Concetti di base del monitoraggio¶
Gerarchia del monitoraggio¶
Sanet organizza il monitoraggio in maniera gerarchica.
Il seguente schema mostra la relazione gerarchica delle diverse entita’:
- Tenant (Tenant)
- Agenti (Agenti di monitoraggio)
- Nodi ed elemenenti interni (interfacce, dischi, servizi, ecc.) ( Elementi Monitorabili (dagli agenti) )
- Datagroup, datasource, condition e Timegraph. ( Raccolta dati e controlli )
![digraph sanetentities {
ximagepath="/opt/sanet3/static/webui/images/resources/";
node [fontsize="8"];
"tenant (site)" [ shape="box" ];
"agent (local)" [ shape="box" ];
"agent (remote)" [ shape="box" ];
"node1" [image="./source/_static/resources/node.png", shape=none, imagescale="true", fixedsize="true", width="1pt"];
"node2" [image="./source/_static/resources/node.png", shape=none, imagescale="true", fixedsize="true", width="1pt"];
"node3" [image="./source/_static/resources/node.png", shape=none, imagescale="true", fixedsize="true", width="1pt"];
interface [image="./source/_static/resources/iface.png" , shape=none, imagescale="true", fixedsize="true", width="1pt"];
storage [image="./source/_static/resources/storage.png", shape=none, imagescale="true", fixedsize="true", width="1pt"];
service [image="./source/_static/resources/service.png", shape=none, imagescale="true", fixedsize="true", width="1pt"];
device [image="./source/_static/resources/device.png" , shape=none, imagescale="true", fixedsize="true", width="1pt"];
subgraph datagroups {
datagroup2;
datagroup1;
}
"tenant (site)" -> "agent (local)";
"tenant (site)" -> "agent (remote)";
"agent (local)" -> "node1";
"agent (local)" -> "node2";
"agent (local)" -> "node3";
"node1" -> interface;
"node1" -> storage;
"node1" -> service;
"node1" -> device;
"node1" -> datagroup1;
datagroup1 -> datasource1;
datagroup1 -> condition1;
datagroup1 -> timegraph1;
interface -> "datagroup2";
datagroup2 -> datasource2;
datagroup2 -> condition2;
datagroup2 -> timegraph2;
}](../_images/graphviz-13b0856d605717ff5752965ec3e48387439e7282.png)
Tenant¶
E’ previsto che la stessa installazione di Sanet possa gestire una o piu’ configurazioni di monitoraggio completamente distinte e indipendenti.
Un’intera configurazione di monitoraggio (nodi, interfacce, controlli, dati da raccogliere, ecc…) e’ raggruppata logicamente in un Tenant.
Un tenant e’ caratterizzato dalle seguenti informazioni di base:
Attributo Descrizione Nome Nome identificativo del tenant. Deve essere univoco. Il nomer deve essere in LOWERCASE e puo’ contenere soltanto lettere o numeri (dopo almeno un carattere alfabetico) . Nome lungo Nome “verboso” puramente descrittivo Flag primario Flag vero/falso.
All’interno della stessa installazione i tenant sono completamente indipendenti e non condividono nessuna informazione/configurazione tra di loro (fatta eccezione per alcuni template speciali di configurazione).
Important
Se si organizza il monitoraggio in tenant multipli e si ha necessita’ di monitorare lo stesso host in due tenant, e’ obbligatorio duplicare le configurazioni su tutti e due i tenant.
Tenant primario (flag)¶
Tra tutti i tenant definiti deve esistere sempre un tenant in particolare, detto primario.
Il tenant primario viene scelto automaticamente durante le operazioni di configurazione ed utilizzato per mostrare i dati di monitoraggio via web quando non diversamente indicato dall’utente.
Note
Sanet effettua tutti i controlli necessari affinche’ esista sempre un tenant primario.
Tenant creato di default¶
In fase di installazione, Sanet crea automaticamente un tenant iniziale configurato come primario.
Se non specificato diversamente durante la fase di installazione il tenant verra’ chiamato “site”.
Rimozione di un tenant¶
Tramite i tool di amministrazione e’ possibile rimuovere un tenant dal sistema.
Warning
La rimozione di un tenant non effettua realmente la cancellazione dei dati (ne’ dal database ne’ su disco). Per rimuovere definitivamente tutti i dati bisogna procedere “manualmente” (erase-tenant)
Configurazione¶
- CLI: Vedere la sezione: Configurazione Tenant.
- WEB: Vedere la sezione: Tenant.
Agenti di monitoraggio¶
Come spiegato nel paragrafo Architettura, gli agenti (chiamati anche poller) sono le entita’ software (processi) che effettuano il monitoraggio della rete e comunicano i dati raccolti al server centrale di Sanet.
Per ogni tenant e’ possibile configurare piu’ di un agente di monitoraggio e distribuire il carico di lavoro tra i diversi agenti.
Gli agenti effettuano il monitoraggio delle entita’ assegnate loro in maniera completamente autonoma dagli altri agenti e non condividono informazioni tra di loro.
La granularita’ massima con cui e’ possibile suddividere il monitoraggio tra agenti e’ il nodo (Paragrafo Nodi)
Per monitorare un nodo attraverso un agente bisogna associare quel nodo all’agente.
E’ possibile configurare il monitoraggio per far gestire ad un agente solo alcuni nodi (ad esempio solo gli switch di rete), ed ad un altro agente altri nodi (solo i database server).
Important
Non si puo’ configurare esplicitamente e facilmente Sanet per monitorare parte di nodo con un agente e parte con un’altro (i controlli sulla RAM di un host con un agente e i controlli sui dischi con un altro agente).
Tipologie di agenti¶
- Esistono due tipi di agenti:
- locali
- remoti
Agenti locali¶
Gli agenti locali sono a tutti gli effetti processi che vengono eseguiti sul sistema (server) dove e’ stato installato Sanet.
Warning
Il numero di agenti locali che e’ possibile eseguire contemporaneamente sullo stesso sistema dipende dalle caratteristiche hardware/software della stessa.
Agenti remoti¶
Gli agenti remoti sono processi in esecuzione su macchine diverse (remote) da quella dove e’ installato Sanet.
Danger
E’ sconsigliato avere solo agenti remoti poiche’ sono processi in esecuzione remotamente e potrebbero risentire indirettamente di problemi
La gestione degli agenti remoti prevede alcuni accorgimenti. Per tutti i dettagli si rimanda alla sezione dedicata: Agenti remoti.
Agente primario¶
Tra tutti gli agenti definiti in un tenant esiste sempre un agente primario.
Note
Tutti i nodi monitorati all’interno di un tenant, se non specificato esplicitamente, vengono assegnati automaticamente all’agente primario nel momento in cui vengono creati.
Warning
E’ sconsigliato definire come primario un agente remoto. E’ opportuno avere sempre almeno un agente locale definito come primario in maniera che eventuali problemi di rete non blocchino completamente il monitoraggio della rete.
Parametri di configurazione di un agente¶
La configurazione di un agente prevede diversi parametri. La modifica di alcuni di questi parametri richiede il riavvio dell’agente (locale o remoto)
Parametro Descrizione Richiede riavvio dell’agente Flag primario Si/No. Indica se l’agente e’ l’agente primario del sistema. Flag attivo Si/No. Indica se l’agente e’ attivo o se e’ stato disabilitato dall’amministratore si Flag remoto Si/No. Indica al sistema se l’agente e’ considerato un agente locale/remoto. si Intervallo di update Intervallo di update per in secondi prima di ricaricare la configurazione per effettuare il monitoraggio si Numero Threads Numero di thread interni usati dall’agente per parallelizzare il monitoraggio si
Warning
Gli agenti non attivi non effettuano alcun tipo di operazione. Il monitoraggio delle risorse associate a quell’agente e’ completamente disabilitato.
Numero di thread¶
Tutti gli agenti effettuano il monitoraggio dei nodi assegnati loro cercando di parallelizzare il lavoro attraverso un thread pool di esecuzione.
E’ possibile indicare esplicitamente il numero di thread da utilizzare per ogni agente.
Note
Non si puo’ controllare in che modo gli agenti internamente parallelizzano il lavoro, ma e’ possibile obbligare un agente a rischedulare l’esecuzione di singoli controlli tramite appositi comandi (Comando: check_in).
Danger
Non c’e’ alcun limite al numero di thread che e’ possibile configurare per ogni agente, tuttavia la velocita’/prestazioni dell’agente non cresce linearmente col numero di thread. E’ bene impostare un numero di thread non superiore a 40 per iniziare ed aumentare gradualemente il numero finche’ le performance non sembrano subire un degrado.
Amministrazione agenti¶
Per amministrare ed interagire con gli agenti in esecuzione e’ necessario usare appositi comandi. Si rimanda alla sezione Strumenti di amministrazione: agentinfo.
Configurazione agenti¶
- CLI: si rimanda alla sezione: Configurazione Agenti.
- WEB: si rimanda alla sezione: Agenti.
Poiche’ gli agenti remoti prevedono una gestione/configurazione particolare, si rimanda alla sezione specifica: Agenti remoti.
Priorita’ logica dei controlli e livelli di priorita’¶
Ad ogni elemento del monitoraggio e’ associabile un livello di importanza chiamato priorita’.
La priorita’ e’ un valore numerico compreso tra 1 e 100 (compresi).
La priorita’ non serve ai fini del monitoraggio, ma viene utilizzata per scopo informativi e per facilitare la consultazione dei dati (via web o cli).
Note
Quando un elemento di monitoraggio non ha una priorita’ assegnata, si parla di priorita’ nulla o N/A
Warning
Il sistema utilizza valore 0 per codificare l’assenza di priorita’ (N/A), ma non e’ lecito ritenere questo valore rimarra’ tale in futuro. Non e’ consigliato implementare script o integrare Sanet con altri software assumendo che la priorita’ sia codificata con il valore 0.
Livelli di priorita’¶
All’interno di un tenant, la scala di priorita’ da 1 a 100 puo’ essere suddivisa logicamente in livelli (range) di priorita.
Ogni livello e’ caratterizzato da:
- Una etichetta (un nome).
- Una descrizione.
I livelli non sono sovrapponibili/intersecabili tra loro.
Esempio:
Etichetta Range Descrizione IGNORE 1-10 Allarme con priorita’ bassa NORMAL 11-30 Allarme CRITICAL 31-90 Allarme da segnalare subito FATAL 91-100 Problema critico per il sistema
Note
Questi “livelli” sono puramente informativi/descrittivi e non influenzano la gestione del monitoraggio. Possono eventualmente essere usati per facilitare la composizione di messaggi/allarmi.
Livelli di default¶
Se l’utente non configura dei livelli di priorita’, Sanet crea di default i seguenti livelli:
Etichetta Range Descrizione LOW 1 - 30 Priorita’ bassa MEDIUM 31 - 60 Priorita’ media CRITICAL 61 - 100 Priorita’ critica
Configurazione¶
- CLI: si rimanda alla sezione: Livelli priorita.
- WEB: si rimanda alla sezione: Livelli di priorita e priorita’ minima/critica.
Elementi Monitorabili (dagli agenti)¶
Esistono 5 tipologie di elementi che possono essere monitorati:
Nomi degli elementi¶
Tutti gli elementi di monitoraggio sono caratterizzati da un nome:
- Il nome dei nodi e’ univoco all’interno dello stesso tenant.
- Il nome di interfacce/storage/service/device e’ univoco all’interno dello stesso nodo. Due interfacce/dischi/device/ecc. non possono avere lo stesso nome all’interno dello stesso nodo. (es: eth0, root-disk, ecc.)
Warning
il nome di un elemento puo’ contenere SOLO un set di caratteri ben definito e deve rispettare il formato espresso dalla seguente espressione regolare:
^[a-zA-Z0-9]+([-.][a-zA-Z0-9]+)*$
Quali entita’ definire e monitorare¶
E’ bene tenere presente che, tecnicamente, e’ possibile definire un nodo e monitorare tutte le sue componenti interne (dischi/interfacce/ecc.) senza definirle esplicitamente nel monitoraggio.
Note
In pratica si definisce solo il nodo e si definisce almeno un controllo puntuale per ogni sotto elemento del nodo (Esempio: un controllo sul’interfaccia eth0, un controllo sul disco, ecc.)
Questo approccio e’ fortemente sconsigliato.
Note
Questo e’ anche il sistema utilizzato da altri sistemi di monitoraggio (Esempio: Nagios).
Il consiglio per chi usa Sanet e’ cercare di inserire nel sistema una configurazione granulare, esplicitando quando possibile, e compatibilmente con le proprie esigenze, tutte le entita’ monitorate per i seguenti motivi:
- Tutte le entita’ (nodi/interfacce/ecc.) sono caratterizzate da attributi specifici (e parametrizzabili) pensati per razionalizzare il piu’ possibile la configurazione.
- La definizione dei dati da raccogliere e dei controlli da eseguire su ogni entita’ monitorata risulta piu’ comprensibili e modulare.
- E’ piu’ facile consultare i dati raccolti.
Nodi¶
I nodi sono l’elemento principale di monitoraggio in Sanet.
Qualunque elemento sulla rete in grado di comunicare/rispondere tramite uno o piu’ protocolli di rete (piu’ o meno standard) e’ classificabile logicamente come un nodo. Alcuni esempi di elementi di rete che e’ possibile consideare come nodi in Sanet:
- PC e server di rete (reali o virtuali)
- switch, router, firewall
- NAS
- UPS
- Tablet/Cellulari
- Raspberry Pi
- ecc.
Note
Anche un processo in esecuzione su un server (apache) risponde a protocolli di rete, ma in questo caso si tratta di un entita’ software in esecuzione (su quello che si puo’ considerare come nodo) e per tanto dovrebbe essere monitorato attraverso un’apposita entita’ in Sanet (un service).
Note
I nodi sono le uniche entita’ del monitoraggio che possono contenere altre entita’ (dischi, interfacce, ecc.), ma non altri nodi.
Important
non e’ possibile configuarare esplicitamente alcune situazioni particolari. Ad esempio non si riesce ad esplicitare la relazione che esiste tra un server di virtualizzazione (nodo) e le macchine virtuali (nodi) che contiene.
Per i dettagli sui parametri di configurazione/monitoraggio si rimanda a: Monitoraggio dei nodi.
Interfacce¶
L’entita’ interfaccia rappresenta un’interfaccia (fisica o virtuale) presente su un nodo di rete.
Le interfacce vengono definite all’interno dei nodi (sono sotto-entita’ di un nodo) e sono identificate da un nome che deve essere univoco all’interno del nodo (es: eth0).
Per i dettagli sui parametri di configurazione/monitoraggio si rimanda a: Monitoraggio dei interfacce.
Interfacce e ifindex¶
L’ ifindex di una interfaccia e’ un valore (utilizzato principalmente nel protocollo SNMP) che serve per identificare dinamicamente un’interfaccia all’interno di un apparato di rete.
Sanet supporta un meccanismo per scoprire automaticamente questo valore e semplificare la scrittura di controlli basati sull’ifindex. Si rimanda alla sezione: Attributi Distinguisher, xform e valore ifIndex;
Important
Normalmente l’ifindex e’ un valore numerico, ma (purtroppo) esistono casi reali in cui non e’ cosi e per tanto Sanet gestisce l’ifindex come stringa.
Storage¶
Questa entita’ rappresenta genericamente uno storage all’interno di un nodo di rete:
- memoria RAM
- memoria ROM
- hardisk,
- memorie USB
- partizione montata via rete
- ecc.
Gli storage vengono definiti all’interno dei nodi (sono sotto-entita’ di un nodo) e sono identificati da un nome che deve essere univoco all’interno del nodo (es: root, C, netshared).
Per i dettagli sui parametri di configurazione/monitoraggio si rimanda a: Monitoraggio degli storage.
Storage e stindex¶
L’ stindex di uno storage e’ un valore (utilizzato nel protocollo SNMP) che serve per identificare dinamicamente uno storage all’interno di un apparato di rete.
Sanet supporta un meccanismo per scoprire automaticamente questo valore e semplificare la scrittura di controlli basati sull’stindex. Si rimanda alla sezione: Attributi Distinguisher, xform e valore stIndex;
Important
Normalmente l’stindex e’ un valore numerico, ma (purtroppo) esistono casi reali in cui non e’ cosi e per tanto Sanet gestisce l’stindex come stringa.
Servizi¶
Questa entita’ serve per rappresentare nel monitoraggio qualunque entita’ software, univocamente identificabile, presente (non necessariamente in esecuzione costante) su un nodo di rete.
- script BATCH per la produzione di dati.
- demoni di rete (inetd, apache, postfix, syslogd, ecc.).
- DB Manager.
- Broker di rete.
- Processi utente in esecuzione sulla macchina.
- Genericamente qualunque entita’ software composta da uno o piu’ programmi/script.
I servizi vengono definiti all’interno dei nodi (sono sotto-entita’ di un nodo) e sono identificati da un nome che deve essere univoco all’interno del nodo (es: apache, mysql, oracle, squid, ecc.).
Note
Il termine “servizio” e’ molto generico. Potrebbe trarre in inganno e far pensare che tramite una entita’ servizio si debba monitorare SOLO dei servizi complessi come “la posta” o lo “streaming video”.
In realta’ un servizio di posta completo coinvolge molte entita’ monitorabili (server POP, server IMAP, server SMTP, sistemi di storage, processi di logging, ecc…).
Spetta all’amministratore di Sanet decidere come sfruttare le risorse di tipo servizio di Sanet, quale sia il loro effettivo significato e quali sono effettivamente le entita’ reali sulla rete associate al quel servizio.
Per i dettagli sui parametri di configurazione/monitoraggio si rimanda a: Monitoraggio dei servizi.
Servizi e swrunindex¶
L’ SwRunIndex e’ un valore (utilizzato nel protocollo SNMP) che serve per identificare dinamicamente un processo in esecuzione su un server di rete che risponde a richieste SNMP.
Sanet supporta un meccanismo per scoprire automaticamente questo valore e semplificare la scrittura di controlli basati sull’SwRunIndex. Si rimanda alla sezione: Attributi Distinguisher, xform e valore swRunIndex;
Important
Normalmente l’SwRunIndex e’ un valore numerico, ma (purtroppo) esistono casi reali in cui non e’ cosi e per tanto Sanet gestisce l’SwRunIndex come stringa.
Dispositivi generici (device)¶
Qualunque dispositivo hardware presente all’interno di un server o apparato di rete, univocamente identificabile e monitorabile (attraverso protocolli di comunicazione o attraverso programmi esterni) e’ potenzialmente classificabile come device.
Alcuni esempio:
- Sensori (di qualunque tipo)
- Hardware interno (CPU, ventole, moduli, ecc..)
- Hardware esterno (es: Webcam attaccato tramite presa USB)
In Sanet gli elementi di tipo dispositivo (device) vengono definiti all’interno dei nodi (sono sotto-entita’ di un nodo) e sono identificati da un nome che deve essere univoco all’interno del nodo (es: fan0, usb-card-reader, printer1, ecc.).
Per i dettagli sui parametri di configurazione/monitoraggio si rimanda a: Monitoraggio di device generici.
Device e devindex¶
Alcuni apparati di rete espongono (via SNMP o altri protocolli) informazioni su dispositivi interni e spesso li identificano attraverso un valore univoco (tipicamente numerico).
Questo valore viene chiamato in Sanet devindex.
Sanet supporta meccanismo analoga a quello per il calcolo di ifindex, stindiex, ecc. per scoprire automaticamente il valore di devindex. Si rimanda alla sezione: Attributi Distinguisher, xform e valore swRunIndex;
Link tra interfacce¶
Un link rappresenta e’ un collegamento tra due interfacce. Tra due interfacce e’ possibile definire piu’ link.
Esistono 3 tipi di link:
Tipo Descrizione Fisico Rappresenta un collegamento tra due interfacce tramite cavi/fibre. Rete Rappresenta un collegamento non fisico. Virtuale Codifica un collegamento puramente virtuale definito per permettere controlli particolari in fase monitoraggio delle interfacce coinvolte.
Note
La differenza tra un link di “rete” e un link virtuale e’ che col primo si vuole identificare collegamenti tra interfacce che esistono ad un certo livello dello stack ISO/OSI, mentre il link virtuale e’ un’astrazione che potrebbe anche essere puramente logica e utile solo per esigenze di monitoraggio.
Attention
In Sanet puo’ essere definito un solo link fisico tra due interfacce, mentre possono essere definiti un numero arbitrario di link di rete o virtuali.
Attention
Il monitoraggio delle interfacce si basa esclusivamente (per il momento) sui link fisici. Link di rete e Virtuali sono ignorati al momento e non e’ possibile utilizzarli in nessun modo per implementare controlli specifici.
Nome di un link¶
Un link e’ caratterizzato da un nome “univoco”. Se non specificato, il sistema assegna automaticamente ai link un nome univoco componendolo a partire dai nodi/interfacce che coinvolge.
Per i dettagli sui parametri di configurazione/monitoraggio si rimanda a: Link tra nodi/interfacce.
Raccolta dati e controlli¶
Datagroup¶
Cos’e’ un datagroup¶
Per ogni entita’ monitorabile e’ necessario raccogliere dati logicamente collegati tra di loro e definire controlli su di essi. Ad esempio:
- CPU: Load average e percentuale di occupazione
- DISCO: spazio utilizzato/spazio totale
- TRAFFICO: traffico IN unicast/multicast/broadcast, traffico OUT unicast/multicast/broadcast.
- Servizio Email: numero email inviate/ricevute, percentuale di spam, ecc.
- Sensore di temperature: temperatura registrata in gradi.
Un gruppo di informazioni/controlli da monitorare insieme in un dato momento e’ rappresentato da un Datagroup.
Un datagroup codifica:
- Quali dati raccogliere dalla rete e come raccoglierli.
- Quali controlli effettuare sui dati raccolti.
- Con quale frequenza effettuare queste operazioni.
Come definire un datagroup¶
Per definire le varie parti di un datagroup, Sanet utilizza un sistema di configurazione basato su template chiamato datagroup template (che specifica il datagroup in ogni sua parte).
Ad ogni elemento del monitoraggio (nodo, interfaccia,ecc.) e’ possibile associare zero o piu’ datagroup template e questa associazione crea i datagroup.
Per i dettagli sul meccanismo di templating usato da Sanet si rimanda alla sezione dedicata: Template di Configurazione.
Gestione dei datagroup a parte degli agenti: Esecuzione¶
Il datagroup e’ l’entita’ atomica che gli agenti processano per effettuare le operazioni di rete.
Gli agenti periodicamente:
- caricano dal server centrale tutte le informazioni sulle entita’ da monitorare.
- caricano dal server centrale tutti i datagroup associati alle entita’ da monitorare.
- A intevalli regolari, utilizzano le informazioni contenute di ogni singolo datagroup per effettuare i controlli di rete e inviare i dati raccolti al server centrale.
Quando un agente decide di usare un datagroup per effettuare le operazioni di monitoraggio si dice che l’agente ESEGUE UN DATAGROUP.
Attributi di un datagroup e sotto-elementi di configurazione¶
Un datagroup possiede diversi attributi (opzioni di configurazione). Questa tabella riassume gli attributi specifici del datagroup:
Attributo Modificabile Opzionale Default Descrizione path no no Stringa mnemonica generata automaticamente dal sistema titolo si si Titolo che compare nelle descrizioni e nell’interfaccia web. minperiod si si 60 Pausa (in secondi) tra due esecuzioni dello stesso datagroup. timeout si si 3 Timeout di default (in secondi) utilizzato per effettuare le operazioni di rete. shorttries si si 5 Valore di default che indica il numero di tenatativi per effettuare una certa operazione di rete nel datagroup (un GET SNMP, un ping, ecc.) classification si si Stringa mnemnoica per cataloga il tipo di datagroup passive match si si Stringa per identificare un datagroup in un un controllo passivo dependson si si Stringa che codifica la catena di dipendenza del datagroup
Un datagroup e’ composto da i seguenti sotto-elementi:
Tipo Descrivono i dati che si vogliono raccogliere dalla rete, come devono essere raccolti e come devono essere salvati nel sistema. Parametri Variabili opzionali utilizzabili per rendere parametrizzabile la valutazioni di Datasource e Condition. Datasource Descrivono i dati che si vogliono raccogliere dalla rete, come devono essere raccolti e come devono essere salvati nel sistema. Condition Condizioni da verificare. Ogni condition e’ caratterizzata da diversi attributi che descrivono il controllo da eseguire. Timegraph Definizione per visualizzare grafici temporali dei dati raccolti (e storicizzati) dai DataSource.
Esempi di dati (datasource) e condizioni (condition)¶
- La raggiungibilita’ calcolata attraverso protocollo ICMP puo’ essere monitorata definendo un datagroup con:
- 4 datasource: rttmin, rrtmax, rttavg, pktloss (in percentuale)
- 1 condition: pktloss < 100%
- Il datagroup con tutte le informazioni STP di un’interfaccia potrebbe contenere:
- 1 datasource: numero transizioni di stato corrente
- 1 condition: varizione sul numero di transizioni rilevate rispetto al
- 1 condition: verifica adiacenza STP con l’interfaccia collegata
Titolo¶
Il titolo e’ una stringa descrittiva che viene visualizzata dall’interfaccia web.
E’ possibile utilizzare numerose variabili/wildcard per espandere automaticamente nel testo del titolo alcune informazioni sull’entita’ monitorata collegata al datagroup.
Tutte le variabili utilizzabili hanno come prefisso il carattere ‘$’.
L’elenco effettivo di variabili valide dipende dal tipo di risorsa (nodo, interfaccia, ecc.) a cui sara’ associato il datagroup.
Variabili usabili nel titolo di un datagroup/condition/datasource associato ad un nodo:
$node nome del nodo $snmpversion snmp version del nodo $community snmp community del nodo Tutti i parametri opzionali con $*parametro* Es. $threshold
Variabili usabili nel titolo di un datagroup/condition/datasource associato ad una interfaccia:
Variabile Descrizione $node nome del nodo $snmpversion snmp version del nodo $community snmp community del nodo $iface nome dell’interfaccia $instance distinguisher dell’interfaccia $linked_iface (interfaccia collegata con un link fisico) $linked_node (nodo dell’interfaccia collegata con un link fisico) Tutti i parametri opzionali con $*parametro* Es. $threshold
Variabili usabili nel titolo di un datagroup/condition/datasource associato ad uno Storage:
Variabile Descrizione Variabile Descrizione $node nome del nodo $snmpversion snmp version del nodo $community snmp community del nodo $storage nome dello storage $instance distinguisher dello storage Tutti i parametri opzionali con $*parametro* Es. $threshold
Variabili usabili nel titolo di un datagroup/condition/datasource associato ad un Service:
Variabile Descrizione $node nome del nodo $snmpversion snmp version del nodo $community snmp community del nodo $service nome del servizio $distinguisher distinguisher del servizio Tutti i parametri opzionali con $*parametro* Es. $threshold
Variabili usabili nel titolo di un datagroup/condition/datasource associato ad un Device:
Variabile Descrizione $node nome del nodo $snmpversion snmp version del nodo $community snmp community del nodo $device nome del device $distinguisher distinguisher del device Tutti i parametri opzionali con $*parametro* Es. $threshold
Path¶
Un datagroup (e anche i suoi datagroup/datasource) e’ identificato univocamente all’interno del tenant da una stringa chiamata path.
Il path* condifica implicitamente informazioni su:
- l’elemento (nodo) ed eventualmente il sotto-elemento (interfaccia,storage,service,device) a cui e’ associato.
- element-template di configurazione (si veda: Template di Configurazione);
- nome del datagroup
- nome datasource o nome della condition (per i path di datasource e condition).
La sintassi del path e’ la seguente:
Path Datagroup
<nome nodo> [ : <nome sub elemento> ] ; [ < element-template > ; ] <nome datagroup>
Path Datasource
<nome nodo> [ : <nome sub elemento> ] ; [ < element-template > ; ] <nome datagroup> : <nome datasource>
Path Condition
<nome nodo> [ : <nome sub elemento> ] ; [ < element-template > ; ] <nome datagroup> : <nome condition>
Esempi:
localhost;;icmp-reachability PATH datagroup
localhost:eth0;;iface-data:iferrs PATH datasource
Warning
il path e’ una stringa che dovrebbe restare opaca per l’utente e per software esterni. E’ preferibile evitare di basarsi su porzioni parziali del path per implementare elaborazioni ad hoc.
Periodicita’ dei controlli (minperiod) e scheduling¶
Ogni datagroup viene eseguito ad intervalli regolari.
L’intervallo di tempo MINIMO tra un’esecuzione e l’altra e’ chiamato minperiod e viene espresso in secondi.
Il valore di default per il minperiod e’ 60 secondi.
Attention
Il range di valori ammessi e’ compreso tra 0 to 32767 secondi, pari circa a 9 ore.
E’ possibile configurare Sanet per gestire uno scheduling piu’ sofisticato, e non solo basato sul minperiod. Si veda la sezione XXXXXXXXXXXXXXXXXXXX.
Datagroup passivi (non schedulati)¶
Se il minperiod e’ valorizzato a 0, il datagroup non viene mai schedulato e viene definito passivo.
E’ possibile eseguire un datagroup passivamente attraverso meccanismi come le Trap SNMP ( Trap SNMP ) o eventi push ( Eventi “Push” ).
Minperiod/frequenza e carico del sistema¶
Piu’ il minperiod e’ basso, piu’ e’ alta la frequenza con cui viene eseguito un datagroup.
Il carico di elaborazione per il sistema e’ direttamente proporzionale alla numero totale di datagroup ed alla loro frequenza di esecuzione.
Attention
Il sistema non impedisce di mettere minperiod piu’ bassi di 60 secondi, tuttavia e’ altamente sconsigliato scendere sotto i 15 secondi.
E’ possibile configurare Sanet per gestire uno scheduling piu’ sofisticato, e non solo basato sul minperiod. Si veda la sezione XXXXXXXXXXXXXXXXXXXX.
Timeout delle operazioni (timeout)¶
Nel 90% dei casi un datagroup deve raccogliere dati dalla rete. Per evitare di attendere indefinitivamente il completamento di una operazione (es: un ping) ogni datagroup puo’ specificare un valore di timeout in secondi.
Il valore specificato viene considerato come il timeout di default del datagroup. Ogni singola operazione eseguita dal datagroup puo’ decidere se utilizzare questo valore, ignorarlo o utilizzare questo dato per calcolare un timeout diverso.
Il default e’ 5 secondi.
Attention
non tutte le funzioni/operazioni eseguibili da sanet tengono conto di questo valore.
Numero di tenativi per operazione (shorttries)¶
Per ogni datagroup si puo’ specificare quante volte “tentare” una singola operazione di raccolta dati (es: un ping, un GET SNMP, una connect). Questo valore e’ chiamato shorttries.
Il valore di default e’ 3.
Attention
non tutte le funzioni/operazioni eseguibili da sanet tengono conto di questo valore.
Passive match¶
L’attributo passive match e’ una stringa utilizzata nel meccanismo di esecuzione dei datagroup passivi e serve per discriminare quali datagroup passivi (tra tutti i datagroup di una risorsa monitorata) devono essere eseguiti allo scatenarsi di un evento (Si veda Datagroup passivi (non schedulati)).
Ad ogni evento esterno puo’ essere associato un identificativo in formato stringa che viene confrontato con il passive match.
La stringa di match contenuta in passive match puo’ avere due formati:
- Stringa di caratteri semplice.
Vengono gestiti dal datagroup tutti gli eventi il cui identificativo corrisponde esattamente alla stringa specificata.
- Stringa con prefisso regex: :
La stringa dopo il prefisso viene interpretata come regular expression. Vengono gestiti dal datagroup tutti gli eventi il cui identificatvio fa match con la regular expression
Esempi:
Passive match Identificativo evento Risultato event12345 event12345 Datagroup passivo ESEGUITO event12345 event345 Datagroup passivo NON ESEGUITO regex:^event event345 Datagroup passivo ESEGUITO
I Datagroup passivi vengono impiegati per implementare la gestione di trap snmp (vedi Trap SNMP ) ed eventi push (vedi Eventi “Push” ).
Classificazione di datagroup/datasource/condition (classification)¶
Due o piu’ datagroup diversi potrebbero raccogliere dati logicamente simili.
Due o piu’ datasource potrebbero raccogliere lo stesso dato, ma con meccanismi diversi.
Due o piu’ condition potrebbero effettuare lo stesso controllo logico, ma con parametri diversi.
Ad esempio, due datagroup progettati per effettuare il controllo della memoria possono avere nomi diversi, ma effettuare logicamente lo stesso tipo di operazioni.
Per poter confrontare in maniera automatica i valori che vengono raccolti dai datasource, i controlli effettuati dalle condition e gli eventuali allarmi che seguono e’ necessario introdurre il concetto di classificazione.
La classificazione serve per idenditificare il contenuto semantico dei dati del monitoraggio.
La classificazione e’ una stringa mnemonica abitraria che si puo’ specificare per ogni datagroup/datasource/condition.
Anche se non formalmente obbligatorio, una classificazione e’ definita da una stringa di caratteri composta da “token” separati da “.”.
Ogni “token” e’ una stringa che codifica il nome di un nodo all’interno di uno namespace gerarchico.
Esempi di stringhe di classificazione:
servizi.principali.posta
servizi.secondari.marcatempo
rete.apparati.switch
rete.apparati.switch.
rete.apparati.router.hp
rete.apparati.router.cisco
rete.apparati.wireless.accesspoint
Concettualmente, la classificazione e’ logicamente gerarchica ed e’ rappresentabile con un albero. Il meccanismo di codifica e’ virtualmente analogo a quello delle OID (o dei package java, dei namespace C#, ecc.).
Si rimanda alle appendici Classificazioni per avere un elenco delle classificazioni possibili gia’ utilizzabili internamente per i controlli base di Sanet3.
Attention
datagroup, condition e datasource sono tutti classificati indipendentemente. Non esiste nessun meccanismo automatico di assegnamento di classificazioni.
Dipendenze tra datagroup (dependson)¶
Il sistema permette di definire relazioni di dipendenza tra datagroup. Questo permette di eseguire un particolare datagroup solo se la valutazione della condition di un altro datagroup e’ avvenuta con successo.
- Esempio: il datagroup per la raccolta dei dati relativi al servizio web “Apache” in esecuzione sul nodo “server1”, deve essere eseguito solo se la condizione
- che verifica la raggiungibilita ICMP (contenuta in un datagroup che raccoglie dati sulla raggiungibilita’ ICMP) del nodo ha verificato che il nodo sia effettivamente raggiungibile via rete.
La gestione delle dipendenze e’ gestita in automatico dal sistema, ma e’ possibile intervenire manualmente.
Si rimanda alla sezione Condition primary e dependson per maggiori dettagli.
I Datasource¶
Un datasource rappresenta il singolo dato di interesse per il monitoraggio raccolto/calcolato analizzando lo stato di un componente della rete.
Il valore calcolato da un datasource puo’ essere:
- numerico (intero o virgola mobile)
- stringa di caratteri ascii o byte
- valore complesso
Il valore calcolato da un datasource puo’ essere storicizzato da Sanet.
Important
il valore calcolato per un datasource viene storicizzato SOLO se numerico (intero o in virgola mobile).
Il valore di un datasource puo’ essere:
- raccolto singolarmente (un singolo valore raccolto via SNMP)
- essere il risultato di un’aggregazione di piu’ valori raccolti (es: a + b + c) e/o di altri datasource (dello stesso datagroup) calcolati/raccolti (immediatamente) prima di lui.
Proprieta’ di un datasource:
Dato Opzionale Default Descrizione expr si Espressione da valutare che indica come raccogliere/calcoalre il valore. Vedi Espressione e valore di un datasource. min val si Valore minimo consentito. Questa propieta’ non altera il dato raccolto, ma serve per fornire indicazioni sulla validita’ o meno del dato raccolto. max val si Valore massimo consentito. Questa propieta’ non altera il dato raccolto, ma serve per fornire indicazioni sulla validita’ o meno del dato raccolto. absolute value si si Flag SI/NO. Vedi Tipi di datasource: GAUGE o RATE (COUNTER). save value si si Indica se il valore calcolato deve essere salvato dal sistema o se scartato al termine dell’elaborzione del datagroup. order si Ordine di valutazione del datasource rispetto agli altri. Default 0. Vedi Ordine di valutazione di datasource e condition. cascade si no (flag si/no) Indica se, in caso di errore nella valutazione, i datasource successivi devono essere valutati o meno. (default no) classification si Stringa di classificazione storage-spec si Attributo per specificare parametri di configurazioni specifici del backend di storicizzazione dei dati. Vedi DataSource Storage Backends.
Tipi di datasource: GAUGE o RATE (COUNTER)¶
Il parametro absolute value serve per indicare in che modo salvare e storicizzare il valore di un datasource.
I due valori possibili sono:
- SI: il valore raccolto viene storicizzato come valore puntuale. Si parla in questo caso di valore GAUGE.
- NO: il valore raccolto viene storicizzato sotto forma di rate al secondo. Il sistema effettua automaticamente il calcolo del delta tra il valore corrente del datasource e il valore precedentemente calcolato. Si parla in questo caso di valore COUNTER.
Esempi di dati da raccogliere e quale tipo di datasource usare:
Dato Natura del dato absolute value numero utenti loggati valore puntuale si spazio disco occupato e spazio disco totale valore puntuale si Rtt min, max, avg, % packet loss valore puntuale si CPU %, Load Average valore puntuale si Traffico interfaccia (bit/s) rate no STP Topology change/s rate no
Important
il parametro absolute value altera significativamente le strutture dati utilizzate per storicizzare i dati su disco. Una volta che il sistema ha iniziato a raccogliere i dati di un datasource, ogni modifica al parametro absolute value e’ possibile, ma non produce alcun effetto nel sistema. Sono possibili alcune operazioni sui dati salvati di un datasource per “resettare” un datasource dopo modifiche al valore absolute value, ma fortemente sconsigliata.
Espressione e valore di un datasource¶
Il valore raccolto da un datasource viene calcolato valutando l’espressione (expr) associata al datasource.
L’espressione deve essere definita utilizzando un particolare linguaggio funzionale. In questo linguaggio si possono funzioni e variabili ricalcolate da Sanet ad ogni esecuzione dell’espressione.
Si rimanda alla sezioni Expression Language e SANET built-in expression symbols per maggiori dettagli sulla sintassi del linguaggio utilizzato dall’espressione.
Per altri dettagli sulla valutazione della expr si rimanda alla sezione Regole di valutazione di Datasource e Condition.
Precisione dei dati storicizzati¶
I dati storicizzati per ogni datasource vengono processati prima di essere memorizzati/storicizzati da Sanet.
Note
attualemente i dati vengono storicizzati tramite RRDTools, quindi file RRD.
Questo implica due cose:
- Esiste un lieve margine di approssimazione tra i dati raccolti e quelli effettivamente storicizzati da Sanet.
- Lo scostamento tra i dati raccolti e quelli effettivamente mostrati da Sanet e’ piu’ evidente per datasource GAUGE, mentre lo e’ meno per i datasource rate/COUNTER.
Modalita’ di calcolo del rate attuale¶
Per rate attuale si intende l’ultimo rate calcolato da Sanet per un datasource COUNTER.
Sanet mantiene due valori di rate attuale:
- rate istantaneo : Calcolato dagli agenti di monitoraggio in fase di raccolta dei dati. Questo valore e’ piu’ grezzo.
- rate storicizzato: Calcolato da sanet in fase di storicizzazione del dato nel database. Questo valore tende ad essere piu’ mediato e quindi puo’ nascondere anomalie (picchi nel rate) in alcuni casi.
Warning
Questi due valori sono SEMPRE DIVERSI e non e’ predicibile lo scostamento che potrebbero avere.
Warning
nei grafici mostrati da interfaccia Web viene sempre mostrato il rate storicizzato. Il rate istantaneo viene mostrato solo in alcune sezioni dell’interfaccia, per completezza.
Stato di un datasource¶
Dopo che un datasource viene eseguito, il sistema calcola uno stato che rappresenta l’esisto della valutazione. Questi sono gli stati possibili:
STATO Descrizione OK Il valore e’ stato calcolato correttamente. STRANGE VAL Il valore attuale (puntuale o rate al secondo) del datasource non rispetta il range (min_val, max_val) indicato in configurazione. CASCADE Il valor non e’ stato calcolato poiche’ un datasource calcolato prima di questo ha dato errore bloccando l’esecuzione dei successivi. Vedi Ordine di valutazione di datasource e condition. DEPENDSON Tutto il datagroup associato non e’ stato calcolato perche’ dipende da una condition non verificata. Vedi Ordine di valutazione di datasource e condition. UNCHECKABLE Il valore del datasource non e’ stato calcolato correttamente per un errore rilevato durante la raccolta dei dati
Datasource con valori fuori range (STRANGE VAL) e storicizzazione¶
Quando un datasource e’ in stato STRANGE VAL significa che:
- Il valore letto dalla rete non e’ numerico. In questo caso il dato non viene storicizzato.
- Il valore letto e’ fuori dal range min val / max val. In questo caso il dato viene storicizzato, ma in fase di estrazione, il dato viene scartato e considerato nullo.
Le Condition¶
Rappresenta il controllo puntuale di una condizione (invariante), effettuato sui dati raccolti dalla rete.
I dati raccolti possono essere valori calcolati dai datasource o raccolti direttamente dalla rete.
Una condition e’ caratterizzata dai seguenti attributi:
Parametri informativi
Dato Opzionale Default Descrizione classification si Classificazione priorita’ si n/a Livello di proprita’ di questa condizione. Parametri di Valutazione
Dato Opzionale Default Descrizione expr si Espressione da valutare per la verifica della condizione max tries si 3 numero di check da ripetere prima di considearre la condizione come non verificata primary si no questa condizione e’ da considerare come la condizione principale per il datagroup. Tutte le altre condizioni non vengono elaborate se questa non e’ verificata. La condizione primaria e’ sempre verificata per prima rispetto alle altre. dependson si La valutazione di questa condizione e’ subordinata alla condition specificata. order si 0 Specifica l’ordine di esecuzione delle condition all’interno del datagroup. Subordinato al flag “primary”. cascade si no Se la condition non e’ verificata, tutte le condition valutate successivamente non vengono eseguite. uncheckable-fallback si “UP” o “DN”. Indica se considerare verificata o non verificata una condition quand uncheckable. statuschange-action si Script eseguito ogni volta che avviene un cambio di stato della condition. Vedi Esecuzione di script automatica con variazioni di stato. Parametri per gli allarmi:
Dato Opzionale Default Descrizione upemail si Recipient per gli allarmi di stato UP. Vedi Generazione allarmi e transizioni di stato da UP e DOWN. si Recipient per gli allarmi DOWN (e UP se upemail non e’ valorizzato). Vedi Generazione allarmi e transizioni di stato da UP e DOWN. msg_downsubj si Soggetto per allarmi DOWN. Vedi Generazione allarmi e transizioni di stato da UP e DOWN. msg_downbody si Corpo messaggio allarmi DOWN. Vedi Generazione allarmi e transizioni di stato da UP e DOWN. msg_upsubj si Soggetto per allarmi UP. Vedi Generazione allarmi e transizioni di stato da UP e DOWN. msg_upbody si Corpo messaggio allarmi UP. Vedi Generazione allarmi e transizioni di stato da UP e DOWN.
Espressione e valore di una condition¶
La expr di una condition e’ una espressione per calcolare un valore vero o falso.
Quando il valore di una espressione non puo’ essere calcolato (per un timeout di rete, un errore di sintassi, ecc.) si dice che l’esisto della valutazione di una condition e’ uncheckable.
Si rimanda alla sezioni Expression Language e SANET built-in expression symbols per maggiori dettagli sul linguaggio valido per l’espressione.
Per altri dettagli sulla valutazione della expr si rimanda alla sezione Regole di valutazione di Datasource e Condition.
Condition primary e dependson¶
Quando una condition e’ flaggata come primary il sistema fa dipendere da questa tutte le altre condition dello stesso datagroup e tutti gli altri datagroup associati direttamente all’elemento.
E’ possibile avere una sola condition primary per nodo (elemento di monitoraggio).
I sotto elementi interfacce/storage/servizi/dischi possono avere anche loro una condition primary. In questo caso il sistema crea una catena di dipendenze:
condition primary del nodo
^ ^ ^
| | |
| | `------------- condition dello stesso datagroup
| |
| |
| `-------------------- altri datagroup del nodo
|
|
condition primary del sotto elemento
^ ^
| |
| `------------- condition dello stesso datagroup
|
|
`-------------------- datagroup del sotto elemento
Condition primary, ordine di esecuzione e cascade¶
L’attributo order permette di specificare in quale ordine vengono valutate le condition di uno stesso datagroup.
La condition primary viene sempre e comunque eseguita prima di tutte le altre, indipendentemente, dal valore dell’attributo order.
Quando una condition ha l’attributo cascade impostato a True, se non e’ verificata (valore False) oppure non e’ valutabile (uncheckable) tutte le condition valuate successivamente (con order uguale o maggiore), non vengono eseguite e vanno in stato Depenson (vedi _condition-states:).
Stato di una condition¶
Dopo che una condition viene controllata, il suo stato viene deciso in base al valore restituito dalla sua expr:
- valore true : condition verificata
- valore false : condition non verificata
- errore: condition uncheckable
Questi sono tutti gli stati possibili:
CODICE Titolo Descrizione DN Down Controllo non verificato (tries = max-tries) FA Failing Controllo non verificato (tries < max-tries) UP Up Controllo verificato IN Suspended Stato sospeso DU Depenson UP Controllo dipendente da altro controllo sospeso/uncheckable/down (stato precedente UP) DD Depenson DOWN Controllo dipendente da altro controllo sospeso/uncheckable/down (stato precedente DN) UU Uncheckable UP Controllo non verificabile per errori di rete/timeout/ecc. (stato precedete UP) UD Uncheckable DOWN Controllo non verificabile per errori di rete/timeout/ecc. (stato precedete DN)
Schema delle transizioni di stato possibili:
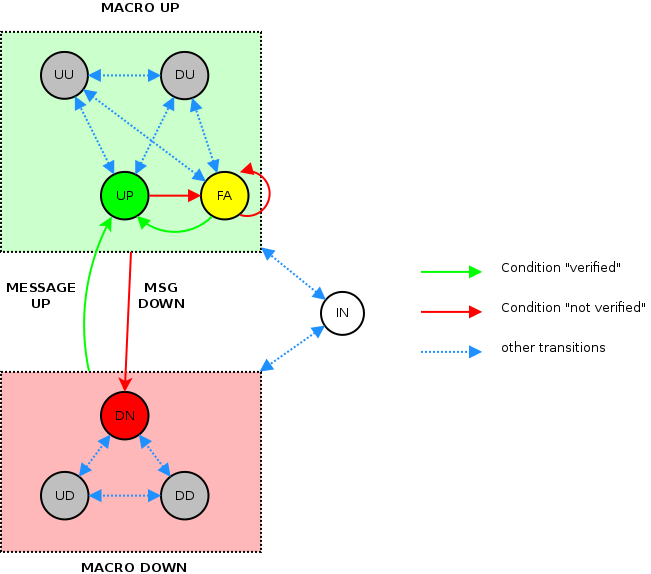
Note
Le transizioni, all’interno del MACRO STATO UP, da e verso lo stato FA (Failing) sono leggermente semplificate.
Note
Lo stato suspended (IN) puo’ essere raggiunto da un qualsiasi degli altri stati. Gli stati uncheckable (UU, DU, UD, DD)
Generazione allarmi e transizioni di stato da UP e DOWN¶
Per semplificare la gestione delle transizioni che generano allarmi, gli stati di una condition sono raggruppati in MACRO STATI chiamati MACRO UP e MACRO DOWN (lo stato SOSPESO e’ uno stato a parte).
Sanet genera allarmi quando lo stato di una condition passa da un qualunque stato appartenente al macro stato UP a qualunque stato appartenente al macro stato DOWN o viceversa.
CODICE Nome MACRO STATO UP Up UP UU Uncheckable UP UP DU DependsON UP UP FA Failing UP DN Down DOWN DD DependsON DOWN DOWN UD Uncheckable DOWN DOWN IN Sospeso SOSPESO
Lo stato UNCHECKABLE (UN)¶
Per semplificazione, quando lo stato di una condition e’ uno qualunque di questi, la condition e’ considerata virtualmente UNCHECKABLE (UN):
- Uncheckable UP (UU)
- Dependson UP (DU)
- Uncheckable DOWN (UD)
- Dependson DOWN (DD)
Important
Questa semplificazione e’ puramente concettuale, in virtu’ del fatto che se una condition si trova in un uno di questi stati, significa la sua valutazione non e’ stata verificata con certezza (timeout, errori di rete, errori nella expr, ecc.), al contrario di quando si trova in stato UP, DOWN, FA o SOSPESO.
Ultima variazione significativa¶
Alcune variazioni di stato intermedie di una condition potrebbero essere cosi’ frequenti da essere poco significative.
Sanet tiene traccia di quella che viene definita l’ultima variazione significativa.
Una variaizone di stato e’ significativa quando lo stato di una condition passa da uno stato MACRO UP , MACRO DOWN o Sospeso.
In particolare Sanet ricorda:
- L’orario dell’ultima variazione significava
- Lo stato precedente al momento dell’ultima variazione significativa.
Important
la data di ultimo cambiamento di stato o la data dell’ultima variazione sono visualizzate in diversi punti dell’interfaccia grafica, alcuni regolabili da configurazione utente.
Uncheckable fallback¶
Quando la valutazione di una condition non e’ possibile (per errori di rete, timetout, ecc.), l’esito della valutazione e’ considerato uncheckable (non verificabile).
Quanto l’esito e’ uncheckable, lo stato assegnato di una condition puo’ passare a Uncheckable UP (UU) o Uncheckable DOWN (UD), a seconda dello stato precedente (vedi schema nel paragrafo Stato di una condition).
Il parametro uncheckable-fallback serve ad indicare se la condition deve essere considerata verificata o non verificata se la valutazione della condition e’ uncheckable.
Warning
Non confondere esito della valutazione (verificato/non verificato) con stato della condition.
I valori ammessi sono:
- UP - Considera la condition come verificata.
- DN - Considera la conditonn come non verficata.
Esempio
Ipotizziamo di avere una condition in stato UP.
Sanet valuta la condition e calcola come esito della valutazione il valore uncheckable.
Se il parametro uncheckable fallback non e’ impostato:
- Lo stato della condition passa da UP a Uncheckable UP (UU).
Se il parametro uncheckable fallback e’ impostato a UP:
- La condition viene considerata come verificata.
- Lo stato della condition resta in UP.
Se il parametro uncheckable fallback e’ impostato a DN:
- La condition viene considerata come non verificata.
- Lo stato della condition passa da UP a FA o DN (a seconda del parametro max-tries).
Messaggi di allarme¶
Quando Sanet deve generare un allarme in seguito ad DOWN (o UP) di una condition, utilizza i dati di configurazione della condition per produrre un messaggio composto da:
- destinatario (indirizzo email/alias valido)
- soggetto
- corpo del messaggio
I valori di questi parametri vengono specificati attraverso specificati dai campi di testo:
- upemail e email
- msg_upsubj e msg_upbody
- msg_downsubj e msg_downbody
Il testo dei campi msg_upsubj, msg_upbody, msg_downsubj, msg_downbody possono contenere wildcard speciali per aggiungere automaticamente al testo informazioni di sistema.
Si rimanda alla sezione Gestione Messaggi/Allarmi.
Esecuzione di script automatica con variazioni di stato¶
Il parametro statuschange-action e’ una stringa che permette di specificare uno programma/script esterno da eseguire ogni volta che una condition cambia di stato.
La stringa deve contenere il path del programma/script esterno da eseguire seguito da eventuali parametri di esecuzione.
Esempi di stringe valide:
action1.shaction1.sh -t 10 -p "param with spaceses"/usr/local/action1.sh -t 10 -p "param with spaceses"
Il path del programma/script da eseguire puo’ essere:
- Assoluto:
- Esempio: /usr/share/scripts/action.sh
- Relativo:
- Lo script verra’ cercato all’interno della directory specificata dal parametro di configurazione SANETD_EXEC_DIR
- Esempio:
action2.shh -> {{SANETD_EXEC_DIR}}/action2.sh
- Esempio:
prova/action1.sh -> {{SANETD_EXEC_DIR}}/prova/action1.sh
Important
di default SANETD_EXEC_DIR punta alla directory {{VAR_DIR}}/_action_scripts. Questa directory non viene creata automaticamente.
Warning
il programma/script esterno viene eseguito con i permessi del processo del server di Sanet (root)
Action UUID¶
Ad ogni esecuzione di script esterni Sanet associat un UUID univoco generato al momento dell’esecuzione.
Questo permette di identificare univocamente ogni singola esecuzione.
Passare dati di “input” al processo esterno¶
E’ possibile passare dati al processo da eseguire in due modi:
- Parametri a riga di comando
- Variabili d’ambiente
Parametri a riga di comando¶
Sono specificati insieme al path del programma nella stringa statuschange-action.
action1.sh -t 10 -p "param with spaceses" ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Il primo parametro dei parametri a riga di comando ($0 per le shell) contiene il path completo del programma/script eseguito.
Variabili di ambiente¶
Sono variabili create da Sanet nel contesto di esecuzione del processo ed hanno il prefisso SANET_.
Queste sono le variabili d’ambiente disponibili:
Variabile d’ambiente Descrizione SANET_ACTION_UUID UUID univoco di esecuzione SANET_TENANT_NAME Nome del tenant SANET_TENANT_UUID UUID del tenant SANET_NODE_UUID UUID del nodo associato alla condition SANET_NODE_NAME Nome del nodo associato alla condition SANET_ELEMENT_UUID UUID dell’elemento di monitoraggio associato alla condition SANET_ELEMENT_NAME Nome dell’elemento di monitoraggio associato alla condition SANET_CONDITION_UUID UUID della condition SANET_CONDITION_PATH Path della condition SANET_CONDITION_LASTCHANGE Timestamp con la variazione di stato della condition SANET_CONDITION_NEW_STATE Stato corrente della condition SANET_CONDITION_OLD_STATE Stato precedente della condition
Modalita’ di esecuzione dello script¶
Il programma/script esterno viene eseguito da server principale come processo parallelo ed assolutamente indipendente.
Warning
Il server centrale non controlla/attende la terminazione del processo eseguito prima di elaborare altri dati.
Warning
Lo stesso script potrebbe essere eseguito piu’ volte in parallelo. Problemi di concorrenza devono essere gestiti dallo script.
Warning
Il processo esterno e’ indipendente e la sua esecuzione non si interrompe anche se il server di Sanet viene fermato/ravviato.
Output del processo esterno¶
Il processo esterno viene eseguito come demone e per tanto il suo stdout e stderr non sono collegati a nessuno stream (file).
Se il processo esterno deve produrre dati in output deve utilizzare le funzioni di shell o altre api per salvare questi dati:
- logger (syslog)
- cat, echo, tee, ecc.
Regole di valutazione di Datasource e Condition¶
Valutazione di una expr¶
La valutazione di una expr di una condition o di un datasource avviene sempre seguendo le stesse regole.
A seconda che si stia valutando la expr di una condition o di un datasource possono cambiare i simboli (variabili $foo) utilizzabili che Sanet prepara al momento dell’esecuzione. Si rimanda alla sezione SANET built-in expression symbols.
La valutazione di expr puo’ restiture due tipi di risultati:
- un valore null o None (risultato UNCHECKABLE)
- un qualunque valore numero intero, numeroi virgola mobile, stringa di byte o booleano (vero/falso)
Quando si parla di expr di una condition, la valutazione dell’espressione si considera verificata se il valore prodotto e’:
- diverso da null
- numerico <> 0
- stringa di byte diversa da stringa vuota (‘’)
- true (booleano)
Valori correnti e valori precedenti¶
A volte e’ necessario effettuare dei controlli confrontando dati / valori (calcolati e/o letti via rete) al momento dell’esecuzione con gli stessi dati/valori calcolati al check precedente.
Sanet distingue due tipi di valori al momento dell’esecuzione:
- correnti : sono i dati calcolati al momento del check (OID SNMP, valori prodotti da chiamate a funzione, ecc.)
- precedenti (o old): sono i dati calcolati/raccolti dalla expr durante check precedente.
Quando Sanet valuta una espressione, i valori correnti che sono stati calcolati con successo (ovvero senza errori che causano lo stato uncheckable), vengono salvati in attesa del check successivo. Al check successivo verranno considerati valori precedenti.
Note
Quando una expr contiene il riferimento a valori precedenti e viene eseguita per la prima volta, l’espressione viene eseguita ma l’esito della valutazione produce un valore nullo, ovvero UNCHECKABLE.
Esempio:
sanet-manage exec_expr phink0 '1.3.6.1.2.1.1.1.0#'
VALUE: None
INFOS:
Warning
se una expr referenzia (in qualche modo) solo valori precedenti senza referenziare/produrre anche valori correnti, l’esisto della valutazione sara’ perennemente UNCHECKABLE.
Esistono tre modi per poter utilizzare valori correnti/precedenti nelle expr di Sanet:
Tempo trascorso dall’ultimo check valido (non UNCHECKABLE) e simbolo $delta¶
Quando la expr di un datagroup viene valutata con successo Sanet memorizza:
- l’istante temporale dell’ultimo check valido.
- il valore associato all’ultimo check valido.
Puo’ essere utile valutare quanto tempo e’ passato dall’ultima volta che una espressione e’ stata calcola senza errori e usare questa informazione come parametro aggiuntivo per effettuare un controllo.
All’interno di una expr il simbolo $delta memorizza il tempo trascorso dall’ultimo check avvenuto con successo. Il valore e’ memorizzato in secondi in virgola mobile (es. 1.3 secondi, 0.003 secondi, ecc.)
Questo e’ uno schema di come viene calcolato il parametro $delta al momento del check in base all’esito del check precedente.
1 2 3 4 5 6
TEMPO ----|---------|----------|----------|----------|-----------|------------> secondi
CHECK OK UNCHECK UNCHECK UNCHECK OK ...
expr
$delta |----1----|
|----------2---------|
|-----------------3-------------|
|---------------------4--------------------|
|-----1-----|
Parametro $delta e calcolo rate istantaneo¶
I datasource di tipo COUNTER utilizzano il valore del parametro $delta e il valore precedente per calcolare il rate istantaneo.
Important
il rate istantaneo calcolato dopo una valutazione UNCHECKABLE puo’ essere molto impreciso in virtu’ della logica di aggiornamento del $delta e del valore precedente descritta nel paragrafo precedente.
Esempio: sequenza di valutazioni di un datasource COUNTER:
1 2 3 4 5 6
TEMPO ----|-------|--------|--------|--------|---------|-----> secondi
check expr
(valore corrente) 1 5 8 UNCHECK 10 11
$delta n/a 1 1 1 2 1
valore precedente n/a 1 5 8 8 10
rate istantaneo n/a 4/s 3/s 3/s(*) 1/s 1/s (*) rate non aggiornato
(new-old)/$delta
Sub-espression SNMP¶
Sanet implementa un meccanismo build-in per gestire i valori correnti/precedenti letti dalla rete attraverso SNMP.
Per sfruttare questo meccanismo bisogna utilizzare una sintassi particolare nelle expr.
<OID expr> @ Valore corrente (letto via rete)
<OID expr> # Valore precedente
Esempio:
1.3.6.1.2.1.1.1.0@
1.3.6.1.2.1.1.1.0#
Per i dettagli sulle regole di composizione delle espressioni SNMP si rimanda alla sezione: SNMP Sub-expressions.
Funzioni Speciali¶
Esistono funzioni che permettono di calcolare un valore al momento di un check e utilizzare quel valore al check successivo.
Ad esempio:
- saveval e getlastval.
- exec.
- …
Si rimanda all’elenco completo SANET standard expression functions.
Valori Datasource¶
Il valore calcolato di un datasource o il valore precedente di un datasource puo’ essere utilizzato nelle expr usando la seguente sintassi:
{ <nome> @ } Valore del datasource calcolato dal sistema al momento di check del datagroup.
{ <nome> # } Valore del datasource check precedente del datagroup.
Danger
Assicuratevi di non referenziare entrambi i valori nella stessa expr del datasource stesso. Esempio:
{ds1@} + {ds2@}
Important
Bisogna fare attenzione all’ordine di esecuzione dei datasource e condition altrimenti si rischia di referenziare valori non ancora calcolati.
Tempo di esecuzione di datasource e condition¶
E’ possibile sapere e utilizzare il tempo di check di una condition o di un datasource utilizzando la seguente sintassi:
{ <nome>.checktotaltime @ } Tempo di elaborazione
{ <nome>.checktotaltime # } Tempo di elaborazione al check precedente
Important
Bisogna fare attenzione all’ordine di esecuzione dei datasource e condition altrimenti si rischia di referenziare valori non ancora calcolati.
Danger
Se un datagroup contiene un datasource e una condition con lo stesso nome ci possono essere dei problemi di incoerenza con i valori effettivamente utilizzati.
Valori dei datasource usati nelle expr¶
All’interno di un datagroup, una condition puo’ (ma non obbligatoriamente) verificare una condizione basandosi su:
- Un valore raccolto raccolto/calcolato dalle rete (es: valore traffico in input su una interfaccia raccolto via protocollo SNMP)
- il valore corrente di uno o piu’ datasource del medesimo datagroup.
Schema:
DATAGROUP
|
+----------+----------+--------+-------+----------+-----------+
| | | | | |
ds1 ds2 ds3 c1 c2 c3
| | ^ | ^ || | |
| | `--------+ `-------------+| | |
| | | | |
GET script.sh GET GET GET
SNMP SNMP SNMP SNMP
Ordine di valutazione di datasource e condition¶
Quando viene valutato un datagroup (non e’ sospeso), l’ordine di valutazione e’ stabilito nel seguente modo:
- Step 0: verifica se la condition da cui dipende questo datagroup e’ verificata o meno (vedi Condition primary e dependson).
- Step 1: Calcola tutti i datasource ordinati in base al loro attributo “order”
- Se un datasource non e’ verificato ed e’ l’attributo cascade e’ true, viene interrotta la valutazione di tutti i datasource successivi.
- Step 2: Verifica tutte le condition
- Viene valutta la condition primaria.
- Se la condition primaria non e’ verificata, tutte le condition successive non vengono valutate e passano in stato dependson (Up o Down in base al loro stato attuale).
- Vengon valutate le condition non primarie (l’ordine non e’ predefinito).
Important
Se all’interno del datagroup sono presenti piu’ condition primarie, non e’ predicibile quale verra’ valutata per prima e quali saranno le altre condition (anche primarie) a passare in stato dependson.
Parametri opzionali¶
I parametri opzionali permettono di definire variabili utilizzabili nel calcolo delle espressioni (attribugo expr) di datasource e condition.
Ogni parametro e’ definito tre attributi:
nome: stringa che identifica il parametro. All’interno di un datagroup il nome e’ univoco.
tipo: indica il tipo di parametro. Esistono i seguenti tipi di parametri:
- numero: numero (in virgola mobile)
- stringa: sequenza di caratteri
- boolean: valore booleano vero o falso
I parametri nelle espressioni¶
Ogni parametro viene richiamato all’interno delle espressioni di datasource e condition utilizzando la seguente sintassi:
$<nome>
Esempio: Se in un datagroup e’ definito il parametro url, in una espressione (di datasource o condition) viene utilizzato cosi:
urlContentMatches( $url )
Se una espressione richiama un parametro non definito nel datagroup, la valutazione dell’espressione viene interrotta e il valore dell’espressione e’ uncheckable.
Timegraph¶
I timegraph permettono di creare grafici temporali utilizzando serie di dati (ma non necessariamente) calcolate sui valori dei datasource di un datagroup.
Un timegraph viene rappresentato utilizzando un piano con due assi ortogonali: l’asse delle ascisse (orizzontale) rappresenta il tempo, mentre l’asse delle ordinate (verticale) rappresenta i valori delle serie definite.
E’ possibile define un numero illimitato di timegraph in un datagroup.
Ogni timegraph e’ caratterizzato dai seguenti attributi:
Attributo Default Descrizione name Nome del timegraph (deve essere univoco all’internod el datagroup) title Titolo descrittivo del timegraph primary no Flag che indica se il timegraph e’ un timegraph primario (vedi sotto) stacked si Indica se il timegraph puo’ ylegend Stringa usata per indicare l’unita’ di misura dell’asse delle ordinate. classification (facoltativo) Permette di indicare una classificazione per il timegraph
Timegraph primario¶
Quando un timegraph ha il flag primary attivo (valore si o true) il timegraph e’ detto timegraph primario.
Quando viene visualizzata la pagina web di un elemento (nodo, interfaccia, disco, servizio, device) il sistema individua il timegraph primario e lo visualizza all’internod ella pagina.
Note
Il sistema non controlla se piu’ di un timegraph appartenenti allo stesso elemento e’ impostato come primario. Se piu’ di un timegraph e’ definito come primario, il sistema scegliera’ uno qualunque di questi e lo visualizzera nella pagina web.
Serie¶
Per poter visualizzare dei dati in un timegraph e’ necessario definire le sue serie dati.
Una serie indica quali dati (valori temporali) rappresentare e come devono essere rappresentate (colore, descrizione, ecc.)
I valori di una serie possono essere calcolati utilizzando i valori temporali di un datasource o i valori di altre serie dello stesso timegraph.
Gli attributi di una serie sono:
Timegraph Default Descrizione name Nome della serie (deve essere univoco) legend Descrizione usata per la leggenda color (facoltativo) Stringa con la codifica del colore style Stile grafico per rappresentare la serie render order (facoltativo) Numero progressivo l’ordine di visualizzazione della serie nel grafico variable value Nome del datasource da cui ricavare i dati computed value expr Espressione per calcolare i valori della serie usando le altre serie dati
Codifica dei Colori
Per indicare il colore di una serie bisogna usare la seguente sintassi:
#<codifica esadecimale RGB>
Esempi:
#ff0000 Rosso #00ff00 Verde #0000ff Blue #ffff00 Giallo #ffffff Bianco #000000 Nero
Stili
Sono definiti i seguenti stili per una serie:
Stile Descrizione line La serie viene rappresentata da una linea (continua) area La serie viene rapppresentata da una area colorata limitata superiormente dai valori della serie. tick Vengono visualizzate delle linee verticali in corrispondenza dei valori della serie > 0 invisible La serie e’ definita ma non viene visualizzata (nemmeno la leggenda)
Serie da datasource o calcolate¶
Come gia’ detto nei paragrafi precendenti, i valori di una serie possono essere calcolati:
- utilizzando i valori temporali di un datasource dello stesso datagroup. In questo caso sono chiamate serie normali.
- utilizzando i valori di altre serie dello stesso timegraph. In questo caso sono chiamate serie calcolate.
Esempio di serie normale: Se nel datagroup e’ definito il datasouce rttmax, per usarlo nella serie e’ sufficiente indicare come valore dell’attributo variable value:
rttmax
Esempio di serie calcolata: Se nel timegraph sono definite due serie chiamate rttmax_serie e rttmin_serie:
sqrt( avg(rttmax_serie, rttmin_serie) + 3.14 )
Note
Quando in un timegraph sono indicate serie di entrambi i tipi, prima vengono calcolate tutte le serie normali e poi tutte le serie calcolate.
Note
Se il sistema non e’ in grado di calcolare un valore per una serie calcolata per un preciso istante temporale (asse x), il valore calcolato e’ nullo e non viene rappresentato nel grafico.
La sintassi per comporre le espressioni di serie calcolate e’ simile a quella di qualunque funzione matematica. L’espressione puo’ contenere:
- numeri
- operatori matematici: + , -, *, / , ec
- funzioni: f(…), sin(….), max( … ), iftrue( … )
- variabili: stringhe di testo che rappresentano un valore.
Esistono due tipi di variabili:
- variabili che si riferiscono a serie
- variabili speciali o built-in ricalcolate ogni volta che deve essere calcolato un singolo valore della serie.
Per maggiori dettagli come vengono calcolate le serie calcolate e su quali funzioni e quali variabili sono utilizzabili si rimanda alla sezione Timegraphs.
Sospensione e Riattivazione di un datagroup¶
La valutazione dei datagroup (di una qualunque entita’ monitorata) puo’ essere sospesa. Esistono due tipi di sospensioni:
- provvisoria: si deve indicare la timeline oltre la quale viene riattivato il monitoraggio del datagroup
- permanente: il monitoraggio del datagroup deve essere riabilitato manualmente.
Con la definizione sospendere un nodo si intende dire che si sospendono tutti i datagroup associati al nodo e alle sue sotto-entita’.
Configurazione avanzata dello scheduling¶
Scheduling di base (best effort)¶
Quando non specificato diversamente, i datagroup vengono schedulati per essere eseguiti ogni minperiod.
Esiste sempre un lieve overhead di elaborazione per cui l’istante di scheduling non corrisponde esattamente all’istante di inizio elaborazione.
Una volta che un agente di monitoraggio termina di elaborare (esegue) un datagroup, viene ri-schedulato calcolando l’istante temporale ( next time ) usando la semplice formula:
next_time = now + minperiod
Esempio: Datagroup con minperiod di 60 secondi (nota: nel grafico viene evidenziato il ritardo di esecuzione rispetto allo scheduled time)

Questo sistema di scheduling e’ il sistema di default.
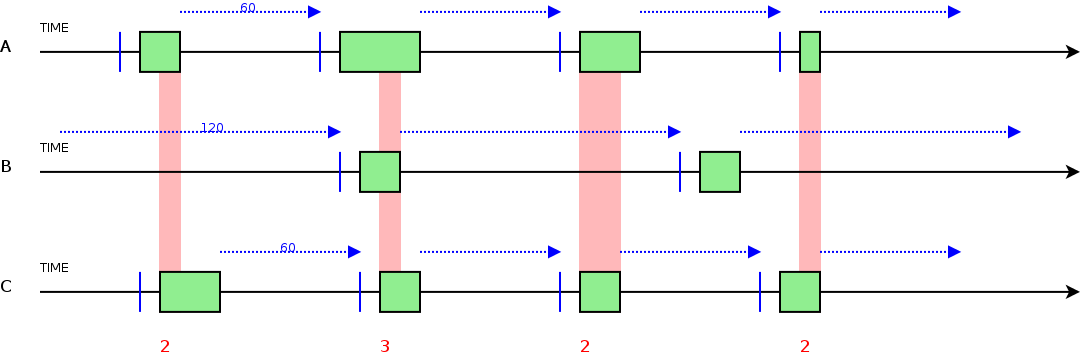
Questo sistema e’ molto semplice da configurare, ma presenta il seguente problema: diversi datagroup per uno stesso nodo/cluster possono essere eseguiti nello stesso istante in parallelo causando aumento di carico sul nodo target.
Esempio: Nel seguente schema indichiamo la sequenza temporale di elaborazione di 3 datagroup (A,B,C) con tre minperiod diversi. Si possono notare dei momenti di esecuzione concorrente.
Scheduling avanzato: gestione di Scheduling Group¶
Uno scheduling group rappresenta logicamente un gruppo di datagroup che devono essere schedulati cercando di rispettare vincoli temporali precisi.
Esistono tre tipi di scheduling group che Sanet e’ in grado di gestire e si distinguono dal modo con cui vengono configurati:
- Specificare parametri di scheduling a livello di elemento di monitoraggio (a livello di nodo, o singolo sotto-elemento)
- In questo caso si dice che lo scheduling group e’ definito implicitamente a livello di elemento.
- Specificare parametri di scheduling a livello di cluster.
- In questo caso lo scheduling group e’ definito implicitamente a livello di cluster.
- Definire uno scheduling group ed assegnare singoli datagroup (anche di nodi diversi) o elementi di monitoraggio allo scheduling group.
- In questo caso la configurazione dello scheduling group e’ comune a tutti gli elementi esplicitamente assegnati allo scheduling group.
Important
La gestione dello scheduling per ogni scheduling group ignora completamente l’elemento di appartenenza del datagroup. E’ possibile configurare il sistema per gestire i datagroup (tutti o solo alcuni) di un nodo tramite uno scheduling group (esplicito o implicito) ed assegnare comunque i datagroup dei sotto-elementi ad altri scheduling group (impliciti o espliciti).
Parametri di scheduling¶
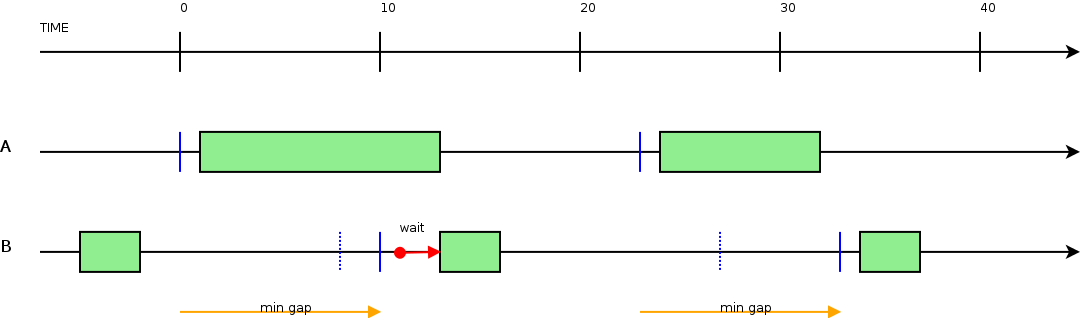
min-gap¶
Il min-gap inidica la distanza minima (in secondi) che deve esistere in fase di scheduling (NON DI ESECUZIONE) tra due datagroup dello stesso scheduling group.
Specificare il valore 0 significa schedulare i datagroup uno dietro l’altro senza alcun gap aggiuntivo.
Esempio: Gruppo di due datagorup in un gruppo con min-gap impostato (10 secondi).
Note
In pratica, il min-gap serve per regolare il rate di datagroup da eseguire nel tempo.
Warning
Poiche’ il min-gap viene utilizzato per calcolare il momento di scheduling successivo, da solo non evita l’esecuzione in parallelo di datagroup dello stesso gruppo. Vedi max-parallel.
max-parallel¶
Il tempo massimo di esecuzione di un datagroup non e’ mai certo e potrebbe capitare che l’esecuzione di due datagroup di uno stesso gruppo (anche se schedulati in istanti temporali diversi in base al min-gap) si sovrapponga,
Il parametro max-parallel serve per obbligare il sistema a limitare il numero massimo di datagroup lanciati in esecuzione contemporaneamente.
Quando arriva il momento (scheduled time) di eseguire un datagroup appartenente ad un gruppo, se e’ gia’ stato raggiunto il limite indicato max-parallel, l’agente di monitoraggio mette in attesa (accorda) il datagroup finche’ un qualunque altro datagroup dello stesso gruppo non termina l’esecuzione.
Al termine dell’esecuzione del datagroup corrente, il sistema controlla la coda di esecuzione e verifica quanti datagroup in attesa lanciare.
Specificare il valore 1 significa impedire l’esecuzione in parallelo di due datagroup dello stesso gruppo.
Note
Il numero massimo di datagroup eseguiti in parallelo da un agente e’ pari al numero di thread configurati per l’agente. E’ inutile configurare max-parallel con un numero superiore al numero di thread per agente.
Warning
Impostare un valore per max-parallel potrebbe causare una attesa eccessivamente lunga per i datagroup pendenti. Per forzare comunque lo “sblocco” di piu’ datagroup pendenti si puo’ configurare max-deadline.
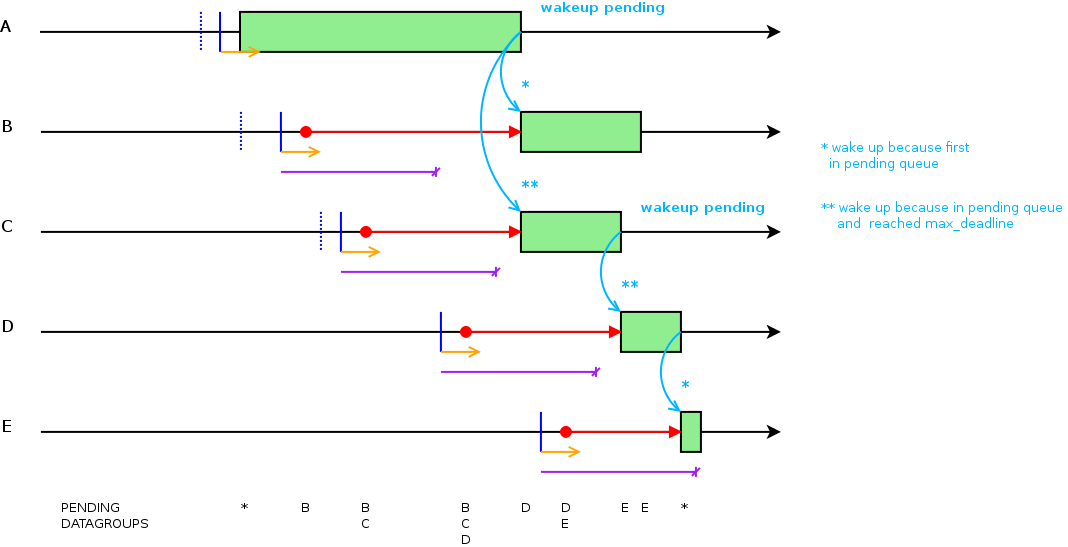
max-deadline¶
Numero massimo di secondi oltre il quale non e’ comunque possibile tenere in attesa un datagroup bloccato all’interno di un gruppo ( a causa del parametro max-parallel ) rispetto all’istante di scheduling.
Warning
configurand max-deadline il sistema potrebbe eseguire comunque in parallelo alcuni datagroup dello stesso gruppo.
Esempio 2: Esecuzione con min-gap (linea gialla) e max-deadline (linea viola) configurati. Come si puo’ vedere, in fase di wakeup dei datagroup in pending, max-deadline forza comunque l’esecuzione del datagroup B e anche di C poiche’ il max-deadline di C e’ stato superato.
Calcolo del momento di scheduling: min_period e min_gap¶
Quando un datagroup termina la sua esecuzione, il sistema deve calcolare il prossimo momento di esecuzione.
Il sistema cerca di schedulare il datagroup partendo dal suo min-period.
Se l’istante di scheduling calcolato e’ troppo vicino (min_gap) ad quello di un altro datagroup dello stesso gruppo, il tempo viene aumentato fino a trovare un istante temporale che non crei sovrapposizioni.
Warning
il parametro max-deadline non viene MAI considerato in questa fase (scheduling), ma solo nella fase di esecuzione o sblocco.
Esempio:
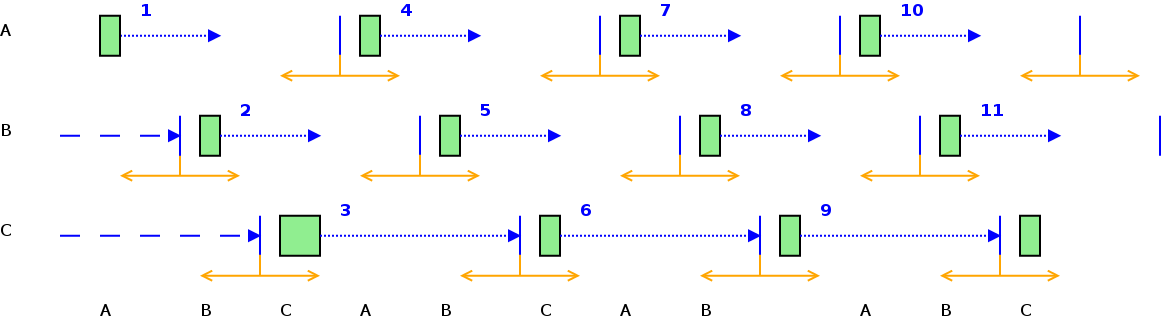
Parametri di scheduling a livello di agente¶
È possibile definire una configurazione di scheduling generale per ogni agente di monitoraggio.
Tutti i controlli dei nodi associati da un agente verranno gestiti applicando i parametri di scheduling impostati per quell’agente, solo se:
- non e’ gia’ presente una parametrizzazione di scheduling più specifica nel cluster a cui il nodo appartiene.
- non e’ gia’ presente una parametrizzazione di scheduling più specifica per il singolo nodo/sotto-elemento/datagroup.
I parametri di scheduling configurati a livello di agente utilizzati per creare automaticamente dei “gruppi di scheduling” nel seguente modo:
- Tutti i controlli (datagroup) di tutti i nodi appartenenti ad uno stesso cluster vengono raggruppati e schedulati insieme nello stesso gruppo (gruppo automatico del cluster).
- Tutti i controlli di nodo non appartenente a nessun cluster, vengono raggruppati e schedulati insieme (gruppo automatico del nodo).
Scheduling iniziale (avvio dell’agente)¶
Se sono stati configurati parametri di scheduling, all’avvio l’agente organizza temporalmente i controlli coerentemente ai parametri specificati.
In particolare tutti I controlli di un “gruppo di scheduling” vengono schedulati/intervallati rispettando il min_gap del gruppo.
Configurazione¶
- Configurazione da CLI: Scheduling Group.
Template di Configurazione¶
Datagroup template¶
Un datagroup-template permette di specificare il valore di tutti i parametri di configurazione che un datagroup dovra’ avere.
Il datagroup-template definisce:
- Gli attributi/campi del datagroup
- i datasource e tutti i loro attributi/campi
- le condition e tutti i loro attributi/campi
- i parametri opzionali
- i timegraph e tutti i loro attributi/campi e le serie
Nome di un datagroup-template¶
Ogni datagroup-template e’ identificato da un nome univoco.
Il nome di un datagroup-template deve rispettare la seguente espressione regolare:
^[a-zA-Z0-9][a-zA-Z0-9-_]*$
Gerarchia di template¶
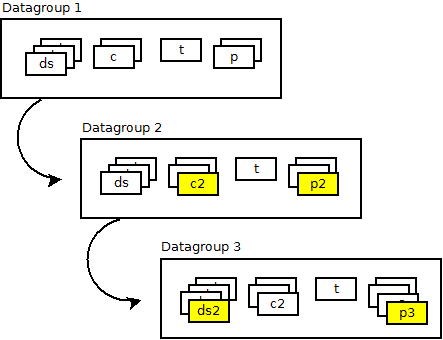
E’ possibile creare un datagroup-template a partire da un datagroup-template gia’ definito; in questo caso il primo e’ chiamato datagroup-template figlio, mentre il secondo e’ chiamato datagroup-template padre.
Quando un datagroup-template viene definitio a partire da un datagroup-template esistente e’ possibile:
- sovrascrivere il valore di uno degli attributi del datagroup-template.
- sovrascrivere il valore degli attributi dei datasource/condition/timegraph/parametro gia’ esistente.
- aggiungere nuovi datasource/condition/timegraph/parametro a quelli gia’ definiti.
Esempio di gerarchia e modifica di attributi:
Attributo “deleted”¶
Il sistema di eriditarieta’ e’ di tipo additivo, ovvero e’ possibile SOLO aggiungere nuovi elementi (condition/datasource/ecc.) ad un datagroup-template che si sta estendendo.
Puo’ succedere che un determinato datagroup-template non sia applicabile esattamente ed interamente ad un elemento monitorabile. Alcuni datasource o condition potrebbero non avere senso o non essere applicabili (perche’ l’apparto non implementa alcune MIB SNMP, ecc.).
Poiche’ non si puo’ definire un datagroup-template con l’intenzione di togliere attributi/sotto-elementi, si puo’ risolvere il problema in due modi:
- Definire un datagroup-template nuovo che non definisce i datasource/condition non applicabili.
- Estendere un datagroup-template gia’ esistente marcando alcune sotto-entita’ come deleted.
Quando una condition/datasource/ecc. e’ marcato come deleted viene semplicemente ignorato dal monitoraggio.
Configurazione¶
- CLI: si rimanda alla sezione: Datagroup Template
- WEB: La configurazione via web dei template non e’ disponibile.
Configurazioen locale e Library¶
I datagroup-template si possono dividere in due tipologie:
- locali : sono definiti solo in un particolare tenant.
- library : sono definiti globalmente nel sistema e sono utilizzabili in tutti i tenant.
I datagroup-template della library sono indentificati univocamente dal nome in tutta l’installazione.
I datagroup-template definiti nel tenant sono identificati dal nome che e’ univoco solo all’interno del tenant. Due tenant diversi possono definire datagroup-template locali con lo stesso nome, ma completamente diversi.
I datagroup-template locali ad un tenant possono estendere/sovrascrivere i datagroup-template nella “library”, ma non viceversa.
Important
Ogni volta che in un tenant si vuole estendere un datagroup-template definito in “library”, il sistema crea automaticamente nel tenant un datagroup-template “locale” con lo stesso nome che eredita quello definito nella library.
Important
Il sistema non permette di creare datagroup-template “locali” con lo stesso nome di datagroup-template nella “library”.
Important
La definizione di datagroup-template nella library ha senso se si intendere “riutilizzare” lo stesso datagroup-template in tenant diversi o in altre installazioni, ma e’ possibile configurare un intero sistema senza utilizzare la library. E’ una scelta possibile. Spetta all’amministratore del sistema decidere cosa deve o non deve essere memorizzato nella library.
Configurazione¶
- CLI: si rimanda alla sezione: Configurazione Library
- WEB: La configurazione via web dei template non e’ disponibile.
Assegnare un datagroup-template ad un elemento di monitoraggio¶
Quando associo un datagroup-template ad un elemento di monitoraggio(nodo, interfaccia, ecc.), sto creando una istanza di quel template, ovvero sto creando un datagroup.
Ogni datagroup (istanza di un datagroup datagroup-template) ha un nome che puo’ essere:
- un nome uguale a quello del datagroup-template corrispondente.
- un nome personalizzato.
Per ogni elemento di monitoraggio, il nome dei datagroup istanziati deve essere univoco.
Note
Ci puo’ essere un solo datagroup con nome uguale a quello del suo datagroup-template; altri datagroup istanziati dallo stesso datagroup-template dovranno specificare per forza un nome personalizzato.
E’ possibile istanziare (associare) un datagroup-template in un elemento di monitoraggio in due modi:
- associare direttamente il datagroup-template all’elemento di monitoraggio: Datagroup diretti.
- Utilizzare un element template: Element template.
Datagroup diretti¶
I datagroup template associati direttamente ad elementi di monitoraggio creano i datagroup diretti.
I datagroup diretti possono essere personalizzati modificando i singoli attributi del datagroup o i parametri opzionali.
Important
non e’ possibile aggiungere definizione di datasource/condition/timegraph ad un datagroup.
Configurazione¶
- CLI: Si rimanda alla sezione: Datagroup diretti.
- WEB: non disponibile
Element template¶
Un element template permette di specificare un blocco di configurazione che deve essere applicata in elememento di monitoraggio.
E’ possibile create element template per ogni tipologia di elemento monitorabile:
- node template
- interface template
- storage template
- service template
- device template
Un element template permette di specificare:
un elenco di datagroup da creare automaticamente per elemento di monitoraggio, indicato quali datagroup-template assegnare e con quale nome. Vedi Datagroup all’interno di un elemente template.
parametri di configurazione specifici per la tipologia di entita’ corrispondente al template (flags, xform, distinguisher, ecc.)
un elenco di sotto-elementi (interfacce, dischi, servizi, device) che devono essere creati automaticamente in fase di assegnamento del template all’elemento di monitoraggio.
- Questo e’ possibile solo per i node template. Vedi Sotto-elementi all’interno di un node-template.
E’ possibile associare piu’ di un element template alla stessa entita’ di monitoraggio.
Important
Eventuali conflitti verranno segnalati e/o impediti: (A) a datagroup con lo stesso nome definiti in due element template associati alla stessa entita; (B) conflitti tra nomi di sub-entita’ definite nei nodi o in node-template gia’ applicati.
Datagroup all’interno di un elemente template¶
All’interno di un element template ogni datagroup da creare viene specificato indicando il datagroup template e facoltativamente, il nome con cui istanziarlo (per evitare nomi duplicati invalidi)
datagroup-template element-template +-------------------+ | | +-----------+ | +-----------+ | | ta |---------+----------->| ta | | +-----------+ | | +-----------+ | | | | | | +-----------+ | +----------->| ta2 | | | +-----------+ | | | +-----------+ | +-----------+ | | tb | -------------------->| tb | | +-----------+ | +-----------+ | | | +-------------------+
Per ogni datagroup specificato e’ possibile svorascrivere i parametri di configurazione previsti dal datagroup-template (datasource, condition, parametri opzionali).
Note
non e’ possibile aggiungere nuovi datasource/datagroup/timegraph ad un datagroup all’interno di un element template.
In questo schema riassumiamo lo schema di ereditarieta’/associazione di datagroup-template agli elementi di monitoraggio:
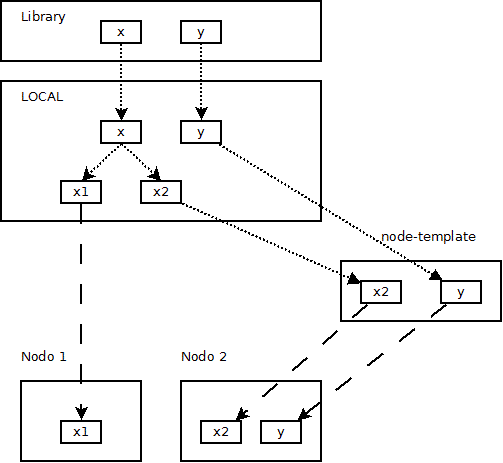
Applicare template multipli¶
E’ possibile applicare piu’ di un element template allo stesso elemento di monitoraggio.
Important
se due element template dichiarano di utilizzare lo stesso datagroup template, e vengono applicati alla stessa entita’, il sistema crea due datagroup distinti e non effettua alcun controllo sulla presenza di due due datagroup simili nella configurazione generata.
Node template¶
I node template permettono di specificare (oltre ad un elento di datagroup-template) alcuni attributi specifici del nodo:
- flag swtich
- flag router
Si rimanda alla sezione Monitoraggio dei nodi per dettagli sul siggnificato di questi due flag.
Sotto-elementi all’interno di un node-template¶
All’interno di un node-template e’ possibile specificare quali entita’ devono essere automaticamente create quando il template viene applicato al nodo.
E’ possibile specificare uno o piu’ sotto-elementi per ogni tipologia di entita’ di monitoraggio che e’ possibile definire dentro ad un nodo:
- interfacce
- storage
- service
- device
Per ogni sotto-elemento che si vuole specificare all’interno di un node template, e’ possibile specificare:
- nome dell’entita
- distinguisher
- xform
- uno o piu’ element template da applicare all’entita’ creata.
Important
non e’ possibile specificare per le sotto entita’ dei datagroup singoli o personalizzare i parametri dei datagroup template associati agli element template indicati, ma e’ possibile cambiare le parametrizzazioni per ogni elemento a livello di configurazione di nodo.
Warning
il sistema impedisce che si creino conflitti tra i nomi delle entita’ create automaticamente in base alla definizione di un template applicato ad almeno un nodo ed i nomi delle entita’ create manualmente all’interno di quel nodo. I comandi di configurazione che generano conflitti verrano annullati con un errore.
Configurazioni specifiche dei sotto-elementi definiti nei node-template¶
La configurazione di elementi generati in base alla definizione specificata in un node-template puo’ essere modificata:
- aggiungendo il riferimento ad altri element template direttamente all’oggetto del monitoraggio.
- aggiungendo altri datagroup-template diretti all’oggetto del monitoraggio.
Configurazione¶
- CLI: si rimanda alla sezione: Element Template
- WEB: La configurazione via web dei template non e’ disponibile.
Configurazione di datagroup template, element template ed elementi¶
Come descritto nei paragrafi precedenti, un datagroup template puo’ essere istanziato partendo da un datagroup template in due modi:
- Associando il datagroup template direttamente all’elemento di monitoraggio (datagroup diretti).
- Associando il datagroup template ad un element template.
E’ possibile configurare praticamente tutti i campi (di datasource/condition/timegraph/serie) o parametri opzionali di un datagroup in un qualunque punto di questa cascata di configurazione*:
- A livello di datagroup template (1)
- A livello di elemente template (2)
- A livello di datagroup istanziato per un elemento (4)
+-----+ +-----+
| dg1 | | dg2 | min-period=60 DATAGROUP 1
+-----+ +-----+ TEMPLATES
. .
----.------------------.----------------------------------------------------
. .
. . Node ELEMENT 2
. .Template TEMPLATES
. +-.---------+
. | +-------+ |
. | | dg2 | | min-period=120
. | +-------+ |
. +-----.-----+
. . .
----.--------------.-------.------------------------------------------
. . . ELEMENTS 3
. +------+ .
. | Nodo | .
. +------+ .
. / \ .
----.---/----------\-------.------------------------------------------
. / \ .. DATAGROUPS 4
. / \ .
[ dg1 ] [ dg2 ] min-period=30
I livelli piu’ bassi della catena sovrascrivono i livelli piu’ alti, quindi un campo configurato a livello di datagroup sovrascrive qualunque parametrizzazione fatta a livello di datagroup-template o elemente-template.
Configurazione della priorita’¶
La priorita’ di una condition e’ un caso un po’ particolare di campo configurabile.
E’ possibile assegnare una priorita’ (priorita’ di default) ANCHE ad ogni elemento di monitoraggio (nodo, interfaccia, ecc.).
In assenza di parametrizzazioni a livello di singolo datagroup (istanza), vale (se impostata) la priorita’ impostata per l’elemento. In assenza di priorita’ a livello di elemento vale la priorita’ configurata a livello di element template o datagroup template.
La priorita’ di default specificata per sub-elementi (interfacce, dischi, ecc.) sovrascrive la priorita’ di default del nodo padre (se specificata).
+-----+ +-----+
| dg1 | priority=1 | dg2 | priority=n/a DATAGROUP 1
+-----+ +-----+ TEMPLATES
. .
----.------------------.----------------------------------------------------
. .
. . Node ELEMENT 2
. .Template TEMPLATES
. +-.---------+
. | +-------+ |
. | | dg2 | | min-period=120
. | +-------+ |
. +-----.-----+
. . .
----.--------------.-------.------------------------------------------
. . . ELEMENTS 3
. +------+ .
. | Nodo | . priority=30
. +------+ .
. / \ .
----.---/----------\-------.------------------------------------------
. / \ .. DATAGROUPS 4
. / \ .
[ dg1 ] [ dg2 ]
p = 30 p = 30
Best practice¶
Poiche’ la gestione delle configurazioni tramite template e’ gerarchica e basata su un meccanismo di ereditarieta’, le operazioni di aggiornamento/modifca possono essere costose in termini di tempo/CPU.
E’ opportuno seguire le seguenti regole:
- Se si sta creando un nuovo datagroup-template e si vuole testare il suo funzionamento e’ VIVAMENTE CONSIGLIATO di associare il datagroup direttamente ad UN SOLO elemento di monitoraggio e provarlo.
- Evitare, se possibile, di cancellare/aggiungere datasource/condition/timegraph a datagroup-template gia’ esistente e associato a molti elementi di monitoraggio.
- Non reimpotare la library interamente da file, ma importare solo i datagroup template mancanti.