
Stili
Sono definiti i seguenti stili per una serie:
Stile
Descrizione
line
La serie viene rappresentata da una linea (continua)
area
La serie viene rapppresentata da una area colorata limitata superiormente dai valori della serie.
tick
Vengono visualizzate delle linee verticali in corrispondenza dei valori della serie > 0
invisible
La serie e' definita ma non viene visualizzata (nemmeno la leggenda)
3.1.7.2.12.3. Serie da datasource o calcolate¶
Come gia' detto nei paragrafi precendenti, i valori di una serie possono essere calcolati:
utilizzando i valori temporali di un datasource (locale o di altri elemnti). In questo caso sono chiamate serie normali.
utilizzando i valori di altre serie dello stesso timegraph. In questo caso sono chiamate serie calcolate.
Esempio di serie normale: Se nel datagroup e' definito il datasouce rttmax, per usarlo nella serie e' sufficiente indicare come valore dell'attributo variable value:
rttmax
Esempio di serie normale: Se esiste un datasource nel tenant con path, e' possibile specificare tutto il path:
switch1:eth0;server-linux;iface-traffic;in
Esempio di serie calcolata: Se nel timegraph sono definite due serie chiamate rttmax_serie e rttmin_serie:
sqrt( avg(rttmax_serie, rttmin_serie) + 3.14 )
Note
Quando in un timegraph sono indicate serie di entrambi i tipi, prima vengono calcolate tutte le serie normali e poi tutte le serie calcolate.
Note
Se il sistema non e' in grado di calcolare un valore per una serie calcolata per un preciso istante temporale (asse x), il valore calcolato e' nullo e non viene rappresentato nel grafico.
La sintassi per comporre le espressioni di serie calcolate e' simile a quella di qualunque funzione matematica. L'espressione puo' contenere:
numeri
operatori matematici: + , -, *, / , ec
funzioni: f(...), sin(....), max( ... ), iftrue( ... )
variabili: stringhe di testo che rappresentano un valore.
Esistono due tipi di variabili:
variabili che si riferiscono a serie
variabili speciali o built-in ricalcolate ogni volta che deve essere calcolato un singolo valore della serie.
Per maggiori dettagli come vengono calcolate le serie calcolate e su quali funzioni e quali variabili sono utilizzabili si rimanda alla sezione Timegraphs.
3.1.7.2.13. Sospensione e Riattivazione di un datagroup¶
La valutazione dei datagroup (di una qualunque entita' monitorata) puo' essere sospesa. Esistono due tipi di sospensioni:
provvisoria: si deve indicare la timeline oltre la quale viene riattivato il monitoraggio del datagroup
permanente: il monitoraggio del datagroup deve essere riabilitato manualmente.
Con la definizione sospendere un nodo si intende dire che si sospendono tutti i datagroup associati al nodo e alle sue sotto-entita'.
La sospensione di un datagroup ferma la raccolta dati (datasource), la verifica dei controlli (condition) e di conseguenza la generazione di allarmi; quindi durante i periodi di sospensione, non si ha alcuna informazione sullo stato di un elemento monitorato.
Note
Esiste un meccanismo alternativo alla sospensione chiamato "manutenzione" che non interrompe il monitoraggio ma permette di gestire nodi problematici in alcune situazioni. Si rimanda alla sezione Flag "in manutenzione" (under maintenance).
3.1.7.3. Configurazione avanzata dello scheduling¶
3.1.7.3.1. Scheduling di base (best effort)¶
Quando non specificato diversamente, i datagroup vengono schedulati per essere eseguiti ogni minperiod.
Esiste sempre un lieve overhead di elaborazione per cui l'istante di scheduling non corrisponde esattamente all'istante di inizio elaborazione.
Una volta che un agente di monitoraggio termina di elaborare (esegue) un datagroup, viene ri-schedulato calcolando l'istante temporale ( next time ) usando la semplice formula:
next_time = now + minperiod
Esempio: Datagroup con minperiod di 60 secondi (nota: nel grafico viene evidenziato il ritardo di esecuzione rispetto allo scheduled time)

Questo sistema di scheduling e' il sistema di default.
Questo sistema e' molto semplice da configurare, ma presenta il seguente problema: diversi datagroup per uno stesso nodo/cluster possono essere eseguiti nello stesso istante in parallelo causando aumento di carico sul nodo target.
Esempio: Nel seguente schema indichiamo la sequenza temporale di elaborazione di 3 datagroup (A,B,C) con tre minperiod diversi. Si possono notare dei momenti di esecuzione concorrente.
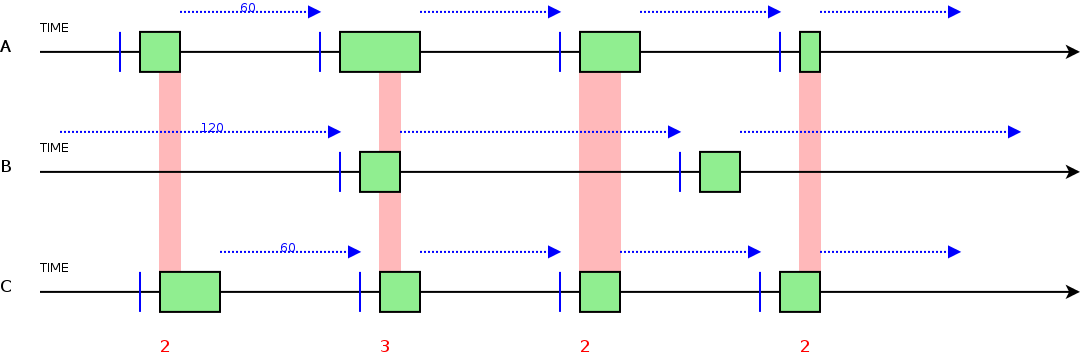
3.1.7.3.2. Scheduling avanzato: gestione di Scheduling Group¶
Uno scheduling group rappresenta logicamente un gruppo di datagroup che devono essere schedulati cercando di rispettare vincoli temporali precisi.
Esistono tre tipi di scheduling group che Sanet e' in grado di gestire e si distinguono dal modo con cui vengono configurati:
- Specificare parametri di scheduling a livello di elemento di monitoraggio (a livello di nodo, o singolo sotto-elemento)
In questo caso si dice che lo scheduling group e' definito implicitamente a livello di elemento.
- Specificare parametri di scheduling a livello di cluster.
In questo caso lo scheduling group e' definito implicitamente a livello di cluster.
- Definire uno scheduling group ed assegnare singoli datagroup (anche di nodi diversi) o elementi di monitoraggio allo scheduling group.
In questo caso la configurazione dello scheduling group e' comune a tutti gli elementi esplicitamente assegnati allo scheduling group.
Important
La gestione dello scheduling per ogni scheduling group ignora completamente l'elemento di appartenenza del datagroup. E' possibile configurare il sistema per gestire i datagroup (tutti o solo alcuni) di un nodo tramite uno scheduling group (esplicito o implicito) ed assegnare comunque i datagroup dei sotto-elementi ad altri scheduling group (impliciti o espliciti).
3.1.7.3.2.1. Parametri di scheduling¶
Il min-gap inidica la distanza minima (in secondi) che deve esistere in fase di scheduling (NON DI ESECUZIONE) tra due datagroup dello stesso scheduling group.
Specificare il valore 0 significa schedulare i datagroup uno dietro l'altro senza alcun gap aggiuntivo.
Esempio: Gruppo di due datagorup in un gruppo con min-gap impostato (10 secondi).
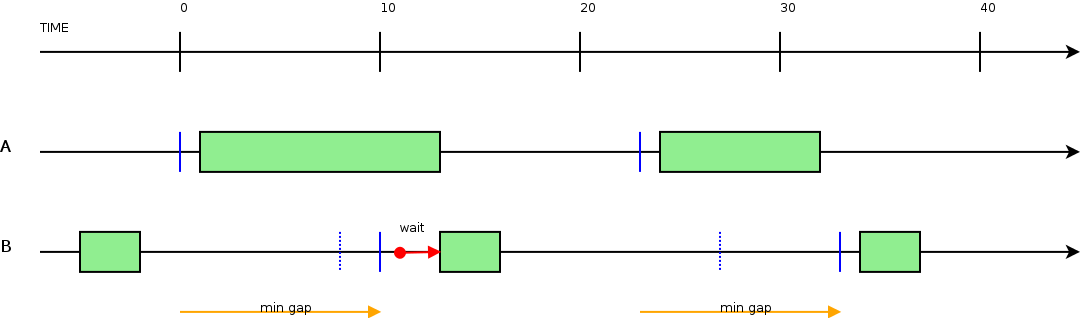
Note
In pratica, il min-gap serve per regolare il rate di datagroup da eseguire nel tempo.
Warning
Poiche' il min-gap viene utilizzato per calcolare il momento di scheduling successivo, da solo non evita l'esecuzione in parallelo di datagroup dello stesso gruppo. Vedi max-parallel.
Il tempo massimo di esecuzione di un datagroup non e' mai certo e potrebbe capitare che l'esecuzione di due datagroup di uno stesso gruppo (anche se schedulati in istanti temporali diversi in base al min-gap) si sovrapponga,
Il parametro max-parallel serve per obbligare il sistema a limitare il numero massimo di datagroup lanciati in esecuzione contemporaneamente.
Quando arriva il momento (scheduled time) di eseguire un datagroup appartenente ad un gruppo, se e' gia' stato raggiunto il limite indicato max-parallel, l'agente di monitoraggio mette in attesa (accorda) il datagroup finche' un qualunque altro datagroup dello stesso gruppo non termina l'esecuzione.
Al termine dell'esecuzione del datagroup corrente, il sistema controlla la coda di esecuzione e verifica quanti datagroup in attesa lanciare.
Specificare il valore 1 significa impedire l'esecuzione in parallelo di due datagroup dello stesso gruppo.
Note
Il numero massimo di datagroup eseguiti in parallelo da un agente e' pari al numero di thread configurati per l'agente. E' inutile configurare max-parallel con un numero superiore al numero di thread per agente.
Warning
Impostare un valore per max-parallel potrebbe causare una attesa eccessivamente lunga per i datagroup pendenti. Per forzare comunque lo "sblocco" di piu' datagroup pendenti si puo' configurare max-deadline.
Numero massimo di secondi oltre il quale non e' comunque possibile tenere in attesa un datagroup bloccato all'interno di un gruppo ( a causa del parametro max-parallel ) rispetto all'istante di scheduling.
Warning
configurand max-deadline il sistema potrebbe eseguire comunque in parallelo alcuni datagroup dello stesso gruppo.
Esempio 2: Esecuzione con min-gap (linea gialla) e max-deadline (linea viola) configurati. Come si puo' vedere, in fase di wakeup dei datagroup in pending, max-deadline forza comunque l'esecuzione del datagroup B e anche di C poiche' il max-deadline di C e' stato superato.
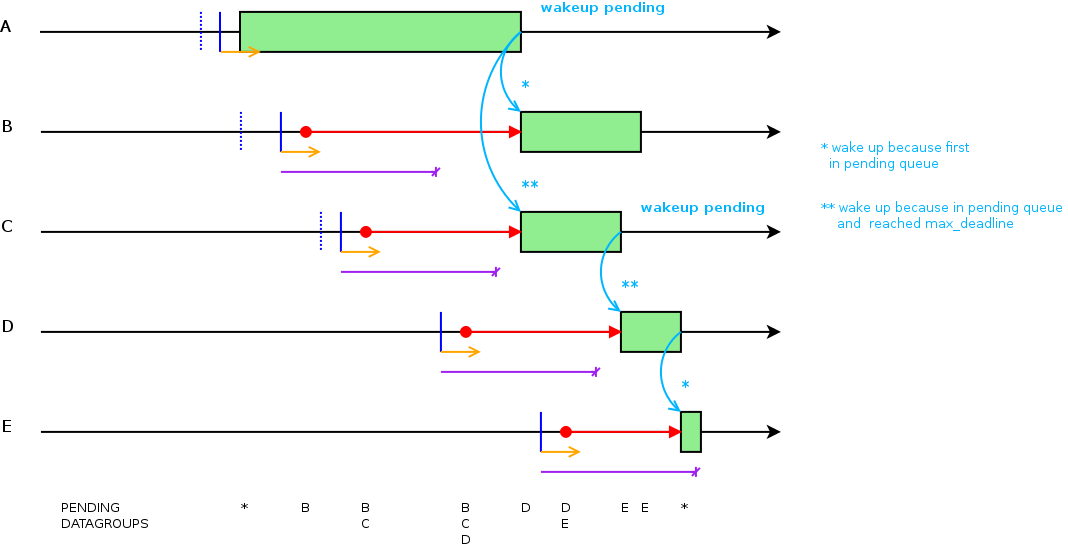
3.1.7.3.2.2. Calcolo del momento di scheduling: min_period e min_gap¶
Quando un datagroup termina la sua esecuzione, il sistema deve calcolare il prossimo momento di esecuzione.
Il sistema cerca di schedulare il datagroup partendo dal suo min-period.
Se l'istante di scheduling calcolato e' troppo vicino (min_gap) ad quello di un altro datagroup dello stesso gruppo, il tempo viene aumentato fino a trovare un istante temporale che non crei sovrapposizioni.
Warning
il parametro max-deadline non viene MAI considerato in questa fase (scheduling), ma solo nella fase di esecuzione o sblocco.
Esempio:
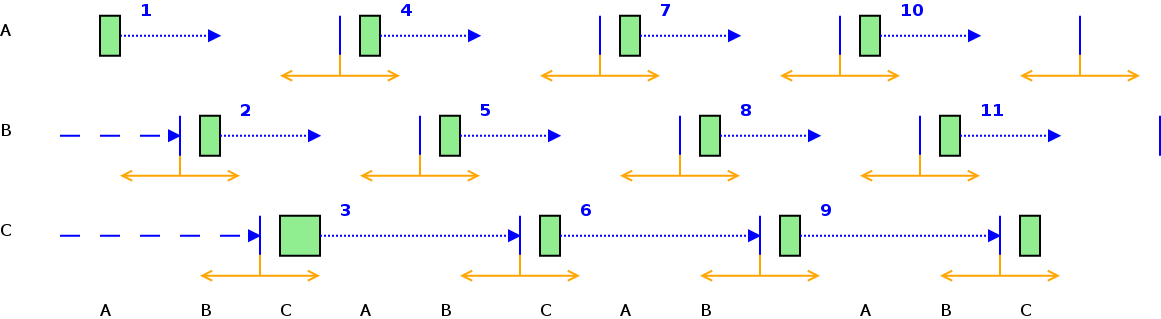
3.1.7.3.2.3. Parametri di scheduling a livello di agente¶
È possibile definire una configurazione di scheduling generale per ogni agente di monitoraggio.
Tutti i controlli dei nodi associati da un agente verranno gestiti applicando i parametri di scheduling impostati per quell'agente, solo se:
non e' gia' presente una parametrizzazione di scheduling più specifica nel cluster a cui il nodo appartiene.
non e' gia' presente una parametrizzazione di scheduling più specifica per il singolo nodo/sotto-elemento/datagroup.
I parametri di scheduling configurati a livello di agente utilizzati per creare automaticamente dei “gruppi di scheduling” nel seguente modo:
Tutti i controlli (datagroup) di tutti i nodi appartenenti ad uno stesso cluster vengono raggruppati e schedulati insieme nello stesso gruppo (gruppo automatico del cluster).
Tutti i controlli di nodo non appartenente a nessun cluster, vengono raggruppati e schedulati insieme (gruppo automatico del nodo).
3.1.7.3.2.4. Scheduling iniziale (avvio dell'agente)¶
Se sono stati configurati parametri di scheduling, all'avvio l'agente organizza temporalmente i controlli coerentemente ai parametri specificati.
In particolare tutti I controlli di un “gruppo di scheduling” vengono schedulati/intervallati rispettando il min_gap del gruppo.
3.1.7.3.2.5. Configurazione¶
Configurazione da CLI: Scheduling Group.
3.1.7.4. Datagroup da eseguire e coda di esecuzione degli Agenti¶
Dopo che un agente ha individuato (attraverso le policy di scheduling) i datagroup da eseguire, questi vengono spostati in un coda di esecuzione, in attesa che uno dei thread interni dell'agente sia pronto per eseguirlo.
CODA DI ESECUZIONE
+--------------+ |_______________________| +----------+
| | | THREAD |
[dgN] ---->| SCHEDULING |-------> .... [dg3] [dg1] [dg7] --------> | | ------+
| | _______________________ | POOL | |
^ +--------------+ | | +----------+ |
| |
| |
+------------------------------------------------------------------------------------------+
Note
Il numero di datagroup realmente in esecuzione contemporaneamente dipende dal numero di thread interni configurati per l'agente.
In situzioni molto problematiche (rete lenta, server con load average alto, ecc.) e' possibile che la coda di esecuzione si riempia di datagroup molto piu' velocemente di quanto i thread riescano ad eseguirli.
Queste situazioni sono deleterie per il monitoraggio perche' i datagroup con condition "primary" potrebbero aspettare in coda molto tempo prima di essere eseguiti, mentre in realta' solo andrebbero eseguiti "prima" degli altri (vedi configurazione delle dipenenze tra datagroup Dipendenze tra datagroup (dependson)).
Per cercare di rimediare a queste situazione la coda di esecuzione implementa una logica FIFO con priorita'.
Tutti i datagroup pronti per essere eseguiti vengono inseriti nella coda.
I datagroup con condition "primary" vengono inseriti nella coda con una priorita' piu' alta rispetto ai datagroup "normali". La priorita' viene calcolata secondo il seguente ordine
I datagroup "primary" di un nodo
I datagroup "primary" dei sotto-elementi
I datagroup "normali" del nodo o dei suoi sotto-elementi.
La priorita' assegnata si riduce nel tempo, in modo da evitare fenomeni di "starvation" dei datagroup normali rispetto a quelli "primary".
Warning
questo meccanismo si priority e' pensato per affrontare situazioni limite. In una situazione normale ("a regime") la coda il numero di datagroup in attesa/in coda di esecuzione dovrebbe rasentare lo zero.
Questa policy/gestione basata su priorita' introduce un leggero overhead di elaborazione per il fatto che l'agente deve sempre verificare la priorita' dei datagroup in coda.
Per situazioni eccezionali/debugging, e' possibile disabilitare questa policy di accodamento basata su priorita' e usare una policy puramente FIFO (First In, First Out) impostanto la variabile d'ambiente:
export SANET_AGENT_NO_QUEUE_PRIORITY=1
3.1.7.5. Datagroup Passivi¶
I datagroup passivi sono datagroup configurati con minperiod uguale a 0.
L'esecuzione di datagroup passivo viene scatenata in manieara manuale (o anche semi-automatica) e ignora completametne i normali meccanismi di scheduling basati sul minperiod e/o Scheduling Group
Important
I datagroup passivi non vengono eseguiti dagli agenti (locali e remoti) ma solo dal server centrale (attraverso un sotto processo dedicato).
Important
bisogna stare attenti alla logica dei controlli che si implementano con i datagroup passivi poiche' le informazioni che si possono racogliere dalla rete sono solo quelli che il server di Sanet e' in grado di raggiungere. Questo vale anche se il nodo che contiene il datagroup passivo e' assegnato ad un agente remoto.
I datagroup passivi servono per implementare la gestione di:
Eventi push ( vedi Eventi "Push" per monitoraggio passivo ).
Trap SNMP ( vedi Trap SNMP )
3.1.7.5.1. Passive match¶
L'attributo passive match serve per riconoscere quali datagroup passivi (tra tutti i datagroup di un nodo e/o sotto-elemento) devono essere eseguiti allo scatenarsi di un evento (un evento push ( Eventi "Push" per monitoraggio passivo ) o una trap SNMP ( Trap SNMP ) )
La stringa contenuta in passive match puo' avere due formati:
- Stringa di caratteri semplice.
Vengono gestiti dal datagroup tutti gli eventi il cui identificativo corrisponde esattamente alla stringa specificata.
Stringa con prefisso regex: :
regex:<match>La stringa dopo il prefisso viene interpretata come regular expression.
Vengono gestiti dal datagroup tutti gli eventi il cui identificatvio fa match con la regular expression
Esempi:
Identificativo evento in arrivo
Passive match configurato
Risultato
event12345
event12345
Datagroup passivo fa match e viene eseguito
event345
event12345
Datagroup passivo non fa match e NON VIENE ESEGUITO
event345
regex:^event
Datagroup passivo fa match e viene eseguito ESEGUITO
3.1.7.5.1.1. Widcard utilizzabili nel campo passive match¶
La stringa del passive match puo' contenere anche wildcard/variabili con il prefisso "$" che vengono espanse prima di effettuare il confronto.
Esempio:
Identificativo evento in arrivo
Passive match configurato
Risultato
event.fileserver.evento1
event.$node.evento1
Eseguito il datagroup sul nodo fileserver
event.eth0
event.$distinguisher
Eseguito il datagroup sull'entita' con distinguisher "eth0" (probabilmente una interfaccia)
event.^apache.*
event.$distinguisher
Eseguito il datagroup sull'entita' con distinguisher che inzia con "apache"
Nodi:
Simbolo
Descrizione
$node
nome del nodo
Interfacce:
Simbolo
Descrizione
$iface
nome dell'interfaccia
$instance
distinguisher dell'interfaccia
$distinguisher
distinguisher dell'interfaccia
Storage:
Simbolo
Descrizione
$storage
nome dello storage
$distinguisher
distinguisher dello storage
Service:
Simbolo
Descrizione
$service
nome del servizio
$distinguisher
distinguisher del servizio
Device:
Simbolo
Descrizione
$device
nome del device
$distinguisher
distinguisher del device
3.1.7.5.2. Ripristino passivo automatico (passive period)¶
Se un datagroup passivo non viene eseguito (passivamente), i suoi datasource e le sue condition non vengono mai aggiornate/verificate.
In alcuni casi, potrebbe essere utile re-impostare automaticamente lo stato delle condition di un datagroup passivo dopo un certo periodo di tempo, o analogamente storicizzare un valore di default come datasource.
Per ottenere questo risultato bisogna impostare il parametro passive period di un datagroup passivo.
Il passive period indica il numero di secondi ogni quanto un datagroup passivo viene eseguito forzatamente.
Esempio:
datagroup-template dgpassive ... ... minperiod 0 passive-match passivo ... passive-period 10 <------------- Dopo 10 secondi viene forzato il ripristino passivo ... ... exit
I datasource e le condition vengono calcolati in maniera particolare, vedi:
Attention
Il meccanismo di ripristino automatico e' pensato per "re-imporstare" una condizione particolare ed e' soggetto a molte limitazioni. Non deve essere utilizzato con la stessa logica di esecuzione periodica di un datagroup normale.
Warning
I datagroup passivi vengono SEMPRE eseguiti sul server centrale di Sanet e non dagli agenti remoti associati ai datagroup.
3.1.7.5.2.1. Valore di un datasource forzato passivamente¶
Il valore di un datasource viene forzato al valore calcolato dalla espressione specificata dal parametro passive_force_value.
Note
l'espressione puo' essere di qualunque tipo e puo' usate tutti i simboli/funzioni normalmente previsti per l'esecuzione dell'espressione specificata dal parametro expr.
Warning
il parametro "expr" viene completamente ignorato.
Esempio:
datagroup-template dgpassive ... ... minperiod 0 passive-match passivo ... ... passive-period 10 ... ... datasource ds1 ... ... expr "$var" ... ... passive-force-value 0 ---------> VALORE CALCOLATO ... ... exit exit
Se il parametro non e' specificato o l'espressione non puo' essere calcolata per qualche motivo (errore di sintassi, errore di esecuzione), il valore forzato del datasouce e' uncheckable.
Attention
attenzione all'uso di OID nelle espressioni poiche' non e' detto che il server centrale sia in grado di raggiungere il nodo interessato dal controllo.
3.1.7.5.2.2. Stato di una condition forzata passivamente¶
Lo stato di una condition viene calcolato in base al risultato della espressione specificata dal parametro passive_force_status.
Note
l'espressione puo' essere di qualunque tipo e puo' usate tutti i simboli/funzioni normalmente previsti per l'esecuzione dell'espressione specificata dal parametro expr.
Warning
il parametro "expr" viene completamente ignorato.
Esempio:
datagroup-template dgpassive ... ... minperiod 0 passive-match passivo ... ... passive-period 10 ... ... datasource ds1 ... ... expr "$var > 1" ... ... ... passive-force-status 1 <------------------ Espressione sempre vera -> stato UP exit exit
L'espressione passive_force_status viene calcolata e in base al valore viene calcolato lo stato della condition analogamente a quanto avviene per il parametro expr.
Attention
attenzione all'uso di OID nelle espressioni poiche' non e' detto che il server centrale sia in grado di raggiungere il nodo interessato dal controllo.
3.1.7.5.3. Ripristino manuale di datasource e condition¶
In alcune situazioni potrebbe essere necessario "cambiare" manualmente lo stato delle condition di un datagroup.
Questo capita tipicamente quando si vuole "ripartire" da una situazione particolare (ad esempio una situazione di stato UP) e vedere come si comporta un controllo.
E' possibile forzare manualmente lo stato UP o DOWN di un intero datagroup (cioe' di tutte o solo alcune sue condition) con il comando:
sanet-manage force_dg_status [options] <datagroup path>
Important
questo comando crea variazioni di stato salvate nel log di Sanet e la generazione di allarmi.
Warning
USARE CON CAUTELA.
Questo comando interviene direttamente sul database di Sanet e aggira qualunque meccanismo di monitoraggio e/o ripristino (automatico/semiautomatico).
Questo significa che potrebbero crearsi situazioni "temporanamente" incoerenti che Sanet risolve ritardando/ignorando aggiornamenti provenienti dagli agenti di monitoraggio (fino al prossimo ricaricamento di configurazione).
Le opzioni disponibili sono:
--status STATUS Codice dello stato: UP o DN --tenant TENANT Nome del tenant. Default: il tenant primario --reason REASON Verbstatus che comparira' nei log --conditions CONDITIONS Elenco coi nomi delle condition da aggiornare. Default: tutte. -l LOGLEVEL Livello di verbosita dell'output
Esempio:
sanet-manage force_dg_status 'localhost;;dgtrap' --reason "test" --status UP
3.1.7.6. Eventi (Log)¶
Sanet registra e memorizza in un log le informazioni legati a diversi tipi di eventi relativi agli elementi monitorati.
Gli eventi memorizzati sono di diverse tipologie:
Variazioni di stato delle condition
SNMP Trap
Eventi Syslog
Eventi custom.
Tutti questi log vengono salvati nel database di Sanet e vengono utilizzati per:
Produrre grafici temporali sull'andamento dello stato delle condition
Elaborare dati per report e statistiche
3.1.7.6.1. Storicizzazione dei log e operazione di "cancelalzione" e/o"rename"¶
Le operazioni di "cancellazione" e/o "rename" di elementi possono creare delle inconsistenze poiche' Sanet potrebbe associare erronamente (o non associare) log a elementi creati/rinominati in momenti diversi con lo stesso nome ma diversi logicamente.
- Sanet associa ad ogni log queste informazioni:
UUID dell'elemento/condition che ha generato il LOG
PATH dell'elemento/condition che ha generato il LOG
Questa gestione ha come effetto che ad un elemento vengono associati log contenenti "vecchi" nomi/path (poiche' UUID non e' cambiato).
Quando si fanno operazioni di "rename" Sanet non aggiorna automaticamente i LOG. Bisogna sempre indicare esplicitamente se si vuole aggiornare anche i "path" nei LOG.
Warning
Gli "aggiornamenti forzati" dei log sono molto costosi e quindi dovrebbero essere evitate o comunque effettuati in momenti di carico del server basso.
Gestire contemporanamente PATH e UUID e' complicato e puo' comunque produrre errori a lungo termine se le operazioni di "rename" e "cancellazione" vengono fatte in sequenze particolari.
Per retrocompatibilita' con versioni precedenti di Sanet, e' possibile indicare a Sanet di gestire i log solo in base al PATH.
EVENT_LOG_HANDLE_RENAMED = False
Warning
La modifica di questo settaggio non altera i log gia' salvati nel DB, ma solo la loro elaborazione.
Warning
Tutti i log (indipendentemente dalla gestione che ne fa Sanet) restano nel DB finche' non vengono cancellati con i comandi appositi.
3.1.7.6.2. Cause (reason) di eventi¶
Un evento (inteso come una variazione nello stato degli elementi monitorati) e' normalmente scatenato da:
cambiamenti di configurazione
manutenzione della rete (ordinaria o straordinaria)
guasti ed anomalie
Per permettere analisi a posteriori sofisticate sull'andamento del monitoraggio e' possibile definire diverse tipologie di cause o Reason.
Ogni reason e' caratterizzata dai seguenti attributi:
Attributo
Descrizione
codice
Indentificativo univoco della reason (memorizzato sul DB)
descrizione
Descrizione della reason mostrata via CLI o via WEB
colore
Colore RGB associato all reason (es. ff00ff) usato dall'interfaccia web
E' possibile specificare/modificare la causa (reason) di un evento.
3.2. Template di Configurazione¶
La configurazione degli elementi da monitorare e' basata su un sistema di templating.
Un template codifica una porzione di configurazione che viene definita una volta sola e puo' essere applicata ad un numero arbitrario di elementi.
Esistono due tipi di template:
3.2.1. Datagroup template¶
Un datagroup-template permette di specificare il valore di tutti i parametri di configurazione che un datagroup dovra' avere.
Il datagroup-template definisce:
Il nome del template, che di default, e' anche il nome di tutti datagroup creati a partire dal template.
Gli attributi/campi del datagroup
i datasource e tutti i loro attributi/campi.
i trend e tutti i loro attributi/campi.
le condition e tutti i loro attributi/campi.
i parametri opzionali (se usati).
i timegraph e tutti i loro attributi/campi e le serie.
Esempio:
datagroup-template test title "this is the title of the datagroup" parameter param1 str "12345" condition check expr "readFile('/tmp/test.txt') == $param1" exit exit
3.2.1.1. Nome di un datagroup-template¶
Ogni datagroup-template e' identificato da un nome univoco (o all'interno di un tenant o della library).
Note
il nome e' univoco all'interno dello stesso tenant o nella library, ma puo' esistere una configurazione con due template con lo stesso nome, ma definiti rispettivamente nella library e in ogni tenant.
Il nome di un datagroup-template deve rispettare la seguente espressione regolare:
^[a-zA-Z][a-zA-Z0-9-_]*$
3.2.1.2. Ereditarieta' e gerarchia di datagroup template¶
E' possibile creare un datagroup-template a partire da un datagroup-template gia' definito; in questo caso il primo e' chiamato datagroup-template figlio, mentre il secondo e' chiamato datagroup-template padre.
Quando un datagroup-template viene definitio a partire da un datagroup-template esistente e' possibile:
sovrascrivere il valore di uno degli attributi del datagroup-template.
sovrascrivere il valore degli attributi dei datasource/trend/condition/timegraph/parametro gia' esistente.
aggiungere nuovi datasource/condition/timegraph/parametro a quelli gia' definiti.
Esempio di gerarchia e modifica di attributi:
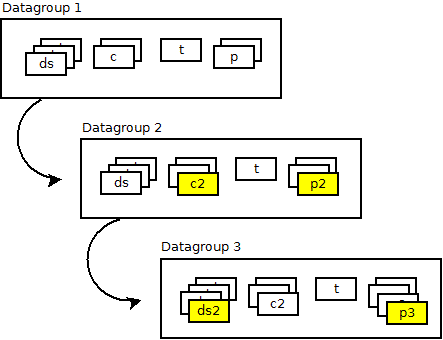
Esempio:
datagroup-template dg1 parameter param1 str "12345" condition check1 ... exit exit datagroup-template dg2 parent dg1 parameter param1 str "67890" # Il valore "12345"| del parametro viene sovrascritto con il valore "67890". condition check2 # check2 viene aggiunto esplicitamente, mentre "check1" e' ereditato implicitamente. ... exit exit
3.2.1.3. Attributo "deleted"¶
Il sistema di eriditarieta' e' di tipo additivo, ovvero e' possibile SOLO aggiungere nuovi elementi (condition/datasource/ecc.) ad un datagroup-template che si sta estendendo.
Puo' succedere che un determinato datagroup-template non sia applicabile esattamente ed interamente ad un elemento monitorabile. Alcuni datasource o condition potrebbero non avere senso o non essere applicabili (perche' l'apparto non implementa alcune MIB SNMP, ecc.).
Poiche' non si puo' definire un datagroup-template con l'intenzione di togliere attributi/sotto-elementi, si puo' risolvere il problema in due modi:
Definire un datagroup-template nuovo che non definisce i datasource/condition non applicabili.
Estendere un datagroup-template gia' esistente marcando alcune sotto-entita' come deleted.
Quando una condition/datasource/ecc. e' marcato come deleted viene semplicemente ignorato dal monitoraggio.
Esempio:
datagroup-template dg1 condition check1 ... exit condition check2 ... exit exit datagroup-template dg2 parent dg1 condition check2 # La condition "check1" resta attiva, mentre "check2" viene "ignorata" dal monitoraggio. deleted true exit exit
3.2.1.4. Configurazione¶
CLI: si rimanda alla sezione: Datagroup Template
WEB: La configurazione via web dei template non e' disponibile.
3.2.1.5. Assegnare un datagroup-template ad un elemento di monitoraggio¶
Per creare un datagroup bisogna associare un datagroup-template ad un elemento di monitoraggio (nodo, interfaccia, ecc.).
E' possibile istanziare (associare) un datagroup-template in un elemento di monitoraggio in due modi:
associare direttamente il datagroup-template all'elemento di monitoraggio: Datagroup diretti.
Utilizzare un element template: Element template.
3.2.1.5.1. Datagroup diretti¶
Quando si associa un datagroup template ad un elmento di monitoraggio si creano i datagroup diretti.
Ogni datagroup diretto (istanza di un datagroup datagroup-template) ha un nome che puo' essere:
un nome uguale a quello del datagroup-template corrispondente.
un nome personalizzato.
Esempio:
datagroup-template dg1 ... exit node localhost datagroup dg1 # Datagroup's name is equal to template's name exit datagroup dummy template dg1 # Custom name for the datagroup created from template 'dg1' exit exit
Tutti i datagroup diretti devono avere nomi univoci all'interno dello stesso elemento di monitoraggio.
Note
Ci puo' essere un solo datagroup con nome uguale a quello del suo datagroup-template; altri datagroup istanziati dallo stesso datagroup-template dovranno specificare per forza un nome personalizzato.
Esempio:
node localhost datagroup dg1 # OK. L'uso del datagroup-template dg1 e' implicito. exit datagroup dg1 template dg1 # ERRORE: Il nome "dg1" e' gia' stato usato nel primo datagroup exit datagroup dummy template dg1 # OK: questo datagroup ha nome "dummy" e no entra in conflitto con la configurazione precedente. exit exit
I datagroup diretti possono essere personalizzati modificando i singoli attributi del datagroup o i parametri opzionali.
Important
non e' possibile aggiungere definizione di datasource/condition/timegraph ad un datagroup.
Esempio:
datagroup-template dg1 ... parameter threshold num 0.75 ... condition check ... minperiod 60 ... exit exit node localhost datagroup dg1 parameter threshold num 0.71 condition check # OK, personalizzato il minperiod della condition solo per il nodo localhost minperiod 61 exit condition check2 # ERRORE: la condition check2 non e' definita nel template e non puo' essere aggiunta/modificata minperiod 61 exit exit exit
3.2.1.5.2. Configurazione¶
CLI: Si rimanda alla sezione: Datagroup diretti.
WEB: non disponibile
3.2.2. Element template¶
Un element template permette di specificare un blocco di configurazione che deve essere applicata ad uno o piu' elementi di monitoraggio.
E' possibile create element template per ogni tipologia di elemento monitorabile:
node template
interface template
storage template
service template
device template
Esempio:
node-template server-linux ... exit interface-template eth100 ... exit storage-template ext4-partition ... exit service-template apache2-base ... exit device-template fan-generic ... exit
Un element template permette di specificare:
parametri di configurazione specifici per la tipologia di entita' corrispondente al template (snmp-port, snmp-version, flags, priority, xform, distinguisher, ecc.)
un elenco di datagroup da creare automaticamente per elemento di monitoraggio, indicato quali datagroup-template assegnare e con quale nome. Vedi Specificare un datagroup all'interno di un element template.
un elenco di sotto-elementi (interfacce, dischi, servizi, device) che devono essere creati automaticamente in fase di assegnamento del template all'elemento di monitoraggio.
Questo e' possibile solo per i node template. Vedi Sotto-elementi all'interno di un node-template.
E' possibile associare piu' di un element template (purche' tutti diversi) alla stessa entita' di monitoraggio.
Important
Eventuali conflitti verranno segnalati e/o impediti: (A) a datagroup con lo stesso nome definiti in due element template associati alla stessa entita; (B) conflitti tra nomi di sub-entita' definite nei nodi o in node-template gia' applicati.
3.2.2.1. Node template¶
I node template permettono di specificare:
datagroup-template da applicate
valori dei parametri dei nodi
I parametri che e' possibile specificare sono:
Campo
Descrizione
icon
priority
is-abstract
dft-timeout
notify-address
Campo
Descrizione
is-switch
is-router
use-ipv4
snmp-port
snmp-version
snmp-community
snmp-v3-authdata
Esempio:
node-template ... icon ... is-abstract ... priority ... notify-address ... is-router ... is-switch ... use-ipv4 ... snmp-community ... snmp-port ... snmp-v3-authdata ... snmp-version ... dft-timeout ... exit
Oltre ai singoli parametri un node-template puo' anche specificare sotto-elementi di monitoraggio che verranno creati automaticamente in fase di applicazione del template. Vedi Sotto-elementi all'interno di un node-template.
3.2.2.2. Interface template¶
Gli interface template permettono di specificare:
datagroup-template da applicate
valori dei campi specifici dell'elemento
I parametri che e' possibile specificare sono
Campo
Descrizione
icon
priority
is-abstract
dft-timeout
notify-address
Campo
Descrizione
distinguisher
xform
speed
backbone
Esempio:
interface-template ... icon ... is-abstract ... notify-address ... priority ... distinguisher ... xform ... backbone ... speed ... exit
3.2.2.3. Storage template¶
Gli interface template permettono di specificare:
datagroup-template da applicate
valori dei parametri dei nodi
I parametri che e' possibile specificare sono
Campo
Descrizione
icon
priority
is-abstract
dft-timeout
notify-address
Campo
Descrizione
distinguisher
xform
speed
backbone
Esempio:
storage-template ... icon ... is-abstract ... notify-address ... priority ... distinguisher ... xform ... exit
3.2.2.4. Service template¶
Gli interface template permettono di specificare:
datagroup-template da applicate
valori dei parametri dei nodi
I parametri che e' possibile specificare sono
Campo
Descrizione
icon
priority
is-abstract
dft-timeout
notify-address
Campo
Descrizione
distinguisher
xform
Esempio:
service-template ... icon ... is-abstract ... notify-address ... priority ... distinguisher ... xform ... exit
3.2.2.5. Device template¶
Gli interface template permettono di specificare:
datagroup-template da applicate
valori dei parametri dei nodi
I parametri che e' possibile specificare sono
Campo
Descrizione
icon
priority
is-abstract
dft-timeout
notify-address
Campo
Descrizione
distinguisher
xform
Esempio:
device-template ... icon ... is-abstract ... notify-address ... priority ... distinguisher ... xform ... exit
3.2.2.6. Specificare un datagroup all'interno di un element template¶
All'interno di un element template, ogni datagroup da utilizzare viene specificato indicando il datagroup template e facoltativamente, il nome con cui istanziarlo (per evitare nomi duplicati invalidi).
Esempio:
node-template server-linux datagroup icmp-reachability template icmp-reachability exit datagroup cpu-hr exit exit
E possibile assegnare piu' volte un datagroup-template in un element-template, purche' venga cambiato il nome (ed eventualmente cambiando parametrizzazioni del datagroup).
Esempio: due datagroup-template (ta, tb) vengono utilizzati all'intenro di un element template (et1). Per il datagroup-template "ta" vengono usati due nomi diversi: ta e ta2.
datagroup-template ta ... exit datagroup-template tb ... exit node-template foo datagroup ta exit datagroup ta2 template ta exit datagroup tb exit exit datagroup-template element-template +-------------------+ | foo | | | +-----------+ | +-----------+ | | ta |---------+----------->| ta | | +-----------+ | | +-----------+ | | | | | | +-----------+ | +----------->| ta2 | | | +-----------+ | | | +-----------+ | +-----------+ | | tb | -------------------->| tb | | +-----------+ | +-----------+ | | | +-------------------+
Per ogni datagroup specificato e' possibile svorascrivere i parametri di configurazione previsti dal datagroup-template (datasource, condition, parametri opzionali).
Esempio:
datagroup-template foo ... parameter param1 str "xxx" ... condition check ... priority 10 ... exit exit node-template foo datagroup foo1 template foo parameter param1 str "111" # personalizzato il valore del parametro exit datagroup foo2 template foo parameter param1 str "222" # personalizzato il valore del parametro condition check priority 80 # personalizzata la priority della condition exit exit exit
Attention
non e' MAI possibile aggiungere nuovi datasource/datagroup/timegraph ad un datagroup all'interno di un element template. E' possibile SOLO sovrascrivere configurazioni gia' presenti nel datagroup-template.
3.2.2.7. Applicare element template multipli ad un elemento di monitoraggio¶
E' possibile applicare (direttamente o indirettamente) piu' di un element-template allo stesso elemento di monitoraggio.
Esempio 1: Applico ad un nodo due node-template.
# TEMPLATE node-template server-base ... exit node-template server-linux ... exit # NODI node localhost template server-base template server-linux exit
3.2.2.7.1. Ordine di applicazione e valore degli attributi di un elemento di monitoraggio¶
Se due template specificano lo stesso campo e vengono assegnati allo stesso elemento, il valore del campo effettivamente applicato e' quello dell'ultimo template applicato in ordine di configurazione.
Vale l'ultimo valore configurato in ordine di applicazione dei template.
Esempio: Il campo "icon" del nodo "localhost" vale "linux". Il campo "icon" del nodo "db-server-1" vale "oracle".
# TEMPLATE node-template server-base icon node exit node-template server-linux icon linux exit node-template server-oracle icon oracle exit # NODI node localhost template server-base template server-linux exit node db-server-1 template server-linux template server-oracle exit
Important
se due element template dichiarano di utilizzare lo stesso datagroup template, e vengono applicati alla stessa entita', il sistema crea due datagroup distinti e non effettua alcun controllo sulla presenza di due due datagroup simili nella configurazione generata.
3.2.2.8. Sotto-elementi all'interno di un node-template¶
All'interno di un node-template e' possibile specificare quali entita' devono essere automaticamente create quando il template verra' applicato ad un nodo.
Queste entita' vengono chiamate sub-element template (perche' sono a tutti gli effetti dei template di configurazione per creare elementi di monitoraggio).
E' possibile specificare uno o piu' sub-element template per queste tipologie di element di monitoraggio:
interfacce
storage
service
device
Important
il node-template e' l'unico element template che permette di specificare sotto-elementi.
Esempio: In questo esempio, all'interno del nodo locahost verra' creata automaticamente una interfaccia eth0 poiche' e' definita nel template base-server.
node-template base-server ... interface eth0 ... exit ... exit node localhost template base-server exit
Per ogni sotto-elemento che si vuole specificare all'interno di un node template, e' possibile specificare:
nome dell'entita
Campi specifici dell'elemento (gli stessi valorizzabili tramite un element-template) * icon * priority * dft-timeout * is-abstract * distinguisher * xform * backbone (interfacce) * speed (interfacce)
uno o piu' datagroup aggiuntivi
uno o piu' element template da applicare all'entita' creata (e l'ordine con cui applicarli)
3.2.2.8.1. Configurare campi nei sub-element template¶
E' possibile specificare i default dei campi di un sub-element template.
Esempio: Configuro il subelement-template eth0 specificando alcuni dei campi previsti per le interfacce.
node-template base-server interface eth0 distinguisher enp0s3 xform ifdescr speed 100 icon eth10 exit exit node localhost template base-server exit
E' comunque possibile sovrascrivere la configurazione puntualmente sull'interfaccia eth0 dentro il nodo (creata in base al template base-server).
node localhost ... template base-server ... template-interface eth0 # Sovrascrivo le parametrizzazioni ereditate da *base-server:eth0* distinguisher enp0s3000 speed 1000 exit ... exit
3.2.2.8.2. Specificare datagroup aggiuntivi in un subelement template¶
Esattamente come per un element template normale (node-template, interface-template, storage-template, ecc.), e' possibile specificare datagroup-template nei sub-element template.
Questi datagroup template verranno applicati automaticamente quando l'elemento corrispondente verra' creato.
Esempio:
datagroup-template test ... exit node-template base-server interface eth0 datagroup test1 template test minperiod 1800 exit exit exit
Per modificare la configurazione del datagroup puntualmente nel nodo di monitoraggio devo entrare nella configurazione
node localhost template base-server template-interface eth0 template-datagroup test from base-server:eth0 minperiod 111 exit template-datagroup test minperiod 111 exit exit exit
3.2.2.8.3. Assegnare element-template ad un sub-element template¶
Ad un sub-element template e' possibile associare non solo datagroup template, ma anche altri element-template della stessa tipologia.
Esempio: Al sub-element template eth0 specifico i template iface-base a iface-customer. Questi template verranno automaticamente assegnati alle interfacce create quando viene applicato il template base-server ai nodi di monitoraggio.
# # # datagroup-template iface-status ... exit datagroup-template test-custom ... exit # # INTERFACE TEMPLATE # interface-template iface-base datagroup iface-status exit exit interface-template iface-customer datagroup test-custom exit exit # # NODE TEMPLATE # node-template base-server interface eth0 template iface-base template iface-customer exit exit # # NODI # node localhost template base-server exit
E' possibile personalizzare dentro un sub-element template i datagroup usati all'interno dei template associati.
node-template base-server ... ... interface eth0 template iface-base <-----------------------. template iface-customer <-----------------------|---. ... | | ... | | template-datagroup iface-status from iface-base ---' | minperiod 600 | exit | | template-datagroup test-custom from iface-customer ---' minperiod 600 exit ... ... exit ... ... exit
Analogamente e' possibile sovrascrivere la configurazione dentro l'elemento di monitoraggio:
node-template base-server ... ... interface eth0 template iface-base <-----------------------. template iface-customer <-----------------------|---. ... | | ... | | template-datagroup iface-status from iface-base ---' | <---. minperiod 600 | | exit | | | | template-datagroup test-custom from iface-customer ---' | minperiod 600 | exit | ... | ... | exit | ... | ... | exit | | | node localhost | | template base-server | | template-interface eth0 | | template-datagroup iface-status from iface-base -------------' minperiod 600 exit exit exit
Warning
il sistema impedisce che si creino conflitti tra i nomi delle entita' create automaticamente in base alla definizione di un template applicato ad almeno un nodo ed i nomi delle entita' create manualmente all'interno di quel nodo. I comandi di configurazione che generano conflitti verrano annullati con un errore.
3.2.2.8.4. Configurazioni specifiche dei sotto-elementi creati da sub-element template¶
La configurazione di sotto-elementi (interface,storage,service,device) generati in base alla definizione specificata dentro un node-template puo' essere modificata:
aggiungendo il riferimento ad altri element template direttamente all'oggetto del monitoraggio.
aggiungendo altri datagroup-template diretti all'oggetto del monitoraggio.
Esempio:
node-template base-server ... interface eth0 ... exit ... exit node localhost template base-server template-interface eth0 template iface-custom # Nuovo interface-template assegnato puntualmente all'elemento di monitoraggio *localhost:eth0* datagroup custom template dg-custom # Nuovo datagroup-template assegnato puntualmente all'elemento di monitoraggio *localhost:eth0* con il nome *custom*. exit exit exit
3.2.2.8.5. Configurazione¶
CLI: si rimanda alla sezione: Element Template
WEB: La configurazione via web dei template non e' disponibile.
3.2.2.9. Ereditarieta' negli element-template¶
Gli element-template, analogamente ai datagroup-template possono essere configurati in un gerarchia di template.
Un element-template (figlio) estende un element-template (padre) :
sovrascrivendo o aggiungendo.
sovrascrivendo o aggiungendo datagroup del template.
aggiugendo sub-element template.
sovrascrivendo campi di sub-element template.
sovrascrivendo datagroup del sub-element template.
aggiungendo template applicati a sub-element template
Esempio:
node-template base-server icon node datatagroup icmp-reachability exit interface eth0 datagroup iface-status exit exit exit node-template apache-server parent base-server icon www datatagroup icmp-reachability priority 10 exit interface eth0 datagroup iface-status priority 10 exit exit datatagroup cpu-hr * NUOVO * exit service apache * NUOVO * datagroup tcp-port exit exit exit
3.2.3. Template di configurazione locali e Library¶
I template (datagroup template o element template) si possono dividere in due tipologie:
locali : sono definiti solo in un particolare tenant.
library : sono definiti globalmente nel sistema e sono utilizzabili in tutti i tenant.
I template della library sono indentificati univocamente dal nome in tutta l'installazione.
I template definiti nel tenant sono identificati dal nome che e' univoco solo all'interno del tenant.
Due tenant diversi possono definire template locali con lo stesso nome, ma completamente diversi.
I template locali ad un tenant possono estendere/sovrascrivere le configurazioni di template nella "library".
I template in library non possono essere essere usati/estesi direttamente; deve sempre esistere un template locale che ha come parent il template in library.
Important
Ogni volta che in un tenant si tenta di estendere un template definito solo in "library", il sistema crea automaticamente nel tenant un template "locale" con lo stesso nome che eredita (ha come parent) quello definito nella library.
Warning
Il sistema non permette di creare template in library se esiste gia' un template in un tenant con lo stesso nome.
Note
La definizione di template nella library ha senso se si intendere "riutilizzare" lo stesso template in tenant diversi o in altre installazioni, ma e' possibile configurare un intero sistema senza utilizzare la library. E' una scelta possibile. Spetta all'amministratore del sistema decidere cosa deve o non deve essere memorizzato nella library.
Esempio: i datagroup-template dt1 e dt2 sono definiti in library. Per essere usati/assegnati al nodo n1 vengono "replicati" nel tenant. In maniera analoga il node-template nt viene replicato nel tenant prima di poter essere assegnato al nodo n2.
+-----------+ | nt | +-----+ +-----+ | +-----+ | | dt1 | | dt2 |<---------------| AAA | | +-----+ +-----+ | +-----+ | ^ ^ +-----^-----+ | | ^ | | | | | LIBRARY ========|=================|==================|===|========================================================= | | | | TENANT | | +-----|-----+ | | | nt | | +-----+ +-----+ | +-----+ | | dt1 |<.... | dt2 |<...... | | AAA | | +-----+ : +-----+ : | +-----+ | ^ : ^ : +------^----+ : : : : ^ : : : : : : : +------------------+ : : : : : : | nt | : : : : : : | +-----+ | : :.........:.........:.......:.....:...............|..| BBB | | : : : : : | +-----+ | : : : : : | ^ +-----+ | : : :.......:.....:....................:.....| CCC | | : : : : | : +-----+ | : : : : +----:-------^-----+ : : : : : ^ : : : : : : : : : : : : ...... : :..... : : : : : : : : +------+ : +------+ : : +------+ : : | n1 | : | n2 | : : | n3 | : : +------+ : +------+ : : +------+ : : / \ : \ : : / \ : : / \ : \ : : / \ : : / \ : \ : . / \ : [ dg1 ] [ dg2 ] [ AAA ] [ BBB ] [ CCC ]
3.2.3.1. Configurazione¶
CLI: si rimanda alla sezione: Configurazione Library
WEB: La configurazione via web dei template non e' disponibile.
3.2.4. Best practice nell'uso dei template¶
Poiche' la gestione delle configurazioni tramite template e' gerarchica e basata su un meccanismo di ereditarieta', le operazioni di aggiornamento/modifca possono essere anche molto costose in termini di tempo/CPU.
E' opportuno seguire le seguenti regole:
Se si sta creando un nuovo datagroup-template e si vuole testare il suo funzionamento e' VIVAMENTE CONSIGLIATO di associare il datagroup direttamente ad UN SOLO elemento di monitoraggio e provarlo.
Evitare, se possibile, di cancellare/aggiungere datasource/condition/timegraph a datagroup-template gia' esistente e associato a molti elementi di monitoraggio.
Evitare, se possibile, di cancellare/aggiungere sub-element template a node-template.
Non reimpotare la library interamente da file, ma importare solo i datagroup template mancanti.
3.3. Monitoraggio dei nodi¶
3.3.1. Parametri di monitoraggio¶
Un nodo e' caratterizzato dalle seguenti informazioni:
Dato
Descrizione
description
Descrizione dell'elemento
switch
(flag si/no) indica se il nodo ha funzionalita' di switching
router
(flag si/no) indica se il nodo ha funzionalita' di routing
icon
icona usata dall'interfaccia web
Note
I flag switch e router sono due flag puramente informativi e non influiscono in nessuno modo sul monitoraggio.
Esistono altri attributi per il momento secondari:
Dato
Default
Descrizione
priorita'
Priorita' di default delle condition associate (se non specificato diversamente)
flag ipv4/ipv6
false
Flag vero/falso per indicare se utilizzare protocollo IPv6 come protocollo di rete di default per questo nodo (default IPv4)
Nome Dns
(facoltativo) Nome Dns da utilizzare se diverso dal nome associato al nodo
Nome DNS ipv6
(facoltativo) Nome Dns da utilizzare se diverso dal nome associato al nodo
IP (v4)
(facoltativo) Indirizzo IPv4 da utilizzare per il monitoraggio
IP (v6)
(facoltativo) Indirizzo Ipv6 da utilizzare per il monitoraggio
Timezone
(facoltativo) Timezone associata a questo nodo
SNMP versione
1
Versione del protocollo SNMP. Valori ammessi 1,2,3. Il valore 0 disabilita l'invio di richieste verso SNMP verso il nodo.
SNMP port
161
Porta SNMP (default 161)
SNMP community
public
Community SNMP
SNMP v3 AuthData
Striga di configurazione parametri V3. Vedi Configurazione SNMPv3
Default Timeout
1
Timeout di default da utilizzare per i controlli associati a questo nodo
Notify Address
Indirizzo di notifica utilizzato per segnalare anomalie non gestite (Trap SNMP o altro)
3.3.1.1. Nome del nodo e identificativo effettivo¶
E' preferibile che tutti gli apparati/server monitorati siano registrati/inventariati presso un DNS (anche locale sulla stessa macchina dove e' installato Sanet), ma in certi scenari un nodo potrebbe non essere registrato:
Non si a' controllo del DNS, ma c'e' comunque necessita' di monitorare il nodo.
Il nodo appartiene ad una rete esterna monitorata attraverso un agente remoto
ecc.
In fase di monitoraggio bisogna distinguere tra nome del nodo e identificativo effettivo del nodo:
nome e' il nome assegnato in Sanet.
identificativo effettivo e' il nome (hostname) o indirizzo IP realmente usato da Sanet per il monitoraggio.
L'identificativo effettivo viene calcolato in questo modo:
Se il flag IPv4 e' vero:
Se l'indirizzo IP e' specificato usa quello
Se il nome DNS e' specificato usa quello
Usa il nome del nodo in Sanet (quindi il nome del nodo deve essere risolvibile in IPv4: file hosts o record A)
Se il flag IPv4 e' falso:
Se l'indirizzo IPv6 e' specificato usa quello
Se il nome DNSv6 e' specificato usa quello
Usa il nome del nodo in Sanet (quindi il nome del nodo deve essere risolvibile in IPv6: file hosts o record AAAA)
IMPORTANTE: Questa logica altera anche le variabili utilizzabili nelle espressioni di monitoraggio di sanet. Si veda: Built-in node's variables.
3.3.2. Configurazione protocollo SNMP¶
3.3.2.1. Configurazione SNMPv3¶
Danger
a causa di problemi nel pacchetto NET-SNMP ufficiale (binding python) il supporto per il protocollo SNMPv3 e' instabile e puo' causare crash (con probabile terminazione) dei processi agenti che eseguono operazioni utilizzano il protocollo SNMPv3. Se si ha necessita' di monitorare nodi con SNMPv3 e' consigliabile creare un agente ad-hoc in modo che eventuali crash non impattino sul monitoraggio del resto del sistema.
Quando si intende monitorare dei nodi attraverso il protocollo SNMPv3 e' necessario configurare i parametri "Snmp V3 AuthData".
Important
Per motivi di retrocompatibilita con vecchie versioni di Sanet, se il campo "Snmp V3 AuthData" non e' valorizzato, il sistema cerca di usare come stringa di configurazione, la stringa cntentuta nel campo "SNMP Community".
La stringa di configurazione deve rispettare una sintassi particolare che serve per specificare tutti i parametri di sicurezza/autenticazione previsti dal SNMPv3.
Si rimanda alla sezione: Opzioni SNMPv3.
3.3.2.1.1. Opzioni SNMPv3¶
La stringa di configurazione delle opzioni SNMPv3 deve rispettare la seguente sintassi:
<option> : <value> [ , <option> : <value> ]*
Important
La stringa e' CASE SENSITIVE
La option puo' essere una delle seguenti:
Opzione
Descrizione
Valori ammessi
Default
context
Context Name
stringa
''
username
Securety Name
stringa
'initial'
sec_level
Security Level
noauth, auth, crypt
noauth
auth_proto
Authentication protocol
md5,sha,sha1,sha224,sha256,sha384,sha512
md5
auth_pass
Authentication passphrase
stringa
crypt_proto
Privacy protocol
des,aes,aes128,aes192,aes256,aes192c,aes256c
des
crypt_pass
Privacy passphrase
stringa
Le opzioni auth_proto e auth_pass sono richieste quando sec_level e' valorizzato a auth or crypt.
Le opzioni crypt_proto e crypt_pass sono richieste quando sec_level e' valorizzato a crypt.
Esempio 1: Esempi di stringhe
context:mycontext sec_level:auth,username:foo,auth_proto:md5,auth_pass:mypassword sec_level:noauth,context:mycontext
Esempio 2: Esempio di configurazione di un nodo
node localhost snmp-version 3 snmp-v3-authdata sec_level:auth,username:foo,auth_proto:md5,auth_pass:mypassword exit
3.3.2.2. Disabilitare completamente SNMP¶
La versione SNMP configurata di default e' la 1.
In alcuni contesti (interfaccia web, CLI) Sanet utilizza il protocollo SNMP per ottenere on-demand informazioni sul nodo o i suoi apparati.
Se si desidera disabilitare completamente qualunque uso del protocollo SNMP bisogna impostare a 0 il numero di versione SNMP.
Impostare a 0 la versione comporta:
Qualunque dato SNMP richiesta da Sanet avra' valore nullo (null o none). Questo valore e' diverso da stringa vuota ('').
Datasource e Condition basati su SNMP verranno eseguiti, ma con buona probabilita' termineranno con stato UNCHECKABLE.
3.3.3. Raggruppamento di nodi in Cluster¶
Alcuni apparati non possono essere monitorati direttamente (via SNMP o altri protocolli) ma solamente interrogando altri apparati.
- Lo scenario e' il seguente:
Esiste una serie nodi che vogliamo monitorare ma non interrogabili direttamente.
Esiste una serie di nodi che espongono i dati di monitoraggio
in un dato istante le informazioni di un nodo del primo gruppo sono mantenute da un preciso nodo del secondo gruppo.
Questo capita nel caso di:
Access Point con Wireless Controller
Cluster di virtualizzazione con i dati sulle macchine virtuali reperibili interrogando le macchine di virtualizzazione e non le macchine guest.
Per gestire in maniera "elastica" questi particolari apparati Sanet supporta quella che abbiamo definito "gestione di cluster di nodi".
Un cluster e' un un raggruppamento logico di nodi del monitoraggio identificato da:
nome univoco
dati aggiuntivi
I cluster possono essere pensati come insiemi disgiunti di nodi quindi valgono le seguenti regole regole:
Possono essere definiti un numero arbitrario di cluster.
E' possibile associare un nodo ad un solo cluster alla volta.
![digraph prova {
imagepath="/opt/sanet3/static/webui/images/resources/";
subgraph cluster1 {
label="cluster 1";
wc1 -> ap1;
wc1 -> ap2;
wc1 -> ap3;
}
subgraph cluster2 {
label="cluster 2";
wc2 -> ap4;
wc2 -> ap5;
}
wc2 -> ap3 [color = red, label = "no"];
}](../_images/graphviz-8174e52260900e9d6b32f1942833fed0d63281db.png)
3.3.3.1. Ruoli e associazione in un cluster¶
All'interno di un cluster le entita' possono essere di due tipi:
MASTER : sono le entita' logicamente principali o piu' importanti. Espongono le informazioni di monitoraggio degli altri nodi del cluster (DEPENDENT).
DEPENDENT: entita' logicamente dipendenti dalle entita' MASTER.
Alcuni esempi:
Wireless Controller e Access Point
Controller e' un MASTER
Access Point e' un DEPENDENT
Cluster VMWare
Le macchine host (o hypervisor) sono MASTER
Le macchine guest sono DEPENDENT
Quando un MASTER esponde le informazioni di un DEPENDENT, si dice che il DEPENDENT e' associato al MASTER.
Warning
Tutti i nodi raggruppati in un cluster (MASTER e DEPENDENT) devono essere monitorati (assegnati) dallo stesso agente. E' da tenere presente questo vincolo quando si deve scegliere quali agenti definit/utilizzare e quali gruppi di nodi monitorare con lo stesso agente.
3.3.3.2. Configurazione nodi DEPENDENT¶
Ogni nodo DEPENDENT del cluster deve essere configurato in maniera tale che Sanet sappia come verificare se esiste un'associazione tra il nodo stesso e uno dei MASTER del cluster.
Per fare questo e' necessario parametrizzare correttamente i seguenti campi del nodo:
cluster-distinguisher
Questo campo serve per memorizzare una stringa da utilizzare per identificare univocamente il nodo all'interno del cluster.
Note
il valore di questo campo e' arbitrario. Nel caso di access point di solito e' frequente pensare al MAC address come un buon candidato ad essere usato come cluster_distinguisher.
Quando questo campo e' valorizzato, Sanet permette di richiamarne il valore in qualunque espressione attraverso la variabile $cluster_distinguisher.
cluster-xform
Questo campo deve contenere l'espressione che SANET valutera' per controllare se il nodo e' associato ad uno dei nodi del cluster.
La variabile $cluster_distinguisher dovrebbe essere utilizzata all'interno dell'espressione (ma non e' obbligatorio).
L'espressione cluster-xform viene eseguita su ogni nodo MASTER del cluster. Se la valutazione restituisce un risultato l'associazione con il nodo del cluster e' verificata. Il risultato calcolato viene chiamato cluster-instance e puo' essere usato successivamente per trovare le informazioni del nodo sul MASTER che ha verificato l'associazione.
Esempio:
cluster-distinguisher -> 00260BAC5E60 cluster-xform -> byBinaryValue( 1.3.6.1.4.1.14179.2.2.1.1.1@ , $cluster_distinguisher )
In questo esempio stiamo indicando di usare la funzione byBinaryValue() per cercare nelle MIB 1.3.6.1.4.1.14179.2.2.1.1.1 di tutti i nodi MASTER del cluster un OID che contenga il valore binario 00260BAC5E60. Se viente trovato l'OID con quel valore, l'associazione e' verificata.
3.3.3.3. Quando viene effettivamente calcolata l'associazione?¶
Per motivi di performance la gestione/controller del cluster viene attivata solo se un datagroup utilizza delle espressioni che hanno effettivamente bisogno di dati utilizzando questo meccanismo.
Anche se uno nodo e' stato configurato con un certo cluster-distinguisher e cluster-xform, se un datagroup NON utilizza funzioni o variabili che coinvolgono la gestione a cluster, l'associazione non viene controllata!!!
3.3.3.4. Log delle associazioni¶
Quando viene verificata una associazione ad un cluster, Sanet salva nel log degli event una entry con informazioni sulla verifica dell'associazione:
Esempio: vedi righe con TYPE uguale a ASS (association).
cli:admin@site>show log ID TIME TYPE ELEMENT INFO OLD NEW F U REASON MSG -------------------------------- ------------------- ---- ---------- ----------------------------------- --- --- - - ------ ---------------------------------------------------------------- ... ... ... ... ... .. .. . . ... ... ... ... ... ... ... .. .. . . ... ... ... ... ... ... ... .. .. . . ... ... 53707720240643e9af99760a4bf40129 2022-10-19 17:11:38 COND dependent1 dependent1;;test-association;check UU UP masters:[m1,m2];\n $cluster_instance expanded to 'True' 88e9babc42b1498b9bf30eb7c53faef4 2022-10-19 17:11:38 ASS dependent1 m1 - - Changed association: on master 'm1' with instance 'True'. 476fa8c0391c4302b1e705e5aaa3f64b 2022-10-19 17:12:19 COND dependent1 dependent1;;test-association;check UP UU Error while evaluating expression: Unable to verify clust... dbde41ab21b94a1ca528fca6c9f4316c 2022-10-19 17:14:42 COND dependent1 dependent1;;test-association;check UU UP masters:[m1,m2];\n $cluster_instance expanded to 'True' 666b68bfe497418fa3b02395bd290eae 2022-10-19 17:14:42 ASS dependent1 m2 - - Changed association: on master 'm2' with instance 'True'. 0f3d1fc5575c4a9b8eda46b0cf6a0986 2022-10-19 17:14:55 ASS dependent1 m1 - - Changed association: on master 'm1' with instance 'True'. d6dca83b62204c3ea725d9b054005170 2022-10-19 17:15:04 ASS dependent1 m2 - - Changed association: on master 'm2' with instance 'True'. ... ... ... ... ... .. .. . . ... ... ... ... ... ... ... .. .. . . ... ... ... ... ... ... ... .. .. . . ... ...
3.3.4. Configurazione¶
CLI: si rimanda alla sezione: Nodi
WEB: non ancora disponibile.
3.4. Monitoraggio dei interfacce¶
3.4.1. Interfacce¶
Le interfacce possiedono tre attributi che possono essere modificati ai fini del monitoraggio.
Dato
Descrizione
nome
Stringa per identificare l'interfaccia nel monitoraggio
priorita'
Priorita' di default delle condition associate (se non specificato diversamente)
distinguisher
stringa per identificare univocamente l'interfaccia all'interno del nodo.
xform
Espressione che utilizzando il distinguisher, permette di calcolare automaticamente l'id dell'interfaccia nelle tabelle (SNMP o altro) interne del nodo
ifindex
Stringa che codifica l'istanza dell'interfaccia da usare per il monitoraggio. Viene calcolato automaticamente e non dovrebbe essere mai valorizzato esplicitamente.
backbone
Flag per indicare se l'interfaccia e' usata come dorsale (o uplink, backbone )
speed
Valore intero per indicare la (presunta) velocita' (rate bit/s) dell'interfaccia.
Alcuni di quest attributi possono essere utilizzati direttamente nei controlli (expressioni) di monitoraggio. Si veda: Built-in interface's variables.
3.4.1.1. Attributi Distinguisher, xform e valore ifIndex¶
Monitorando un'interfaccia di rete tramite protocolli come SNMP (ma anche altri), puo' succedere che l'interfaccia sia identificata tramite un indice numerico e non tramite una stringa mnemonica.
Questo indice numerico puo' essere dinamico e quindi cambiare in qualunque momento.
Attraverso l'utilizzo dei parametri distinguisher e xform, Sanet puo' verificare/ricalcolare, di volta in volta, il valore corretto dell'indice associato all'interfaccia.
Poiche' nel 99% dei casi il monitoraggio di rete avviene tramite protocollo SNMP, per comodita' di nomenclatura, l'indice di una interfaccia in Sanet e' chiamato ifIndex.
I datagroup che associati ad una interfaccia possono utilizzare il valore dell'ifIndex se nelle espressioni di datasource e condition viene indicato in qualche modo il simbolo $ifindex.
Note
in fase di configurazione e' possibile utilizzare per le xform degli alias al posto delle espressioni. Si veda la sezione: Xform predefinite.
3.4.1.1.1. Come viene calcolato l'IfIndex¶
Se l'attributo distinquisher e' valorizzato, l'indice dell'interfaccia e' considerato come il valore dell'ifindex. Valorizzare solo il distinquisher significa considerare l'indice dell'interfaccia come costante e immutabile.
Quando l'attributo xform e valorizzato con una espressione valida, Sanet calcola il valore dell'espressione e questo viene considerato con l'indice valido per l'interfaccia.
Se entrambi gli attributi distinguisher e xform sono valorizzati, Sanet calcola il valore dell'espressione xform e l'espressione puo' contenere il simbolo $distinguisher per effettuare il calcolo dell'indice dell'interfaccia.
Esempio 1: Solo il distinguisher e' parametrizzato:
name = eth0
distinguisher = 1 \_____ ifIndex = 1
xform = null /
Esempio 2: Distinguisher e xform parametrizzati, ma l'xform non utilizza il distinguisher:
name = eth0
distinguisher = "eth0.1" \_____ ifIndex = 56
xform = 56 /
Esempio 3: Distinguisher e xform parametrizzati:
name = eth0
distinguisher = "3" \_____ ifIndex = 6
xform = int($distinguisher) * 3 /
Esempio 4: Ipotizzando di avere una funzione findIfIndexByName() che calcola l'ifindex giusto in base al distinguisher dell'interfaccia.
name = eth0
distinguisher = "eth0.0" \_____ ifIndex = 124
xform = findIfIndexByName($distinguisher) /
3.4.1.1.1.1. Distinguisher & XForm Best Practice¶
E' bene tenere presente che:
il distinguisher e' una stringa identificativa che dovrebbe essere univoca
l'xform e' una espresssione che puo', ma non necessariamente, utilizzare il distinguisher per calcolare l'ifindex, stindex, ecc.
Da queste premesse e' fortemente consigliato:
Memorizzare sempre nel distinguisher una stringa pura (logicamente completa o parziale in base alle proprie esigenze) e opaca al sistema.
- Scrivere una xform che gestisca correttamente il distinguisher.
Se si utilizzano meccanismi basati su espressioni regolari assicurarsi che il distinguisher venga manipoloato correttamente (escaping, quoting) e non viceversa (ovvero modificare il distinguisher per far funzionare correttamente l'xform)
3.4.1.1.2. Quando viene calcolato l'IfIndex¶
Sanet effettua il calcolo dell'ifindex di una interfaccia SOLO se un datagroup utilizza nelle sue espressioni (di datasource o condition) il simbolo $ifindex.
Si dice che il simbolo $ifindex e' un valore LAZY, cioe' calcolato solo se effettivamente utilizzato.
Note
E' possibile scrivere datagroup che non sfruttano il meccanismo automatico.
Note
Se l'ifindex e' presente in piu' esperessioni di piu' datasource/condition dello stesso datagroup, questo viene comunque calcolato solo la prima volta che il valore deve essere usato. In pratica se il simbolo $ifindex e' utilizzato gia' nel primo datasource, il calcolo avviene immediatamente e il valore resta valido per tutta la valutazione del datagroup.
3.4.1.1.3. Parametri di monitoraggio ed altri simboli (impliciti) nelle espressioni¶
Oltre al simbolo $ifindex e $distinguisher esistono altri parametri di monitoraggio (ed corrispondenti simboli), che possono essere utilizzati nelle espressioni di datasource e condition.
Le interfacce ereditano molti dei parametri di configurazioni dal nodo di appartenenza, altri vengono calcolati automaticamente in base alla configurazione del monitoraggio: interfacce collegate, ecc.
Per un elenco completo di tutti i simboli utilizzabili nelle espressioni dei datagroup si rimanda alla sezione: SANET built-in expression symbols.
3.4.2. Configurazione delle interfacce¶
CLI: si rimanda alla sezione: Interfacce
WEB: non ancora disponibile.
3.5. Link tra nodi/interfacce¶
Un link serve per rappresentare un collegamento tra (due) interfacce di rete.
Note
Un'interfaccia di rete puo' comparire in piu' link contemporaneamente.
Un link e' definito dai seguenti attributi:
Dato
Descrizione
nome
Stringa univoca.Il nome di un link, se non specificato, viene assegnato automaticamente dal sistema in base alle interfacce coinvolte.
descrizione
Stringa di testo descrittiva.
tipo
(obbligatorio) Identifica il tipo di collegamento
Esistono tre tipi codificati di link:
FISICO : il link collega le interfacce a livello "fisico" (rame, radio, fibra).
RETE : il link esiste a livello logico (un adiacenza BGP, ess..) ma non fisico
VIRTUALE: il link esiste perche' fa comodo definire nel monitoraggio un collegamento che non sia dei due tipi precedenti.
Note
una interfaccia puo' essere coinvolta in UN SOLO link di tipo FISICO.
3.5.1. Interfaccia linked ed espressioni¶
Quando un'interfaccia (A) e' collegata ad una seconda interfaccia (B), l'interfaccia (B) e' detta interfaccia linked.
I datagroup che si occupano di monitorare interfacce possono accedere ad alcuni parametri/dati dell'interfaccia linked attraverso alcuni simboli calcolati automaticamente analogamente a quanto avviene per il simbolo $ifindex.
Il simbolo piu' importante e' $linked_ifindex, che rappresenta l'ifindex dell'interaccia linked.
Note
anche $linked_ifindex (ed altri simboli) sono calcolati dinamicamente e solo quando realmente utilizzati.
Per un elenco completo di tutti i simboli associati all'interfaccia linked si rimanda alla sezione: SANET built-in expression symbols.
3.5.2. Configurazione dei link¶
CLI: si rimanda alla sezione: Link
WEB: TODO
3.6. Monitoraggio degli storage¶
3.6.1. Parametri di monitoraggio¶
Come per le interfacce, anche gli storage sono caratterizzati da:
Dato
Descrizione
nome
Stringa per identificare lo storage nel monitoraggio
priorita'
Priorita' di default delle condition associate (se non specificato diversamente)
distinguisher
stringa per identificare univocamente lo storage all'interno del nodo.
xform
Espressione che utilizzando il distinguisher, permette di calcolare automaticamente l'id dello storage nelle tabelle (SNMP o altro) interne del nodo
stindex
Stringa che codifica l'istanza dello storage da usare per il monitoraggio. Viene calcolato automaticamente e non dovrebbe essere mai valorizzato esplicitamente.
Alcuni di quest attributi possono essere utilizzati direttamente nei controlli (expressioni) di monitoraggio. Si veda: Built-in storage's variables.
3.6.1.1. Attributi Distinguisher, xform e valore stIndex¶
Analogamente a quanto avviene con l'ifindex per le interfacce, ogni storage puo' essere identificato da un valore numerico chiamato stIndex.
Il valore dell'stIndex e' accessibile nelle espressioni tramite il simbolo $stindex.
Si rimanda alla sezione Attributi Distinguisher, xform e valore ifIndex per una descrizione su come parametrizzare/utilizzare xform e distinguisher per il calcolo dell'stIndex.
3.6.2. Configurazione degli storage¶
CLI: si rimanda alla sezione: Storage
WEB: non ancora disponibile.
3.7. Monitoraggio dei servizi¶
3.7.1. Parametri di monitoraggio¶
Come per le interfacce, anche i servizi sono caratterizzati da:
Dato
Descrizione
nome
Stringa per identificare lo storage nel monitoraggio
priorita'
Priorita' di default delle condition associate (se non specificato diversamente)
distinguisher
stringa per identificare univocamente il servizio nel nodo.
xform
Espressione che utilizzando il distinguisher, permette di calcolare automaticamente l'id del servozop nelle tabelle (SNMP o altro) interne del nodo
swrunindex
Stringa che codifica l'istanza del service da usare per il monitoraggio. Viene calcolato automaticamente e non dovrebbe essere mai valorizzato esplicitamente.
Alcuni di quest attributi possono essere utilizzati direttamente nei controlli (expressioni) di monitoraggio. Si veda: Built-in service's variables.
3.7.1.1. Attributi Distinguisher, xform e valore swRunIndex¶
Analogamente a quanto avviene con l'ifindex per le interfacce, ogni servizio puo' essere identificato da un valore numerico chiamato swRunIndex.
Il valore dell'swRunIndex e' accessibile nelle espressioni tramite il simbolo $swrunindex.
Si rimanda alla sezione Attributi Distinguisher, xform e valore ifIndex per una descrizione su come parametrizzare/utilizzare xform e distinguisher per il calcolo dell'swrunindex.
3.7.2. Configurazione dei servizi¶
CLI: si rimanda alla sezione: Service
WEB: non ancora disponibile.
3.8. Monitoraggio di device generici¶
3.8.1. Parametri di monitoraggio¶
Come per le interfacce, anche i device sono caratterizzati da:
Dato
Descrizione
nome
Stringa per identificare lo storage nel monitoraggio
priorita'
Priorita' di default delle condition associate (se non specificato diversamente)
distinguisher
stringa per identificare univocamente il device nel nodo.
xform
Espressione che utilizzando il distinguisher, permette di calcolare automaticamente l'id del device nelle tabelle (SNMP o altro) interne del nodo
devindex
Stringa che codifica l'istanza del device da usare per il monitoraggio. Viene calcolato automaticamente e non dovrebbe essere mai valorizzato esplicitamente.
Alcuni di quest attributi possono essere utilizzati direttamente nei controlli (expressioni) di monitoraggio. Si veda: Built-in device's variables.
3.8.1.1. Attributi Distinguisher, xform e valore devIndex¶
Analogamente a quanto avviene con l'ifindex per le interfacce, ogni device puo' essere identificato da un valore numerico chiamato devIndex.
Il valore dell'devIndex e' accessibile nelle espressioni tramite il simbolo $devindex.
Si rimanda alla sezione Attributi Distinguisher, xform e valore ifIndex per una descrizione su come parametrizzare/utilizzare xform e distinguisher per il calcolo dell'devindex.
3.8.2. Configurazione dei device¶
CLI: si rimanda alla sezione: Service
WEB: non ancora disponibile.
3.9. Gestione Messaggi/Allarmi¶
3.9.1. Wildcard¶
Ci sono tre metodi per espandere il testo con le informazoni disponibili:
Utilizzo di wildcard $.
Utilizzo di wildcard %.
Utilizzo di wildcard dinamici {{ }}.
3.9.1.1. Wildcard $¶
IMPORTANTE: Queste wildcard sono simili a quelle utilizzabili nei titoli di datagroup/condition/datasource.
Wildcard usabili negli allarmi associati ad un nodo:
Variabile
Descrizione
$node
nome del nodo
$snmpversion
snmp version del nodo
$community
snmp community del nodo
Tutti i parametri opzionali con $*parametro*
Es. $threshold
Wildcard usabili negli allarmi associati ad una interfaccia:
Variabile
Descrizione
$node
nome del nodo
$snmpversion
snmp version del nodo
$community
snmp community del nodo
$iface
nome dell'interfaccia
$instance
distinguisher dell'interfaccia
$distinguisher
distinguisher dell'interfaccia
$linked_iface
(interfaccia collegata con un link fisico)
$linked_node
(nodo dell'interfaccia collegata con un link fisico)
$ifindex
Ifindex calcolato da sanet aggiornato all'ultimo check
Tutti i parametri opzionali con $*parametro*
Es. $threshold
Wildcard usabili negli allarmi associati ad uno storage:
Variabile
Descrizione
Variabile
Descrizione
$node
nome del nodo
$snmpversion
snmp version del nodo
$community
snmp community del nodo
$storage
nome dello storage
$distinguisher
distinguisher dello storage
$stindex
stindex calcolato da sanet aggiornato all'ultimo check
Tutti i parametri opzionali con $*parametro*
Es. $threshold
Wildcard usabili negli allarmi associati ad uno service:
Variabile
Descrizione
$node
nome del nodo
$snmpversion
snmp version del nodo
$community
snmp community del nodo
$service
nome del servizio
$distinguisher
distinguisher del servizio
$swrunindex
swrunindex calcolato da sanet aggiornato all'ultimo check
Tutti i parametri opzionali con $*parametro*
Es. $threshold
Wildcard usabili negli allarmi associati ad uno device:
Variabile
Descrizione
$node
nome del nodo
$snmpversion
snmp version del nodo
$community
snmp community del nodo
$device
nome del device
$distinguisher
distinguisher del device
$devindex
devindex calcolato da sanet aggiornato all'ultimo check
Tutti i parametri opzionali con $*parametro*
Es. $threshold
3.9.1.2. Wildcard %¶
Entita'
Wildcard
Descrizione
%p
%
Tenant
%N
Nome del Tenant
Allarme
%t
Orario di generazione dell'allarme (in formato timestamp)
%s
Orario di generazione dell'allarme (in formato ISO)
%y
Data in formato YYYY-MM-DD HH:MM:SS
Nodo
%H
Nome del nodo sanet
%A
Indirizzi IPv4 del nodo risolti da Sanet
%D
Descrizione del nodo
Interfaccia
%I
Nome interfaccia
%ID
Descrizione interfaccia
%IDsnmp
Descrizione interfaccia tramite informazioni SNMP (on-demand)
%L
Nodo e interfaccia collegata nel formato nodo:interfaccia.
Condition
%T
Path della condition
%P
Priority della condition
%E
Espressione della condition
%m
Descrizione verbosa prodotta dal check della condition (verbstatus)
%M
Max tries della condition
%n
Numero di check effettuati al momento della generazione dell'allarme.
%U
URL della pagina WEB della condition associata all'allarme
Note
Queste wildcard esistono per retro-compatibilita' con sanet2. Alcuni dei valori espansi sono gli stessi ottenibili attraverso le wildcard descritte nel paragrafo precedente.
3.9.1.3. Wildcard dinamici {{ }}¶
Oltre alle wildcard descritte in precedenza, e' possibile inserire informazioni legate all'allarme utilizzando un linguaggio di template.
Il linguaggio di template supporta le seguenti feature:
Espansione di singoli valori
Formattazione dei valori espansi
Strutture condizionali if (non trattato in questo documento)
Cicli for (non trattato in questo documento)
3.9.1.3.1. Espandere valori semplici¶
Per stampare un singolo valore si deve usare la seguente sintassi:
{{ <simbolo> }}
Esempio:
{{ node.name }} {{ iface.description }} {{ ds.in.value }}
Important
quando il valore di un simbolo e' nullo (none, null, nil) vengono espansi con la stringa:
*NULL*
Il valore stringa vuota ('') e' un valore diverso da valore nullo.
Important
i simboli non previsti dal sistema vengono espansi con la stringa:
*UNDEFINED*
3.9.1.3.2. Strutture condizionali IF¶
E' possibile decidere di produrre o meno parti del testo usando strutture condizionali IF.
La sintassi generale e' la seguente:
{% if <wildcard> <operatore> <valore> %} ... {% else %} ... {% endif %}
Esempio:
{% if ds.numero_ap_associati.value > 0 %} Al momento risultano {{ds.numero_ap_associati.value}} AP associati. {% else %} Non ci sono AP associati. {% endif %}
Important
la sintassi effettivamente utilizzabile e' molto piu' flessibile. Si rimanda alla documentazione dei template Django https://docs.djangoproject.com/en/1.11/ref/templates/builtins/#if
3.9.1.3.3. Cicli "for"¶
Per iterare su valori multpli la sintassi e' la seguente:
{% for <element> in <array> %} ... {% endfor %}
Questa feature ha senso di esistere se si vuole "espandere" strutture dati complesse, ricevuta via rete in formato JSON.
Esempio:
{% for dati_iface in ds.stato_interfacce.value %} Nome: {% dati_iface.nome %} Stato: {{ dati_iface.stato }} {% endfor %}
Important
la sintassi effettivamente utilizzabile e' molto piu' flessibile. Si rimanda alla documentazione dei template Django https://docs.djangoproject.com/en/1.11/ref/templates/builtins/#for
3.9.1.3.4. Tutte le wildcard disponibili¶
Questo e' l'elenco dei simboli supportati:
Tenant
Simbolo
Descrizione
tenant.name
Nome del tenant
Nodi
Simbolo
Descrizione
node.name
Nome del nodo associato al controllo
node.description
Descrizione configurata per il nodo,
node.sysname
Nome SNMP del nodo corrente
node.syslocation
Localizzazione del nodo corrente
node.syscontact
Contatto primario relativo al nodo corrente
node.sysuptime
Tempo di attivita' del nodo in formato HH:MM:SS
node.effective_ip
L'indirizzo IP che Sanet pensa di dover usare in fase di check di un datagroup.
Simbolo
Descrizione
node.cluster_element.name
Nome del master del cluster per il nodo
Warning
La wildcard {{ node.effective_ip }} puo' dipendere da:
configurazione di Sanet
indirizzi IP risolti in fase di esecuzione (in presenza di indirizzi multipli non c'e' certezza di quale venga considerato effettivo al momento del check di un datagroup).
Interfacce
Simbolo
Descrizione
iface.name
Nome dell'interfaccia associata al controllo
iface.description
Descrizione configurata per l'interfaccia,
iface.description_snmp
Descrizione SNMP per l'interfaccia.
Simbolo
Descrizione
linked_node.name
Nome del nodo associato al controllo
linked_node.description
Descrizione configurata per il nodo,
linked_iface.name
Nome dell'interfaccia collegata associata al controllo
linked_iface.name
Nome dell'interfaccia associata al controllo
linked_iface.description
Descrizione configurata per l'interfaccia,
linked_iface.description_snmp
Descrizione SNMP per l'interfaccia.
Note
Le OID usate per calcolare {{iface.description_snmp}} sono:
1.3.6.1.2.1.2.2.1.2.<ifindex> 1.3.6.1.2.1.31.1.1.1.1.<ifindex> 1.3.6.1.2.1.31.1.1.1.18.<ifindex> 1.3.6.1.4.1.9.2.2.1.1.28.<ifindex>Danger
Le informazioni SNMP delle interfacce necessitano che il valore ifIndex dell'interfaccia sia stato calcolato dal sistema di monitoraggio. Questo avviene solo se almeno uno datagroup associato all'interfaccia e' riuscito a calcolare questo valore.
Warning
I dati raccolti tramite interrogazioni SNMP vengono espansi effettuando interrogazioni on-demand al momento della dell'espansione della wildcard. Il tempo di elaborazione complessivo dipende dallo stato del nodo interessato.
Warning
I dati raccolti tramite interrogazioni SNMP vengono gestiti tramite una cache temporanea di 60 secondi.
Storage
Simbolo
Descrizione
storage.name
Nome
storage.distinguisher
Distinguisher
storage.stindex
valore corrente
Service
Simbolo
Descrizione
service.name
Nome
service.distinguisher
Distinguisher
service.swrunindex
valore corrente
Device
Simbolo
Descrizione
device.name
Nome
device.distinguisher
Distinguisher
device.devindex
valore corrente
Datagroup
Simbolo
Descrizione
datagroup.minperiod
Minperiod del datagroup associato all'allarme
Datasource
Simbolo
Descrizione
ds.*name*.value
Valore del datasource (valore puntuale per GAURGE, rate per COUNTER)
Esempio: Se il datagroup definisce due datasource installed, total:
{{ ds.installed.value }} {{ ds.total.value }}
Parametri
Simbolo
Descrizione
params.*name*.value
Espande il valore del parametro con nome name
Esempio: Se il datagroup definisce un parametro con nome threshold:
{{ params.threshold.value }}
Condition
Simbolo
Descrizione
condition.path
Path della condition associata all'allarme
condition.priority
Priority della condition.
condition.alarm_url
URL della pagina WEB della condition associata all'allarme.
Simbolo
Descrizione
flap_dampened
flap_dampenedlastchange
flap_penalty
flap_damp_limit
flap_undamp_limit
flap_half_life
Simbolo
Descrizione
condition.flap_isflapping
Vero/Falso. Indica se la condition e' in flapping.
condition.flap_lastchange
Timestamp dell'ultima cambio della condizione di flapping.
condition.flap_cur_penalty_start
Orario in cui la penalty ha cominciato a salire dopo l'ultima volta che isflapping e' diventato False.
condition.flap_penalty
Valore di incremento della flap_cur_penalty
condition.flap_unpenalty
Valore di decremento della flap_cur_penalty se None allora viene usato flap_penalty.
condition.flap_penalty_limit
Valore di incremento della penalty associata alla condition (campo flap_cur_penalty)
condition.flap_penalty_high
Limite superiore di flap_cur_penalty oltre il quale la condition va in flapping
condition.flap_penalty_low
Limite inferiore sotto il quale la condition smettere di essere in flapping
condition.flap_half_life
Se <> 0 la penalty viene ridotta con decadimento esponenziale con tempo di dimezzamento pari a "half_life"
condition.flap_fa_as_dn
flag per decidere se gestire le transizioni di stato a UP*->FA e FA->UP* come
Trend
Simbolo
Descrizione
trend.*name*.date
Data in cui si prevede che il datasource a cui fa riferimento il trend raggiungera' la soglia.
trend.*name*.countdown_days
Contatore dei giorni che mancano dal giorno corrente alla date
trend.*name*.type_descr
Tipo di trend calcolato. Indica se il trend cresce in maniera uniforme o se presenta picchi. E' possibile scegliere la lingua di questo testo [1]
trend.*name*.direction_descr
Tipo di andamento del trend: puo' essere crescente o calante. E' possibile scegliere la lingua di questo testo [1]
trend.*name*.threshold_value
Valore di soglia usato dal calcolo del trend
trend.*name*.url
URL della pagina WEB del datagroup cui fa riferimento il trend
trend.*name*.text_info
Nel caso in cui non sia possibile calcolare il trend in questo campo ne verra' mostrato il motivo.
Note
Se il trend non viene calcolato (per mancanza di dati, errore di configurazione, bug), i campi assumono il valore "N/A".
Note
[1] E' possibile scegliere la lingua del testo aggiungendo alla wildcard l'informazione del locale
{{ <wildcard>|locale:"<codice_locale>" }}
Esempio per ottenere il testo "type_descr" del trend "mytrend" in italiano:
Questo trend e' un tipo: {{ trend.mytrend.type_descr|locale:"it" }}
Un esempio di utilizzo delle wildcard nel testo di una email: Esempio configurazione del trend
OID SNMP usate nelle expr
E' possibile inoltre espandere il valore delle variabili snmp utilizzate nell'esecuzione di un datagroup attraverso le seguenti wildcard:
Simbolo
Descrizione
exec_snmp.*oid*
Valore della variabile snmp avente oid specificata
exec_snmp.items
Lista di coppie (variabile, valore) in formato stringa che contiene tutte le variabili snmp utilizzate durante l'esecuzione del datagroup
E' possibile specificare la oid anche in maniera parziale (es: 1.3.6.1). In tal caso viene restituita una stringa che rappresenta una lista di coppie (oid, valore) le cui oid iniziano con quanto specificato.
L'espansione delle variabili SNMP e' possibile anche nei seguenti modi:
Srestituisce tutte le variabili SNMP utilizzate
{% for oid, value in exec_snmp.items %} {{oid}} = {{value}} {% endfor %}
Restituisce tutte le variabili SNMP utilizzate la cui oid inizia come specificato
{% for oid, value in exec_snmp.1.3.6.1 %} {{oid}} = {{value}} {% endfor %}
In caso di configurazione errata nell'espansione delle variabili SNMP viene visualizzato UNDEFINED. Ad esempio con la seguente configurazione:
{% for oid, value in exec_snmp.1.3.6.1 %} {{oid.3.4}} = {{value}} {% endfor %}
Nell'espansione di otterrebbe il seguente risultato (supponendo come variabili SNMP usate nell'esecuzione del datagroup: 1.3.6.1.4.1.2021.4.6.0@, 1.3.6.1.4.1.2021.4.5.0@, 1.3.6.1.4.1.2021.4.14.0@):
*UNDEFINED* = *UNDEFINED* *UNDEFINED* = *UNDEFINED* *UNDEFINED* = *UNDEFINED*
Variabili di contesto
Analogamente a quanto descritto per le variabili SNMP, e' possibile espandere anche le altre variabili di contesto utilizzate durante l'esecuzione di un datagroup utilizzando la wildcard:
Simbolo
Descrizione
exec_vars.*nome*
Valore della variabile avente nome specificato
Altri dati
E' possibile utilizzare molte altre wildcard. Si rimanda all'elenco in appendice: Elenco wildcards per allarmi
3.9.1.4. Formattare i valori¶
E' possibile formattare i valori numerici espansi utilizzando la seguente sintassi:
Sintassi
Descrizione
{{ <simbolo>|kilo }}
Formatta il numero usando i prefissi del sistema internazionale con base decimale (k, M, G, T)
{{ <simbolo>|kibi }}
Formatta il numero usando i prefissi con base binaria (ki, Mi, Gi)
Important
questa sinstassi e' applicabile solo se si utilizzano i wildcard dinamici {{ }}
Esempio:
nome datasource
valore datasource
Stringa nel messaggio
Espansione
in
1000
{{ ds.in.value }}
1000
in
1000
{{ ds.in.value|kilo }}
1k
in
1000
{{ ds.in.value|kibi }}
0.97ki
in
1024
{{ ds.in.value|kilo }}
0.97k
in
1024
{{ ds.in.value|kibi }}
1ki
3.9.1.5. Tabella comparativa¶
%
$
{{ }}
Allarme
%t
{{ alarm.ts }}
%s
{{ alarm.ts_iso }}
%y
{{ alarm.ts_ISO }}
Tenant
%N
{{ tenant.visible_name }}
Nodo
%H
$node
{{ node.name }}
{{ element.name }}
%A
{{ node.ipv4_addresses_spaced }}
{{ element.ipv4_addresses_spaced }}
%D
{{ node.description }}
{{ element.description }}
$snmpversion
{{ node.snmp_version }}
{{ element.snmp_version }}
$community
{{ node.snmp_community }}
{{ element.snmp_community }}
{{ node.cluster_element.name }}
{{ element.cluster_element.name }}
Interfaccia
%I
$iface
{{ iface.name }}
{{ element.name }}
%ID
{{ iface.description }}
{{ element.description }}
%IDsnmp
{{ iface.description_snmp }}
{{ element.description_snmp }}
$distinguisher
{{ iface.distinguisher }}
{{ element.distinguisher }}
$ifindex
{{ iface.ifindex }}
{{ element.ifindex }}
$linked_node
{{ linked_node.name }}
{{ linked_node.description }}
$linked_iface
{{ linked_iface.name }}
{{ linked_iface.description }}
{{ linked_iface.description_snmp }}
%L
$linked_node:$linked_iface
{{ linked_node.name }}:{{ linked_iface.name }}
Storage
$storage
{{ storage.name }}
{{ element.name }}
$distinguisher
{{ storage.distinguisher }}
{{ element.distinguisher }}
$stindex
{{ storage.stindex }}
{{ element.stindex }}
Service
$service
{{ service.name }}
{{ element.name }}
$distinguisher
{{ service.distinguisher }}
{{ element.distinguisher }}
$swrunindex
{{ service.swrunindex }}
{{ element.swrunindex }}
Device
$device
{{ device.name }}
{{ element.name }}
$distinguisher
{{ device.distinguisher }}
{{ element.distinguisher }}
$devindex
{{ device.devindex }}
{{ element.devindex }}
Datasource
{{ ds.<name>.value }}
Condition
%T
$path
{{ condition.path }}
%P
{{ condition.priority }}
%E
{{ condition.expr }}
%m
{{ condition.verbstatus }}
%M
{{ condition.max_tries }}
%n
{{ condition.tries }}
%U
{{ condition.alarm_url }}
{{ condition.flap_dampened }}
{{ condition.flap_dampenedlastchange }}
{{ condition.flap_penalty }}
{{ condition.flap_damp_limit }}
{{ condition.flap_undamp_limit }}
{{ condition.flap_half_life }}
{{ condition.flap_infos }}
Parametri
$<name>
{{ params.<name>.value }}
3.10. Calendari e range temporali¶
Un corretto monitoraggio deve essere in grado di:
gestire range temporali di interesse
distinguere tra giorni feriali/festivi/pre-festivi/ecc.
3.10.1. Range temporali¶
Un range temporale rappresente e' un periodo di tempo caratterizzato da un inizio ed una fine, e che puo' essere valido per uno o piu' giorni della settimana.
Un range temporale e' codificato attraverso una stringa che deve rispettare una precisa sintassi.
I formati ammessi per questa stringa sono:
all
Fa match con qualunque giorno.
none
Fa match con qualunque giorno. (Ereditato da sanet2)
time [ | time ...]
Dove time e' una stringa con il seguente formato:
[ hours [ , hours ... ] ] / [ days [ , days ... ] ]
Dove hours ha il formato:
hh [ : mm ] - hh [ : mm ]
I valori ammessi per hh vanno da 1 a 24. I valori ammessi per mm vanno da 1 a 59.
e days puo' avere i seguenti formati:
- H
Indica qualunque giorno festivo in base al calendario delle festivita'. Si veda Gestione del calendario.
- d [ - d ]
Giorno della settimana o range di giorni della settimana
I valori ammessi per d vanno da 1 a 7 (la numerazione dei giorni parte da Lunedi' (1 = Monday, 2 = Tuesday, 3 = Wednesday, 4 = Thursday, 5 = Friday, 6 = Saturday, 7 = Sunday)
- d p [ - d p ]
Giorno pre-festivo della settimana o range di giorni pre-festivi della settimana specificato dalla configurazione di Sanet. Si veda Gestione del calendario.
- [ date [ ; ... ] ]
Elenco di giorni dell'anno in formato YYYYMMGG o MMGG o GG.
Esempi:
8:00-18:00/1-7 Dal Lunedi' alla Domenica, tra le 8:00 e le 18:00. 00-24/H Tutti i giorni festivi, per tutto il giorno. 8:00-18:00,22:30-23:00/1-5|00:00-23:59/6-7,H Dal Lunedi' al Venerdi', tra le 8 e le 18 e tra le 22:30 e le 23. Il Sabato e la Domenica e tutti i festivi, tutto il giorno. 10-15/[01] Dalle 10 alle 15 del 1 giorno di ogni mese 10-15/[0205] Dalle 10 alle 15 del 5 febbraio di ogni anno 10-15/[20220101;20211225] Dalle 10 alle 15 del 25 Dicembre 2021 o il 1 Gennaio 2022.
3.10.2. Gestione del calendario¶
3.10.2.1. Introduzione¶
Alcuni giorni dell'anno sono speciali poiche' sono giorni di festivita' e l'operativita'/allarmistica deve essere gestita in maniera particolare.
Per gestire questi giorni speciali Sanet puo' essere configurato per tenere in considerazione uno o piu' calendari di giorni festivi.
Important
La gestione dei calendari si applica a tutti i tenant. Non e' possibile definire calendari validi solo per alcuni tenant, ma e' possibile definire calendari e utilizzarli per gestire l'operativita' di alcuni tenant e non di altri.
3.10.2.2. Calendario di default¶
Ogni calendario e' identificato da un nome logico. Il calendario di default e' chiamato "DEFAULT".
Quando non specificato, Sanet applica al calcolo dei giorni festivi il calendario "DEFAULT".
3.10.2.3. Configurazione¶
La configurazione del calendario delle festivita' e' gestita tramite file di configurazione di Sanet (settings.py).
Il formato di configurazione e' il seguente:
# Special days always treated HOLIDAYS HOLIDAYS = { 'DEFAULT': set([ <giorno1>, <giorno2>, <giorno3>, ... ]), <nome1>: set([ <giorno1>, <giorno2>, <giorno3>, ... ]), <nome2>: set([ <giorno1>, <giorno2>, <giorno3>, ... ]), ... }
I giorni festivi possono essere indicati in due modi:
MMDD Giorno festivo ricorrente il giorno DD/MM di tutti gli anni. YYYYMMDD Giorno festivo in data DD/MM/YYYY
Questo e' un esempio di file di configurazione che specifica il calendario di DEFAULT e un calendario applicabile alla citta' di Roma:
Esempio:
# Special days always treated HOLIDAYS HOLIDAYS = { 'DEFAULT': set([ # All years, only 4 digits MMDD '0101', '0106', '0425', '0501', '0602', '0815', '1101', '1208', '1225', '1226', # Specific year, 4 digits YYYYMMDD # Giorni di pasquetta dal 2015 al 2034 '20150406', '20160328', '20170417', '20180402', '20190422', '20200413', '20210405', '20220418', '20230410', '20240401', '20250421', '20260406', '20270329', '20280417', '20290402', '20300422', '20310414', '20320329', '20330418', '20340410', ]), 'rome': set([ '2906', # Festa patronale ]), }
3.10.2.4. Giorni della settimana speciali (special holidays)¶
Warning
Questa gestione e' obsoleta. Non utilizzare.
E' possibile indicare al sistema quale giorno della settimana considerare come "festivo" e dire considerare i giorni festivi in calendario come se ricadessero nel giorno specificato.
HOLIDAYS_AS_WDAY = 7
IMPORTANTE: se HOLIDAYS_AS_WDAY e' valorizzato a None la gestione delle special holidays viene ignorata:
HOLIDAYS_AS_WDAY = None
3.11. Eventi "Push" per monitoraggio passivo¶
3.11.1. Introduzione¶
Gli eventi push (insieme alle TRAP SNMP Trap SNMP) sono uno dei meccanismi per scatenare manualmente l'esecuzione di datagroup passivi (vedi Datagroup Passivi).
Il flusso di monitoraggio e' diviso in tre fasi:
Fase di RECEIVE: Raccolta dati dalla rete ( esecuzione di datagroup da parte di agenti)
Fase di PROCESS: Ricezione ed elaborazione dei dati dal server centrale di sanet
Fase di NOTIFY : Notifica di allarmi
Attraverso gli eventi/allarmi Push e' possibile inserirsi in questo flusso utilizzando dati prodotti da applicazioni esterne.
E' possibile effettuare due tipi di operazioni push, che si differenzioano in base al punto di ingresso nel sistema:
Push di eventi
Push di allarmi
Ricapitolando, in questo schema viene riassunto il flusso di:
monitoraggio di datagroup normali
monitoraggio di Trap SNMP attraverso datagroup passsivi
push di eventi ed elaborazione don datagroup passivi
push di allarmi in entables
3.11.2. Eventi push¶
Un evento push e' una struttura dati a dizionario ( chiave/valore ) a cui e' associato un identificativo logico
Esempio: L'evento con ID "event-type1"
{ "data" : "1/1/2015", "variabile1": 666, "lista" : [ 1 , 2, 3, ], "sottocampo": { "chiave1": 1, "chiave2": "pippo", } }
3.11.2.1. Fasi di elaborazione di un evento push¶
Quando viene fatto push di un evento, bisogna specificare:
nome di un nodo o un indirizzo IP
una stringa identificativa per di passive match
Sanet compie le seguenti operazioni:
L'evento viene storicizzato nel log di come evento CUSTOM.
Sanet cerca di capire se l'evento e' associabile ad un elemento di monitoraggio.
Sanet cerca di capire con quale datagroup elaborare l'evento tramite passive match.
Esecuzione del datagroup
3.11.2.2. Selezione del nodo¶
In fase di push e' possibile associare l'evento ad un nodo.
Per farlo si possono usare due memtodi
indicare un indirizzo IP sorgente.
Sanet cerca di associare un nodo monitorato eseguendo i seguenti step:
Calcola il DN (Domain Name) dell'host su cui e' in esecuzione Sanet.
Calcola il FQDN (Full Qualified Domain Name) dall'indirizzo IP
Rimuovi il DN dal FQDN trovato e ottiene il nome di un host.
Cerca in sanet il nodo con il nome corrispondente.
indicare il nome di un nodo di monitoraggio.
Viene selezionato il nodo con esattamente il nome inidicato.
3.11.2.3. Selezione del datagroup tramite passive match¶
Una volta che Sanet ha identicato il nodo da associare all'evento push, cerca di trovare quali datagroup di quel nodo (o dei suoi sotto elementi) devono processare i dati dell'evento.
Per trovare l'associazione tra evento e datagroup viene confrontato l'ID dell'evento push con il passive match (vedi Passive match).
3.11.2.4. Dati dell'evento elaborati dal datagroup passivo¶
Quando un datagroup elabora un evento, i campi dell'evento possono essere usati nelle expr del datagroup (dei datasource o condition) per effettuare confronti e operazioni.
Tutta la struttura dati dell'evento e' accessibile tramite il simbolo
$_event
Esempi di expr che usano i dati dell'evento:
expr $_event["variabile1"] == 666 expr $_event["sottocampo"]["chiave1"] == 1
Per comodita' (e semplicita' di scrittura), tutte le tuple chiave/valore di primo livello sono accessibili direttamente usando variabili del tipo:
$<chiave dell'evento>
Esempio:
EVENTO SIMBOLI ACCESSIBILI NELLE EXPR $_event { "data" : "1/1/2015", -> $data "variabile1": 666, -> $variabile1 "lista" : [ 1 , 2, 3, ], -> $lista "sottocampo": { -> $sottocampo "chiave1": 1, "chiave2": "pippo", } }
3.11.2.5. Comando push_event¶
Per effetuare il push di un evento bisogna usare il comando:
sanet-manage push_event [optioni] --element <node or IP> --passive-match <string> <JSON STRING>
Esempio:
sanet-mange push_event -L 10 --element localhost --passive-match event-type1 '{ "val": 10 }'
3.11.2.5.1. Dati dell'evento¶
3.11.2.5.1.1. A riga di comando¶
L'allarme deve essere un dizionario codificato in formato JSON .
Esempio: Dato il seguente allarme:
{ "campo1": "hello", "campo2": "world", "campo3": 1234 }
Il comando e':
sanet-manage push_event --element localhost --passive-match event1 '{ "campo1" : "hello", "campo2" : "world", "campo3" : 1234 }'
3.11.2.5.1.2. Da standard input¶
sanet-manage push_event --element localhost --passive-match event1 --stdin <<EOF { "campo1" : "hello", "campo2" : "world", "campo3" : 1234 } EOFecho '{ "campo1" : "hello", "campo2" : "world", "campo3" : 1234 }' | sanet-manage push_event --element localhost --passive-match event1 --stdin
3.11.2.5.1.3. Da environment¶
Per specificare un attributo dell'allarme da environemnt bisogna definire una variabile d'ambiente con il seguente nome:
PUSH_EVENT_{chiave}=<stringa>
Warning
I valori delle chiavi sono in stringhe e Sanet li processera' come stringhe.
Esempio:
export PUSH_EVENT_campo1=ciao export PUSH_EVENT_campo2=3.14 export PUSH_EVENT_campo3=666 sanet-manage push_event --env --element localhost
L'evento "logicamente" processaro in input sara' analogo a questo:
{ "campo1" : "ciao" "campo2" : "3.14" "campo3" : "666" }
3.11.2.5.2. Esempi¶
Configurazione nodo e datagroup passivo:
datagroup-template dgpassive passive-match passivo minperiod 0 title "Datagroup per eventi passivi" condition check expr "$var == 1" max-tries 1 msg-downbody "Evento passivo down" msg-downsubj "[DOWN] Evento passivo" msg-upbody "Evento passivo up" msg-upsubj "[UP] Evento passivo" title "Controllo passivo" exit exit node localhost datagroup dgpassive exit exit
Configurazione entables:
entables -t notify -F notify entables -t notify -A DEFAULT -j SMTP --smtp_rcpt_to '${mail_to}' --smtp_message '${mail_body} - ${rawalarm}' --smtp_subject '${mail_subject}'
Push dell'evento:
sanet-manage push_event -L 10 --sourceip 127.0.0.1 --passive passivo '{ "var": 0 }'
3.11.2.6. Mostrare i dati pushed nei messaggi degli allarmi¶
Quando viene generato un allarme da un evento pushed, e' possibile inserire i dati pushed all'interno del corpo dei messsaggi UP e DOWN usando le wildcard dinamici (Vedi anche Wildcard dinamici {{ }}).
La sintassi e' la seguente:
{{ pushed_data.<key>[.<key> ...] }}
Esempio: Se questi sono i dati dell'evento pushed:
{ "campo1" : "ciao", "campo2" : [ 1, 2, 3 ], "campo3" : { "key1": 666, "key2": 777, } }
Questi sono alcuni esempi delle wildcard che e' possibile usare:
{{ pushed_data.campo1 }} --> ciao {{ pushed_data.campo2.1 }} --> 2 {{ pushed_data.campo3.key2 }} --> 777
Esempio:
datagroup-template dgpassive passive-match passivo minperiod 0 title "Datagroup per eventi passivi" condition check expr "$var == 1" max-tries 1 msg-downsubj "[DOWN] Evento passivo" msg-downbody "Evento passivo down. var={{ pushed_data.var }}" msg-upsubj "[UP] Evento passivo" msg-upbody "Evento passivo up. var={{ pushed_data.var }}" title "Controllo passivo" exit exit node localhost datagroup dgpassive exit exit
3.12. Trap SNMP¶
#.. contents:: Contenuti
3.12.1. Introduzione¶
Sanet puo' ricevere TRAP SNMP, storicizzarle all'interno del proprio Log ed eventualmente cercare di processarle.
La ricezione delle trap e' delegata ad un processo di appoggio NON ATTIVO DI DEFAULT.
3.12.2. Flusso di ricezione¶
Il flusso di elaborazione e' il seguente:
La trap viene ricevuta dal processo delegato alla ricezione delle TRAP
La trap viene storicizzata
Sanet cerca di associare la trap ad un nodo di sanet e processare la trap con un datagroup passivo.
Eventuali allarmi generati dal datagroup (dalle sue condition) vengono inviati ad entables
Schme flusso logico dati di un Trap SNMP:
SANET SERVER +------------------------------------------------+ | | | (1) +-------+ (3) (4) | switch ------*trap*--------------> | trapd |------> datagroup------*alarm*-------> ENTABLES ------> MAIL | +-------+ | | | | | | | (2) | | | | `----------------`---> LOG | | | +------------------------------------------------+
3.12.3. Limiti della gestione delle Trap SNMP¶
3.12.3.1. Elementi monitorabili¶
Al momento il sistema di gestione della trap non consente di sfruttare il meccanismo di calcolo automatico dell'ifindex/stindex/swrunindex/devindex. (Vedere ad esempio Interfacce e ifindex)
Questo significa che e' possibile associare le trap ricevute solo a nodi (e i loro datagroup) in maniera automatica.
Note
Tentare di associare trap a nodi o interfacce e' possibile con sistemi non facilmente automatizzabili.
Per questo motivo tutti i datagroup passivi che si vogliono implementare devono essere implementati per essere applicabili solo a nodi (o node template).
3.12.3.2. Limite a cosa e' possibile gestire nelle espressioni¶
Le espressioni di datasource/condition di datagroup passivi sono limitate.
Non e' possibile chiedere valori di OID diverse da quelle contenute nella varbind list della TRAP.
Non e' possibile effettuare SNMP Walk o utilizzare altre funzioni che si basano su operazioni di walk snmp.
L'accesso a simboli speciali (ifindex, linked_ifindex, cluster instance, ecc) produrra eccezioni con conseguente stato uncheckable.
3.12.3.3. Trap SNMP non gestite¶
Sanet potrebbe non essere in grado di processare le trap in input per due motivi:
Non riesce ad associare l'indirizzo IP sorgente della trap a nessun nodo. (Vedi Associazione con i nodi di sanet)
Non riesce a processare la trap attraverso nessun datagroup passivo definito per quel nodo. ( Vedi Configurare un datagroup per processare le trap ).
Quando una di queste due condizioni si verifica Sanet invia una mail per segnalare la mancata gestione delle trap.
Si veda il paragrafo Configurazione Notifica delle TRAP non gestite per i dettagli.
3.12.3.4. Associazione con i nodi di sanet¶
Le TRAP SNMP contengono solo l'indirizzo IP sorgente del noto che ha generato la trap.
Sanet cerca di individuare a quale nodo associare la trap in fase di memorizzazione del log.
Se Sanet non riesce ad individuare il nodo, la trap viene solo semplicemente memorizzata con indicazione solo dell'indirizzo IP sorgente.
3.12.3.4.1. Algoritmo per trovare il nodo di sanet¶
Calcola il FQDN (Full Qualified Domain Name) dall'indirizzo IP sorgente della trap
Calcola il DN (Domain Name) dell'host su cui e' in esecuzione Sanet
Rimuovi il DN dal FQDN della trap.
Cerca in sanet il nome del nodo corrispondente.
3.12.4. Configurazione¶
3.12.4.1. Abilitare la ricezione delle trap¶
Indicare nel file di configurazione l'indirizzo su cui mettere in ascolto Sanet per le TRAP.
Esempio:
SNMPTRAP_LISTEN = ('0.0.0.0', 162)
3.12.4.2. Configurare un datagroup per processare le trap¶
Per fare in modo che un datagroup venga utilizzato da Sanet per processare delle TRAP bisogna:
Configurare il datagroup come passivo impostando il min-period a zero.
Configurare il campo passive-match del datagroup inpostando la OID della trap da processare.
Esempio:
datagroup-template dgtrap ... passive-match 1.3.6.1.6.3.1.1.5.3 minperiod 0 ... exit
Important
Specificando il passive-match come espressione regolare e' possibile fare match di OID parziali o sub-OID.
Esempio:
datagroup-template dgtrap
...
passive-match regex:^1.3.6.1.6.*
minperiod 0
...
exit
3.12.4.3. Configurazione Notifica delle TRAP non gestite¶
- Nel file di configurazione di Sanet (settings.py) si possono specificare i parametri (from, to, body) per l'invio di mail in due casi:
Trap ricevute ma non associate a nessun nodo. Sono definite trap sconosciute o unknown.
Trap ricevute, associate ad un nodo con successo, ma non processate da alcun datagroup. Sono definite trap non gestite o unmanaged.
Nel soggetto/corpo della mail e' possibile utilizzare delle wildcard per fornire maggiori dettagli sulla trap segnalata.
SNMPTRAP_MAIL_CONF = { 'from': 'sanet.trapd@localhost', # # Settings for TRAPs from unknown hosts # 'unknown': { # You can use the following wildcard inside the subject/body text: # # {{receive_time}} = timestamp # {{source_ip}} = Source IP # {{trap_oid}} = TRAP OID # {{trap_msg}} = Verbose TRAP description # 'to' : 'root@localhost', 'subject' : '[sanet trapd] Trap from unknown host {{source_ip}}', 'body' : 'Received SNMP Trap at {{receive_time}}.\n\n{{trap_msg}}s', }, # # Settings for unhandled TRAPs linked to sanet nodes # 'unmanaged': { # Default notification address. If a node specifies the 'notify-address' # field, the field will be used instead of this default. 'to' : 'root@localhost', # You can use the following wildcard inside the subject/body text: # # {{receive_time}} = timestamp # {{source_ip}} = Source IP # {{trap_oid}} = TRAP OID # {{trap_msg}} = Verbose TRAP description # {{sanet_node}} = Sanet node name # 'subject' : '[sanet trapd] Unmanaged TRAP from {{source_ip}} for node {{sanet_node}}', 'body' : 'Received SNMP Trap at {{receive_time}}.\n\n{{trap_msg}}', } }
3.12.4.4. Trap non gestite e notify-address¶
Se la configurazione di un nodo specifica l'attributo notify-address, le trap unmanaged vengono inviate all'indirizzo indicato mentre l'indirizzo specificato in configurazione nella sezione 'unmanaged' viene ignorato.
3.12.5. Gestione trap non ricevute e stato dei datagroup¶
E' possibile che le Trap non vengano ricevute. Questo potrebbe lasciare un datagroup (e le sue condition) in uno stato inconsistente.
E' possibile specificare di re-impostare/ricalcolare un datagroup passivo associato ad una TRAP attraverso il meccanismo di Ripristino passivo automatico (passive period).
Un altra alternativa consiste nel forzare lo stato UP o DOWN di un intero datagroup o di alcune sue condition con il comando:
sanet-manage force_dg_status [options] <datagroup path>
Le opzioni disponibili sono:
--status STATUS Codice dello stato: UP o DN --tenant TENANT Nome del tenant. Default: il tenant primario --reason REASON Verbstatus che comparira' nei log --conditions CONDITIONS Elenco coi nomi delle condition da aggiornare. Default: tutte. -l LOGLEVEL Livello di verbosita dell'output
Esempio:
sanet-manage force_dg_status 'localhost;;dgtrap' --reason "test" --status UP
Questo potrebbe lasciare un datagroup passivo (e i suoi datasource e le sue condition) in uno stato inconsistente.
3.12.6. Agenti remoti come proxy per trap SNMP¶
E' possibile configurare gli agenti remoti per ricevere le trap e "inoltrarle" al server centrale.
Questo permette di ricevere trap anche da apparati che non sono in grado di comunicare direttamente con il server centrale.
| | SANET SERVER | switch -----*TRAP*---------------------------------|---------. | UDP | | | | | *:162 | | v | | +-------+ +----------+ | | | TRAPD |----> | ENTABLES | | | +-------+ +----------+ | | ^ | | . QUEUE | UDP +------------+ | . | switch -----*TRAP*---------->|remote agent|........|.......... | *:162 +------------+ TCP |
Per ottenere questo risultato e' necessario:
Abilitare le trap SNMP sul server centrale (anche se potrebbe non essere in grado di riceverle)
Abilitare le trap SNMP sugli agenti remoti. Vedi sezione: remote-agent-trap-snmp.
3.12.7. Esempio¶
Esempio che mostra come:
Scrivere un datagroup passivo che gestisce 2 TRAP
Le TRAP gestite sono quelle che hanno OID l che inizia per "1.2.3.4.5"
Due condition distinte si attivano se la OID 1.3.6.1.2.1.1.6.6.6.0 ricenvuta nella TRAP ha valore "SI".
Dopo 30 secondi le condition tornano comunque in stato UP (poiche' l'espressione del parametro passive-force-status e' sempre vera)
Per ottenere questo risultato e' necessario:
Abilitare le trap SNMP sul server centrale (anche se potrebbe non essere in grado di riceverle)
Abilitare le trap SNMP sugli agenti remoti. Vedi sezione: remote-agent-trap-snmp.
Configurazione:
datagroup test-trap
title "Trap Tester"
passive-match regex:1\\.2\\.3\\.4\\.5\\..$
minperiod 0
passive-period 30
condition check7
title "Simple condition 7"
expr " 1.3.6.1.6.3.1.1.4.1.0@ == '1.2.3.4.5.7' and 1.3.6.1.2.1.1.6.6.6.0@ == 'SI'"
max-tries 1
msg-upsubj "TRAP 7 UP"
msg-upbody "TRAP 7 UP TEXT"
msg-downsubj "TRAP 7 DOWN SUBJECT"
msg-downsubj "TRAP 7 DOWN BODY"
passive-force-status 1
exit
condition check8
title "Simple condition 8"
expr " 1.3.6.1.6.3.1.1.4.1.0@ == '1.2.3.4.5.8' and 1.3.6.1.2.1.1.6.6.6.0@ == 'SI'"
max-tries 1
msg-upsubj "TRAP 8 UP"
msg-upbody "TRAP 8 UP TEXT"
msg-downsubj "TRAP 8 DOWN SUBJECT"
msg-downsubj "TRAP 8 DOWN BODY"
passive-force-statu 1
exit
exit
no node localhost localhost
node localhost
datagroup test-trap
exit
exit
Geneare le trap 1.2.3.4.5.7 e 1.2.3.4.5.8 a mano, specificando un valore per la OID 1.3.6.1.2.1.1.6.6.6.0:
Invio TRAP 1.2.3.4.5.7:
snmptrap -v 2c -c public localhost '' 1.2.3.4.5.7 1.3.6.1.2.1.1.6.6.6.0 s "SI"Invio trap 1.2.3.4.5.8:
snmptrap -v 2c -c public localhost '' 1.2.3.4.5.8 1.3.6.1.2.1.1.6.6.6.0 s "SI"
3.13. Push di allarmi in entables¶
3.13.1. Introduzione¶
Il push di allarmi in entables e' una particolare operazione che consente di inviare dati direttamente ad entables.
3.13.2. Formato allarme per entables¶
Un allarme e' una struttura dizionario codificata in formato JSON.
Questi dati possono essere utilizzati in entables per fare match, espandere stringhe e template nei target, ecc.
Un allarme viene processato da entables cosi' come viene inserito nel sistema.
Warning
Sanet non salva nel log degli eventi questa operazione.
Warning
L'allarme viene processato da entables cosi' come viene fornito. La struttura dati a dizionario deve essere "coerente" con il funzionamento di entables.
3.13.2.1. Campi obbligatori/automatici¶
Ogni allarme deve avere due attributi obbligatori.
Attributo
Descrizione
Default
tenantid
UUID del tenant a cui associare l'allarme. (vedi opzione --tenant)
UUID del tentant primario
uuid
UUID univoco dell'alarme
Calcolato nuovo
Note
in assenza di questi due attributi, Sanet calcola automaticamente un valore da asseganre ad entrambi.
3.13.2.2. Campi per invio email¶
Per fare in modo che un allarme push sia compatibile con i meccanismi di invio email di entables (target SMTP) e' necessario che contena una chiave "mail". Il valore di questa chiave deve essere un dizionario con tre chiavi "to", "subject" e "body".
Esempio:
{ "var": 1, "mail": { "to" : "root", "subject": "evento custom", "body" : "corpo" }, }
3.13.3. Comando push_alarm¶
Per fare push di un allarme in entables bisogna usare il comando:
sanet-manage push_alarm [opzioni] [ dati allarme in formato JSON ]
Esempio:
sanet-manage push_alarm '{ "dato" : 10 }'
3.13.3.1. Dati dell'allarme a riga di comando¶
L'allarme deve essere un dizionario di attributi chiave/valore codificato in formato JSON valido.
Esempio: Dato il seguente allarme:
{ "campo1": "hello", "campo2": "world", "campo3": 1234 }
Il comando e':
sanet-manage push_alarm '{ "campo1" : "hello", "campo2" : "world", "campo3" : 1234 }'
3.13.3.2. Dati dell'allarme da standard input¶
sanet-manage push_alarm --stdin { "campo1" : "hello", "campo2" : "world", "campo3" : 1234 } Ctrl+d
3.13.3.3. Dati dell'allarme da environemnt¶
Per specificare un attributo dell'allarme da environemnt bisogna definire una variabile d'ambiente con il seguente nome:
EVENT_PUSH_{nome}={valore}export EVENT_PUSH_campo1=ciao sanet-manage push_alarm --env
L'allarme inviato ad entables sara':
{ "campo1" : "ciao" }
3.13.3.4. Distinguere gli allarmi pushed in entables¶
E' possibile distinguere gli allarmi generati da Sanet da quelli pushed manualmente, attraverso i match disponibili di Entables.
Per dettagli si rimanda alla documentazione di Entables: match Attributes.
Esempio:
entables -t notify -F DEFAULT entables -t notify -A DEFAULT -m attr --attr_alarmtype "normal" -j SYSLOG --syslog_msg "normale" entables -t notify -A DEFAULT -m attr --attr_alarmtype "pushed" -j SYSLOG --syslog_msg "pushed"
3.13.4. Esempio 1: push di allarme con invio email ad un indirizzo di posta fisso¶
Configurazione di entables:
./bin/entables -t notify -A DEFAULT -j SMTP --smtp_rcpt_to 'root' --smtp_message '${rawalarm}' --smtp_subject 'Evento custom'
Push dell'allarme:
sanet-manage push_alarm '{ "val":10 }'
Note
l'UUID e il TENANT ID dell'evento verrano aggiunti in automatico dal comando.
3.13.5. Esempio 2: push di un allarme con invio email composta da dati dell'allarme¶
Invio semplice di allarmi via SMTP:
entables -t notify -F DEFAULT entables -t notify -A DEFAULT -j SMTP \ --smtp_rcpt_to '${mail_to}' \ --smtp_message '${mail_body}' \ --smtp_xheaders '${mail_xheaders}' \ --smtp_subject '${mail_subject}'
Push di un evento custom. Il campo "mail" conviene i parametri che entables riconosce ed espande con i tag buitin:
sanet-manage push_alarm -L 10 '{ "mail": { "to":"root", "subject": "evento custom", "body": "corpo" } }'
Oppure:
sanet-manage push_alarm -L 10 --stdin <<EOF '{ "mail": { "to":"root", "subject": "evento custom", "body": "corpo" } }' EOF
3.14. Diagnostica interna¶
3.14.1. Notifica di anomalie di configurazione¶
Sanet puo' essere configurato per verificare e notificare anomalie nei seguenti casi:
Errori nei parametri di configurazione globali
Errori o incogruenze nelle configurazioni degli oggetti monitorati
3.14.1.1. Invio delle anomalie¶
Per verificare le anomalie e' necessario eseguire il comando:
sanet-manage find_and_notify_anomalies [options]
Questo comando inviera' tramite email un elenco delle anomalie trovate.
3.14.1.2. Disabilitare la notifica tramite mail¶
E' possibile lanciare il comando senza notifiche con l'opzione:
sanet-manage find_and_notify_anomalies --no-mail
3.14.1.3. Output in formato ridotto¶
E' possibile ottenere l'elenco delle anomalie in un formato compatto con l'opzione --compact:
sanet-manage find_and_notify_anomalies --compact
Il formato e':
<tenant name> <code> <path>
Se l'anomalia e' globale (non associata a nessun tenant) il campo tenant name e' valorizzato con (-).
Insieme all'opzione --no-mail e' utile per avere l'elenco delle anomalie e processarlo tramite script di shell:
sanet-manage find_and_notify_anomalies --compact --no-mail 2> /dev/null
3.14.1.4. Verifica periodica (crontab)¶
Sanet non verifica automaticamente le anomalie. E' necessario configurare il proprio sistema per esguire in maniera schedulata il comando necessario:
Esempio: Inviare le notifiche una volta alla settimana con crontab:
# Minute Hour Day of Month Month Day of Week Command # (0-59) (0-23) (1-31) (1-12 or Jan-Dec) (0-6 or Sun-Sat) 0 0 * * 0 sanet-manage find_and_notify_anomalies > /var/log/sanet3/lastoutput.find_and_notify_anomalies.daily 2>&1
3.14.1.5. Parametri per la notifica via mail¶
I parametri per la notifica via mail sono specificati attraverso il parametro DIAGNOSTIC_SETTINGS nel file:
{{SANET_INTALL_DIR}}/conf/default_settings.py
Questo e' un esempio di configurazione:
DIAGNOSTIC_SETTINGS = { # Abilita o disabilita la verifica delle anomalie 'enabled': True, 'mail_settings': { # Set to '' to disable email notification "to" : 'root@localhost', "from" : 'sanet3diagnostic', "subject" : '[Sanet3 diagnostic] Found %(diagnostic_alerts)s alters', # Message body static part (wdog message will be appended to this). "body" : 'Please verify the following alerts:\n\n%(diagnostic_text)s', }, 'ignored_anomalies': [ ] }
3.14.1.6. Ignorare alcuni controlli¶
Nella mail di notifica tutti i controlli sono contrassegnati da una stringa identificativa racchiusa tra '[...]'.
Esempio: testo parziale di una mail di notifica:
... [sanet.server.monitored.cpu] Sanet Server (debian9.internal.labs.it) monitored, but no controls on CPU. [system.ram.used] Sanet Server (debian9.internal.labs.it) monitored, but no controls on RAM. [duplicated.primary] Tenant 'site'. Element 'xxx' (cfb7865f7ce54880867954f9f96969a9) has multiple primary conditions (2) ...
E' possibile decidere di ignorare alcune anomalie specificando in configurazione
Esempio:
DIAGNOSTIC_SETTINGS['ignored_anomalies'] = [ 'sanet.server.monitored.cpu', 'duplicated.primar', ]
3.14.1.6.1. Whitelist di elementi da ignorare¶
E' possibile popolare una "whitelist" di elementi da ignorare durante alcuni controlli.
La "whitelist" e' composta da un elenco di tuple:
<codice anomalia> <path elemento>
Il codice anomalia puo' essere valorizzato con il valore speciale '*' per indicare qualunque anomalia.
- Il path elemento puo' essere:
Il nome di un nodo. Esempio: "localhost"
Il nome di un nodo + sotto-elemento separati da due punti (:). Esempio: "localhost:eth0".
Il path di un datasource o di una condition
Esempi:
localhost localhost:eth0 localhost:eth0;iface-base;iface-status;fdbdiscard
3.14.1.6.1.1. Elencare gli elementi¶
Lanciare il comando:
sanet-manage diagnostic_whitelist_ctl list
3.14.1.6.1.2. Importare una whitelist da standard input¶
Lanciare il comando:
sanet-manage diagnostic_whitelist_ctl import
Il formato in input e' lo stesso del comando list.
Warning
Il comando azzera completamente la whitelist esistente prima di importare la nuova da standard input.
3.14.1.6.1.3. Aggiungere/togliere elementi¶
sanet-manage diagnostic_whitelist_ctl add <code> <path> sanet-manage diagnostic_whitelist_ctl del <code> <path>
Esempi:
sanet-manage diagnostic_whitelist_ctl add datasource.state.sv localhost # Ignora tutti gli errori di tipo 'datasource.state.sv' su localhost sanet-manage diagnostic_whitelist_ctl del datasource.state.sv localhost sanet-manage diagnostic_whitelist_ctl add '*' localhost # Ignora tutti gli errori su localhost
3.14.2. Refresh di configurazioni incomplete¶
Alcuni comandi della CLI possono causare una configurazione "parziale" del sistema e obbligare ad un "refresh" degli elementi di monitoraggio.
Queste situazioni "anomale" vengono segnalate dal sistema di diagnostica e possono essere risolte manualmente oppure attraverso il comando
sanet-manage refresh_unconfigured_nodes
Questo comando esegue il "refresh" di tutti i nodi che si trovano in una situazione "inconsistente".
Prima di lanciare il comando e' consigliabile consultare l'elenco degli elementi che verrebbero "aggiornati" attraverso il comando:
$ sanet-manage refresh_unconfigured_nodes --generate-conf-commands
Esempio di output:
configuration tenant site set terminal exitwords EXITTENANT refresh node localhost refresh node router1 ... ... EXITTENANT
Il comando chiede conferma manuale, ma si puo' lanciare anche senza conferma:
sanet-manage refresh_unconfigured_nodes